使用python爬虫对网上公开免费代理网站进行爬取,组件自己的代理池进行代理上网
先找到某公开免费代理网站
 程序思路非常清晰明确,直接放到爬虫代码里,就不单独介绍
程序思路非常清晰明确,直接放到爬虫代码里,就不单独介绍
编写程序脚本进行捕获源码和清洗
import requests
from selenium import webdriver
import re
import parsel
url = 'https://www.xxxxx.com/free/' #应审核要求网站打码......
c_o = webdriver.ChromeOptions()
c_o.add_argument('--headless')
browser = webdriver.Chrome(options=c_o) #设置无界面爬取选项
browser.get(url)
data = browser.page_source#获取源码
#print(data)
yu_ming = '<td data-title="IP">(.*?)</td>' #网页源码中用非贪婪匹筛选出IP
yuming = re.findall(yu_ming, data, re.S)
print(yuming)
duan_kou = '<td data-title="PORT">(.*?)</td>'#同上筛选出端口
duankou = re.findall(duan_kou, data, re.S)
print(duankou)
for IP, PORT in zip(yuming, duankou):
#print(IP,':',PORT)
proxy = IP + ':' + PORT
proxies_dict = {
#将IP和端口以http和https拼合一起
"http://":"http://"+proxy,
"https://":"https://"+proxy,
}
# print(proxies_dict)
response = requests.get(url, proxies_dict, timeout=2) #测试拼合出的代理是否可用正常使用
if response.status_code == 200:
print("这个代理:", proxies_dict, "可用")
else:
print("经过测试本次爬取中无可用代码")
理论上这种免费IP代理配置非常低,几百个都很少有几个能正常使用的,这里运气不错在第一页爬取就找到个可用的

验证一下,可以正常使用IP代理进行网页访问

然后就可以将爬取到的可用IP放到代理插件里进行代理浏览网页
稍微观察一下url翻页的规律,然后把翻页变量加入url,再加上for in range的循环就可以进行多页爬取,爬取n页源码筛选捕获所有可用IP就可以组建自己的代理池
原本事情就这样告一段落,
但之后继续对的爬虫代码功能完善和测试中发现 对网站进行多次爬取/多页爬取,经常会发生如下图所示,网站检测到爬取痕迹然后被ban
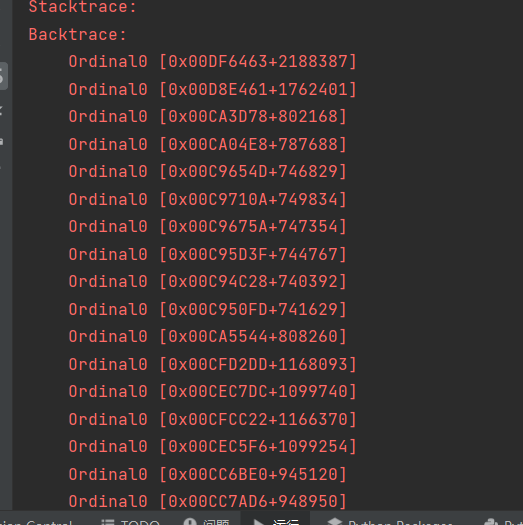
很明显的反爬手段,可以开本机代理或者用已有代理池IP继续爬取,只不过之后反爬的检测会愈加频繁
甚至出现多页爬取爬着爬着就被ban了
比如这里爬到第六页中途就被ban
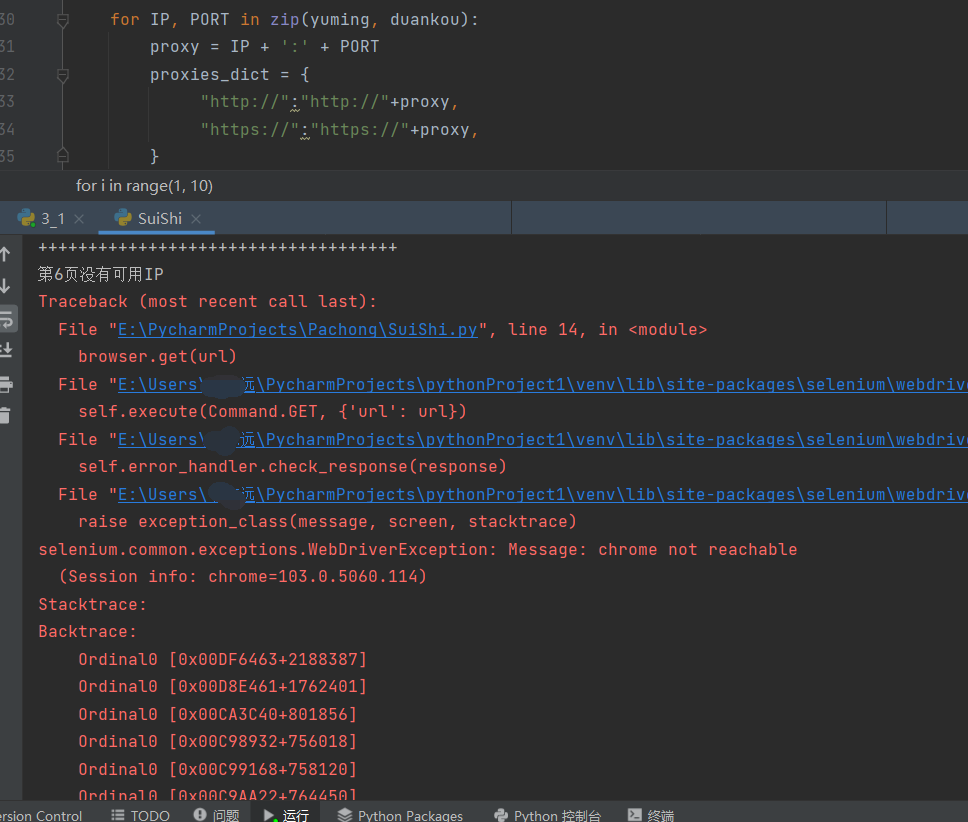
这里仍有解决方式,就是准备已有代理池进行随机选取代理爬取,
只不过这种方法并不实用,对于普通人而言所付出代价高于收益,源码就不放了