并查集
并查集是一种树型的数据结构,用于处理一些不相交集合的合并与查询问题。主要两种操作(合并和查询):
- 根据两个元素的关系合并两个集合;
- 查询两个元素是否存在关系(是否在同一个集合中)和查询节点的根节点。
实现:
一个集合构建一棵树,任选一个元素作为该集合的根节点;
建立pre数值记录每个元素的父节点,pre[当前节点]为父节点,根节点的父节点为自己本身。
1、合并
给定元素关系,将一个集合的树变为另一个集合的子(将一个集合的根节点的父节点改为另一个集合的根节点),如:B的根节点等于A的根节点,这就可以将A和B两棵树合并为一棵树。

2、查询
判断两个元素是否在同一个集合中:
从该元素开始访问父节点(一般用递归查找),直到一步步访问到根节点,再对两个元素的根节点进行对比判断(若两个元素的根节点相同则属于同一集合,否则不属于同一集合)。
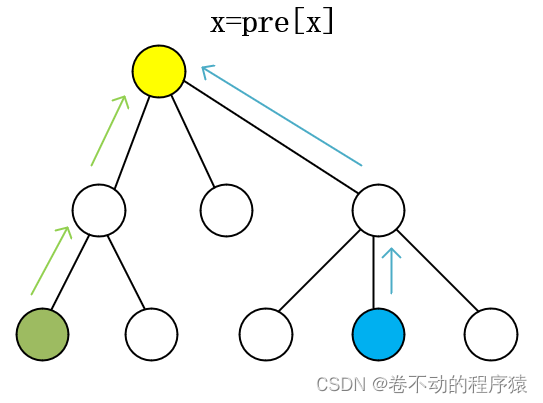
注:并查集的"并”与"查”时间复杂度取决于树的深度。
扫描二维码关注公众号,回复:
14708239 查看本文章

路径压缩(优化)
有些树结构(如图左)基本无法做时间复杂度的优化。因此,我们需要使用算法优化——路径压缩(如图右)。


在查询操作时,最终目的是找到这个元素所在的这棵树的根节点,那么它和其他元素是如何联系的对我们来说就没有意义了。即很多时候,查询过程中只关心根节点是什么(不关心树的形态),因此可以在查询是将已经访问过的每个节点都指向树的根节点(路径压缩)。所以,在每次查询时,对被查询元素到根节点沿途经过的节点顺便进行一步路径压缩:将经过节点的父节点都更改为根节点,pre[经过节点]等于根节点。
python代码
"""并查集"""
import numpy as np
class UnionFindSet():
def __init__(self, data_list):
# 初始化两个字典,分别保存节点的父节点(并查集)和保存父节点的大小
self.father_dict = {} # father_dict[i]表示节点i的父节点
self.size_dict = {} # size_dict[i]表示节点i的后代节点个数
# 初始化节点,将节点的父节点设为自身,size设为1
for node in data_list:
self.father_dict[node] = node
self.size_dict[node] = 1
# 递归查找根节点(父节点是自己的节点)
def find(self, node):
# 获取节点的父节点
father = self.father_dict[node]
# 查找当前节点的父节点,直到父节点是其自己
if(node != father):
# 在降低树高优化时,确保父节点大小字典正确
if father != self.father_dict[father]:
self.size_dict[father] -= 1
# 递归查找节点的父节点,直到根节点
father = self.find(father)
# 在查找父节点的时候,顺便把当前节点移动到父节点上面(优化操作)
self.father_dict[node] = father
return father
# 查看两个节点是不是在一个集合里面
def is_same_set(self, node_a, node_b):
# 获取两个节点的父节点并比较父节点是否是同一个
return self.find(node_a) == self.find(node_b)
# 将两个集合合并在一起(只需合并根节点),size_dict大吃小(尽可能降低树高)
def union(self, node_a, node_b):
if node_a is None or node_b is None:
return
# 找到两个节点各自的根节点
a_root = self.find(node_a)
b_root = self.find(node_b)
# 两个节点不在同一集合中,则合并两个集合
if(a_root != b_root):
# 获取两个集合根节点的大小
a_set_size = self.size_dict[a_root]
b_set_size = self.size_dict[b_root]
# 判断两个集合根节点大小,并进行合并(大吃小)
if(a_set_size >= b_set_size):
# 合并集合
self.father_dict[b_root] = a_root
# 更新大小
self.size_dict[a_root] = a_set_size + b_set_size
else:
# 合并集合
self.father_dict[a_root] = b_root
# 更新大小
self.size_dict[b_root] = a_set_size + b_set_size
if __name__=="__main__":
# 待合并节点对(关系)
node_union = [[1, 2], [1, 5], [3, 4], [5, 2], [1, 3]]
# 待判断的节点对(关系)
check_node = [[1, 4], [2, 3], [5, 6]]
# 所有节点
setN = set(np.array(node_union).flatten().tolist()+np.array(check_node).flatten().tolist())
# 并查集
model = UnionFindSet(list(setN))
# 循环合并节点
print("开始合并----------")
for i in range(len(node_union)):
node1, node2 = node_union[i][0], node_union[i][1]
model.union(node1, node2)
# 循环查找父节点
print("开始查找----------")
for i in setN:
father = model.find(i)
print("节点{}的根节点是{}".format(i, father))
# 循环判断关系(是否属于同一集合)
print("开始判断----------")
for i in range(len(check_node)):
node1, node2 = check_node[i][0], check_node[i][1]
if model.is_same_set(node1, node2):
print('{}和{}属于同一集合'.format(node1, node2))
else:
print('{}和{}属于不同集合'.format(node1, node2))