
作者|郑建华
更新|赵露阳
OneFlow 的 Global Tensor 有两个必要属性:
-
Placement:决定了 tensor 数据分布在哪些设备上。
-
SBP:决定了 tensor 数据在这些设备上的分布方式。例如:
-
-
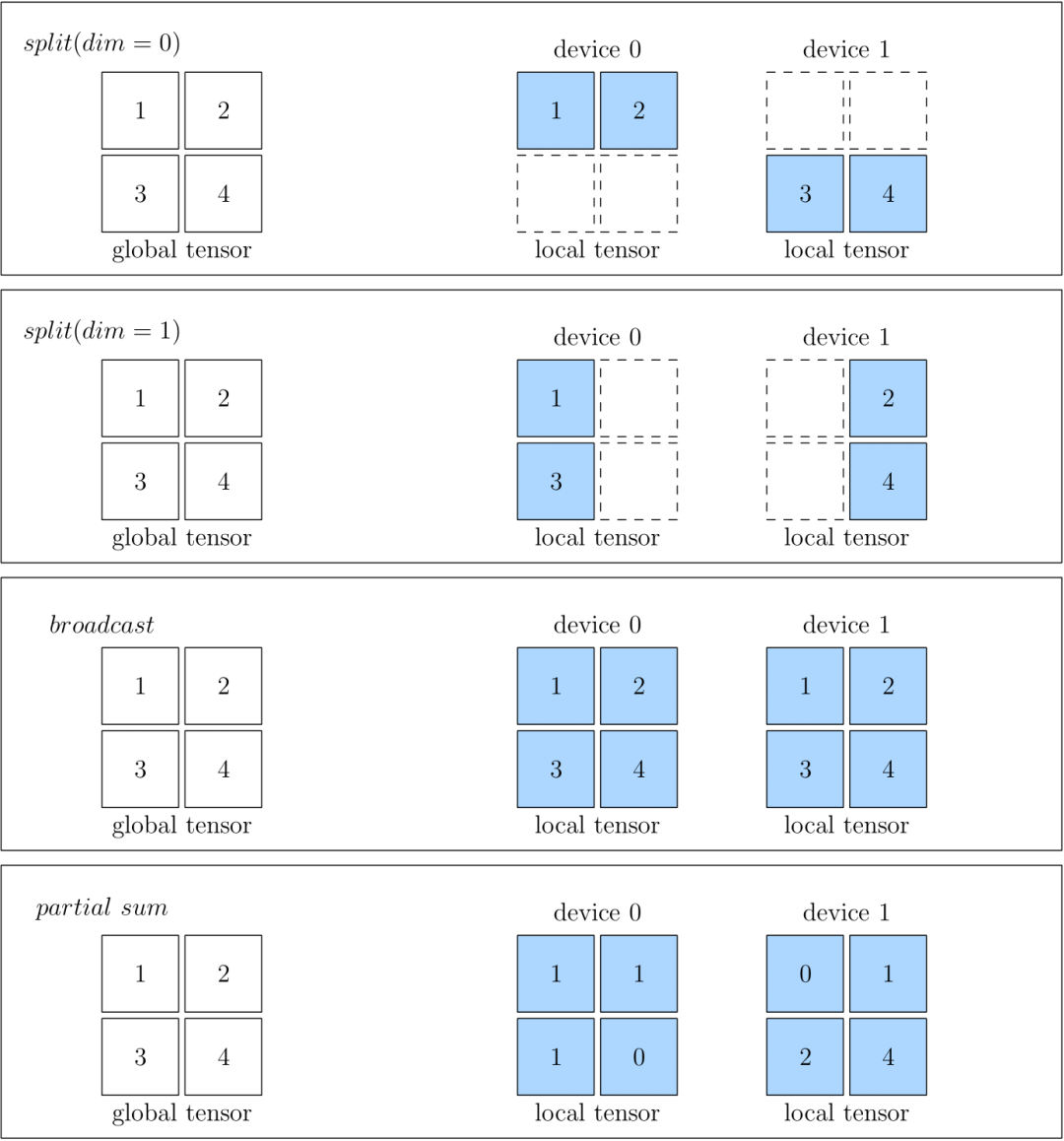
split:将切分后的不同部分放到不同设备;同时指定切分的 axis。
-
broadcast:将数据复制到各个设备。
-
如果参与运算的 tensor 的 SBP 不一样,结果 tensor 的 SBP 是什么呢?例如下面的代码:
# export MASTER_ADDR=127.0.0.1 MASTER_PORT=17789 WORLD_SIZE=2 RANK=0 LOCAL_RANK=0
# export MASTER_ADDR=127.0.0.1 MASTER_PORT=17789 WORLD_SIZE=2 RANK=1 LOCAL_RANK=1
import oneflow as flow
P0 = flow.placement("cpu", ranks=[0, 1])
t1 = flow.Tensor([[1.0, 2.0, 3.0, 4.0], [5.0, 6.0, 7.0, 8.0]], placement=P0, sbp=flow.sbp.split(0))
# t1 = flow.Tensor([[1.0, 2.0, 3.0, 4.0], [5.0, 6.0, 7.0, 8.0]], placement=P0, sbp=flow.sbp.broadcast)
t2 = flow.Tensor([[1.0, 2.0, 3.0, 4.0], [5.0, 6.0, 7.0, 8.0]], placement=P0, sbp=flow.sbp.split(1))
t3 = t1 + t2
# oneflow.placement(type="cpu", ranks=[0, 1])
print(t3.placement)
# (oneflow.sbp.split(dim=0),)
print(t3.sbp)t1和t2是分布在相同设备上的两个 tensor。t1.sbp是S(0),在行上切分;t2.sbp是S(1),在列上切分。
计算结果t3的 SBP 不需要用户手动指定,系统可以自动推导出t3.sbp为S(0)。这个过程中的一个核心步骤,就是 SBP Signature 的推导。
1
SBP相关概念
1.1 SBP
SBP是OneFlow中独有的概念,其描述了张量逻辑上的数据与张量在真实物理设备集群上存放的数据之间的一种映射关系。以下内容参考SBP官方文档(https://docs.oneflow.org/master/parallelism/02_sbp.html#sbp):
详细而言:
-
split表示物理设备上的 Tensor,是将全局视角的 Tensor 切分得到的。切分时,需要指定切分的维度。物理设备上的 Tensor ,经过拼接,可以还原得到全局视角的 Tensor 。
-
broadcast表示全局视角下的 Tensor,会复制并广播到所有的物理设备上。
-
partial 表示全局视角下的 Tensor 与物理设备上的 Tensor 的 形状相同,但是物理设备上的值,只是全局视角下 Tensor 的 一部分。以 partial sum 为例,如果我们将集群中所有设备的张量按位置相加,那么就可以还原得到全局视角的 Tensor。除了 sum 外,min、max 等操作也适用于 partial。
下图中分别展示了 SBP 的情况,分别是 split(0)、split(1)、broadcast 和 partial sum。
1.2 SBP Signature
SBP Signature即SBP签名,是OneFlow中独创且很重要的概念。本节以下文字摘自SBP Signature的官方文档:
-
对于一个孤立的 Tensor,我们可以随意设置它的 SBP 属性。但是,对于一个有输入、输出数据的算子,我们却不可以随意设置它的输入、输出的 SBP 属性。这是因为随意设置一个算子输入输出的 SBP 属性,可能不符合全局视角下算子的运算法则。
-
对于某个算子,其输入输出的一个特定的、合法的 SBP 属性组合,称为这个算子的一个 SBP Signature。
-
算子作者根据算子的运算法则,在开发算子时,就已经罗列并预设好该算子所有可能的 SBP Signature。
-
某一层算子只要有输入的 SBP 属性,OneFlow 就可以根据 SBP Signature 推导出该层算子输出的 SBP 属性。
-
所谓的 SBP Signature 自动推导,指的是:在给定所有算子的所有合法的 SBP Signature 的前提下,OneFlow 有一套算法,会基于传输代价为每种合法的 SBP Signature 进行打分,并选择传输代价最小的那个 SBP Signature。这样使得系统的吞吐效率最高。
-
如果 OneFlow 自动选择的 SBP Signature,上一层算子的输出与下一层算子的输入的 SBP 属性不匹配时,那怎么办呢?OneFlow 会检测到这种不一致,并且在上游的输出和下游的输入间插入一类算子,做相关的转换工作。这类自动加入做转换的算子,就称为 Boxing 算子。
总结一下,SBP Signature 的要点如下:
-
每个算子都需要设置相应的SBP签名,用于描述数据(Tensor)的分布方式。
-
SBP签名包括算子的全部输入、输出的SBP。缺少(部分)输入,或(部分)输出,不能构成签名。
-
-
所以SbpSignature.bn_in_op2sbp_parallel是一个map结构,key就是各个input和output的标识。
-
-
输入与输出的SBP签名组合,在算子的运算法则下必须是合法的,算子的作者需要列出合法SBP签名的候选集。
-
如果输入数据(input tensor)的SBP与该算子合法的SBP签名不一致,则为了得到该算子正确计算所需要的数据(tensor),OneFlow 会在上游的输出和下游的输入间插入boxing算子(可能包含nccl等集合通信操作),做自动转换工作,这类自动转换的过程,就称为 Boxing。例如,eager global模式下的interpreter在GetBoxingOutput方法中完成Boxing过程。
1.3 NdSbp 及 NdSbpSignature
在上面1.1小节中,我们了解到SBP用于描述一个逻辑张量(Tensor),与其对应物理设备上的映射关系,那OneFlow中的2D甚至ND SBP又是什么意思呢?
简单理解就是,普通的SBP(1D/1维 SBP)只能比较粗粒度地对张量进行切分,譬如split(0)就表示,沿着张量第0维进行切分,如果在此基础上,想进行更细粒度的切分,譬如继续沿着第1维再“切一刀”,那么普通的1D SBP就无法做到了,于是需要2D或者ND SBP。
以下文字主要参考官方文档2D SBP。
我们可以通过ranks=[0, 1, 2, 3]指定tensor的数据分布在这4个设备上。这4个设备组成了一个一维的设备矩阵。对应的 SBP 如split(1),是单个值,即 1D SBP。
Tensor 数据的分布也可以指定为ranks=[[0, 1], [2, 3]]。四个计算设备被划分为2x2的设备矩阵。这时,SBP 也必须与之对应,是一个长度为 2 的数组。对应的NdSbp.sbp_parallel的类型就是数组。
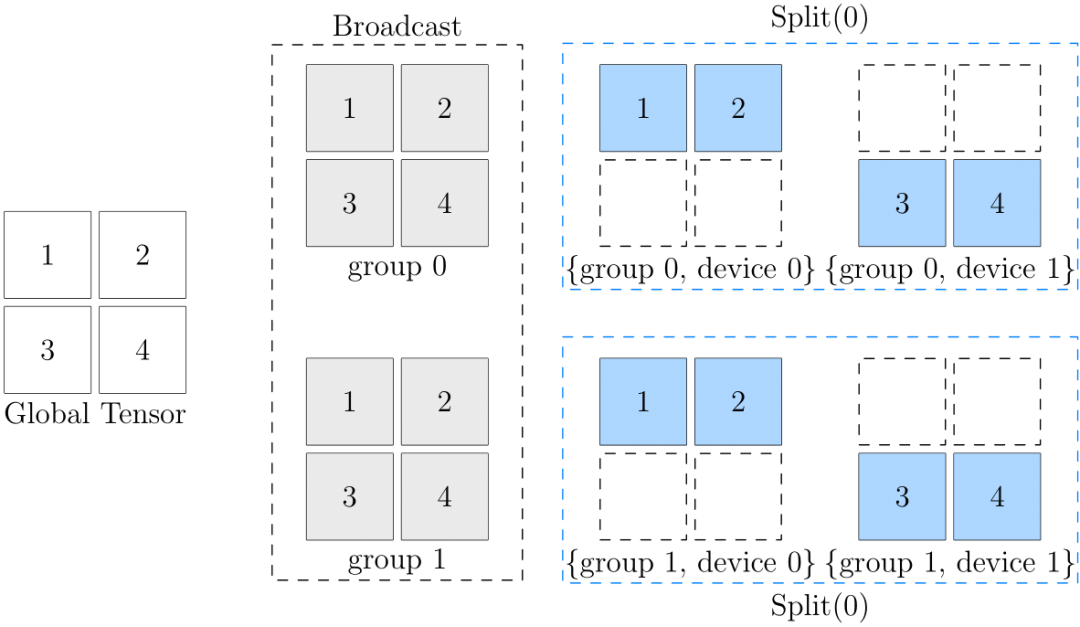
例如sbp = (broadcast, split(0))。这个 2D SBP 的含义是:
-
在 ranks 的第一维度执行广播,将数据分别拷贝到group 0(rank [0, 1])和group 1(rank [2, 3])。
-
在 ranks 的第二维度分别执行split(0)。
-
-
例如,对于group 0,将上一步中分配给它的数据按行拆分成(1,2)和(3,4)分别给device 0和device 1。
-
示意图如下:
如果 Tensor 的数据分布形式是多维的,如[[0, 1], [2, 3]],算子对应的 SBP Signature 也是多维的,所以NdSbpSignature中,每个 input/output 对应的 sbp_parallel 都是数组。
2
placement.hierarchy
placement 对应的 C++ 类型是ParallelDesc。构造 placement 的 ranks 可以是多维数组,表示设备的多维分布矩阵。
placement.hierarchy表示了placement上ranks的层次信息。简单理解,hierarchy就是用于描述ranks分布的形状(类似于shape可用于描述tensor数据分布的形状),hierarchy存储了 ranks 在各个维度的 size 信息。
-
hierarchy 数组的长度是 ranks 的维数。
-
hierarchy 数组的元素值,是 ranks 对应维度的 size。
-
构造 hierarchy 的 C++ 代码可参考GetRanksShape。
运行下面的代码可以观察 hierarchy 的值。
import oneflow as flow
placements = [
flow.placement("cpu", ranks=[ 0, 1, 2, 3, 4, 5]),
flow.placement("cpu", ranks=[[0, 1, 2], [3, 4, 5]]),
]
for p in placements:
print(p.hierarchy)
# outputs:
# [6]
# [2, 3]3
tensor add 是哪个算子?
为了提高性能,从v0.8.0开始,Tensor 的接口基本都通过 C API 提供给Python。
PyTensorObject_methods中定义了很多 Tensor 方法。不过,add 方法是通过 Python C API 的 number protocol 实现的,指定 PyTensorObject_nb_add 实现加法操作,实际由functional::add实现。
functional::add的定义在functional_api.yaml.pybind.cpp中,这是一个在构建期自动生成的文件。顺着这个找,容易发现示例代码对应的是AddFunctor。Op的名字是"add_n",自动生成的文件op_generated.cpp中定义了add_n对应的Op是AddNOp。add_n_op.cpp中定义的 AddNOp 的几个方法,会在 SBP Signature 推导过程中用到。
4
一维 SBP 的推导过程
SBP Signature 推导相关的类关系如下:
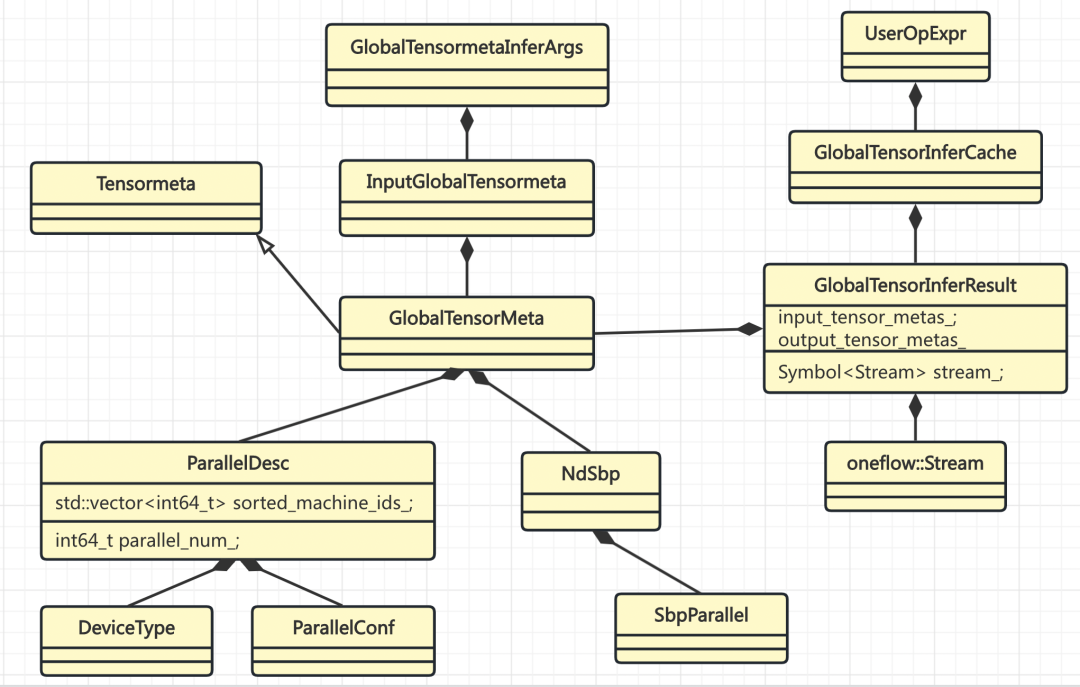
示例代码中的 tensor add 操作(t1 + t2),执行到 Interpreter的中调用GetOrInfer时,会进行 SBP Signature 的推导。在GlobalTensorInferCache::GetOrInfer中,会以GlobalTensorMetaInferArgs作为 key 把推导结果存起来,不需要每次都进行推导。
GlobalTensorMetaInferArgs的 hash 函数主要依赖输入 tensor 的如下信息:
-
shape
-
dtype
-
nd_sbp
-
placement
-
consumer_nd_sbp_constraint
不同的 tensor 对象,只要这些元信息相同,就可以复用同一个推导结果。
UserOpExpr通过GlobalTensorInferCache持有所有推导过的结果。
4.1 GlobalTensorInferCache 中的推导准备
实际的推导在GlobalTensorInferCache::Infer中进行。
4.1.1 推导 output 的 shape 和 dtype
user_op_expr.InferLogicalTensorDesc的作用主要是推导 output 的 shape 和 data_type,结果保存到 output_mut_metas。这里涉及到 UserOpExpr 和 Op 两个模块之间的交互关系。后面会总结一下几个模块之间的部分交互接口。
user_op_expr.InferLogicalTensorDesc中用到的两个函数对象,在Op中定义,并注册到OpRegistry中。OpRegistryResult 的函数对象来自 Op 注册。示例代码中 tensor add 对应的 Op 是 AddNOp。
AddNOp 场景的实际调用顺序示例如下:
-
user_op_expr.InferLogicalTensorDesc
-
-
logical_tensor_desc_infer_fn_->AddNOp::InferLogicalTensorDesc
-
out.shape = in[0].shape
-
dtype_infer_fn_->AddNOp::InferDataType
-
out.data_type = in[0].data_type
-
4.1.2 构造 UserOp
MakeOp(user_op_expr...)返回一个Operator,具体类型是UserOp(参考之前静态图的讨论)。这个对象负责执行具体的推导。
CheckInputParallelDescIdentical要求所有 inputs 的 placement 是一致的。因为这里是针对UserOp做的推导,例如 tensor add、matmul 等操作,操作数都在相同的设备时,这些操作才能直接计算,否则,就需要通过系统 Op 将数据搬运到一起,再进行计算。
既然所有 inputs 的 placement 都是一样的,那就用第一个作为代表,并赋值给 UserOp 保存。
op->InferParallelSignatureIf()的作用是将 placement 填充到op.bn2parallel_desc_。
对于 AddNOp 来说,key是in_0, in_1, out_0,value 是 inputs[0].placement。
infer_args.MakeInputBlobDescs操作用伪码表示如下:
# for each input index i
blob_descs[i].shape = inputs[i].shape
blob_descs[i].stride = inputs[i].stride
blob_descs[i].data_type = inputs[i].data_typeinfer_args.MakeNdSbpInferHints操作用伪码表示如下:
# for each input index i
hints[i].parallel_desc = inputs[i].parallel_desc
hints[i].blob_desc = blob_descs[i]
hints[i].nd_sbp = inputs[i].nd_sbpblob_descs的作用是为了构造pd_infer_hints,pd_infer_hints是为了构造NdSbpInferHint4Ibn,将相关信息封装到这个函数对象中。这个函数对象被传递给UserOp进行推导。在UserOp中,通过这个函数对象,根据input/output的标识bn(blob name),获取NdSbpInferHint,从而可以得到上述元信息。
UserOp推导完毕后,GlobalTensorInferCache会将 inputs/outputs 的元信息,连同推导得到的 NdSbp ,一起保存到GlobalensorInferResult。
4.2 Operator 中的推导准备
Operator::InferNdSbpSignatureIf中,调用InferNdSbpSignature进行实际的推导,然后调用FillNdSbpSignature保存推导结果。
InferNdSbpSignature是一个虚函数。UserOp会先检查Op有没有定义自己的 SBP Signature 推导函数,AddNOp 没有这方面的函数,就调用 Operator::InferNdSbpSignature。
InferNdSbpSignature 中会根据 parallel_desc.hierarchy() 判断是 1D SBP,还是 ND SBP。
先只看 1D SBP 的情况。调用传入的 NdSbpInferHint4Ibn 函数对象,查到 GlobalTensorInferCache 中创建的 NdSbpInferHint,转为 NdSbpInferHint 并存到 map 中。因为是一维的,所以只需要取 sbp_parallel 的第一个元素。然后调用 InferSbpSignature(名字中少了 Nd),将推导结果写到 SbpSignature。
无论是一维还是多维,结果的类型都是 NdSbpSignature。所以要将 SbpSignature 转为 NdSbpSignature。
Operator::InferSbpSignature的作用主要是构造两个函数对象,SbpInferHint4Ibn 和 CalcOrderValue4SbpSig,然后调用子类 override 的、同名重载的虚函数 InferSbpSignature。
SbpInferHint4Ibn 是将传入的 map 数据封装到函数对象中,用于查询输入输出的元信息。
CalcOrderValue4SbpSig给每个 SbpSignature 计算一个序值,用于对签名进行排序。
InferSbpSignature 也是一个虚函数。因为 AddNOp 没有定义签名推导函数,会调用 Operator::InferSbpSignature。
4.3 SbpSignature 的推导
之前都是做各种准备,Operator::InferSbpSignature里才进行真正的推导。简单讲就3步:
-
获取候选集
-
过滤不合适的签名
-
排序
4.3.1 SbpSignature 的候选集
调用 GetValidNdSbpSignatureList会获取 SbpSignature 的候选集。在这个函数中,先调用 GetNdSbpSignatureList获取初步的候选集,再通过FilterNdSbpSignatureListByLogicalShape过滤得到正确可用的候选集。候选集都保存到sbp_sig_list。
GetNdSbpSignatureList是一个虚函数,UserOp 实现了自己的版本。这个函数中最核心的操作就是val_->get_nd_sbp_list_fn,实际调用AddNOp::GetSbp。UserOpSbpContext是 UserOp 与 AddNOp 等类之间的协议接口的一部分。
如前所述,提供 SBP Signature 的候选集,是算子的责任。AddNOp这个算子比较简单,只给出两类签名:
-
对输入 tensor 的 shape 的每个 axis i,所有的 input/output 都创建一个 split(i)。
-
-
对于 tensor add 来说,input/output 的 shape 一样才能直接计算,所以 split 的 axis 也都一样。
-
-
所有的 input/output 都创建一个 partialsum。
-
broadcast 的情况会在 Operator 中默认设置,因为理论上所有inputs/outputs都应该支持以broadcast的方式进行运算。
候选集数据示例如下:
{"sbp_signature":[{"bn_in_op2sbp_parallel":{"in_0":{"split_parallel":{"axis":"0"}},"in_1":{"split_parallel":{"axis":"0"}},"out_0":{"split_parallel":{"axis":"0"}}}},{"bn_in_op2sbp_parallel":{"in_0":{"split_parallel":{"axis":"1"}},"in_1":{"split_parallel":{"axis":"1"}},"out_0":{"split_parallel":{"axis":"1"}}}},{"bn_in_op2sbp_parallel":{"in_0":{"partial_sum_parallel":{}},"in_1":{"partial_sum_parallel":{}},"out_0":{"partial_sum_parallel":{}}}},{"bn_in_op2sbp_parallel":{"in_0":{"broadcast_parallel":{}},"in_1":{"broadcast_parallel":{}},"out_0":{"broadcast_parallel":{}}}}]}4.3.2 过滤不合适的签名
分两步过滤不合适的签名
-
FilterAndCheckValidSbpSignatureListByLogicalShape中,对于每个输入tensor ibn,签名中 ibn 的 split axis,必须小于 tensor ibn 的 shape axes 数量。换句话说,如果 tensor 是二维的,就无法接受split(2),只能是split(0)或split(1)。
-
FilterSbpSignatureList的作用是检验sbp_sig_conf约束,也就是从GlobalTensorInferCache一路传过来的参数nd_sbp_constraints。这个过滤规则要求,符合条件的签名,其内容必须包含sbp_sig_conf。
4.3.3 签名排序
SortSbpSignatureListByCopyCost对候选签名进行排序。
-
优先按 OrderValue 比较
-
OrderValue 相等时,按 CopyCost 比较
二者都是较小的值优先。
OrderValue4SbpSig是对CalcOrderValue4SbpSig的封装,预先计算所有签名的 OrderValue 存到 map 中,便于 sort 函数查找。IbnCopyCost4SbpSig也是同理。
回过头来看CalcOrderValue4SbpSig的定义。因为AddNOp是有输入的,对于每个输入 tensor ibn 会加上一个权重,当 ibn 的 sbp 与 签名中对应的 sbp 相同时,权重值为-10,即增加了选中的机会,因为 sbp 一致通常就不需要数据搬运。而parallel_num的条件判断在UserOp下应该是都成立的。
当 sbp_sig_conf 不空时,CalcOrderValue4SbpSig 直接返回0。因为如果签名不包含 sbp_sig_conf,即使 SBP 都一致,签名也不一定符合要求,所以直接返回0。
签名成本由ComputeIbnCopyCost4SbpSig计算。主要是根据输入和签名的 sbp 计算 cost:
-
如果 sbp 一致,cost 为0
-
partial_sum 和 broadcast 的 cost 都是一个超大的数字。
-
否则 cost 等于 input tensor 的数据传输字节数量。
4.4 推导结果
推导得到的nd_sbp_signature如下:
{"bn_in_op2nd_sbp":{"in_0":{"sbp_parallel":[{"split_parallel":{"axis":"0"}}]},"in_1":{"sbp_parallel":[{"split_parallel":{"axis":"0"}}]},"out_0":{"sbp_parallel":[{"split_parallel":{"axis":"0"}}]}}}示例代码中,如果一个输入是split,另一个是broadcast,推导的签名结果都是broadcast。如果推断的sbp签名是split,是否能减少数据搬运呢?
5
NdSbp 的推导过程
NdSbp 的推导主要包括3步
-
调用 GetValidNdSbpSignatureList 获取有效的签名
-
剔除不能包含 nd_sbp_constraints 的签名
-
贪心搜索较优的签名
重点看一下有效签名的获取。主要是两步:
-
GetNdSbpSignatureList: 获取全部签名
-
FilterNdSbpSignatureListByLogicalShape: 过滤不合适的签名
5.1 NdSbp 签名的候选集
GetNdSbpSignatureList 核心是两步:
-
GetSbpSignaturesIf: 得到一维的签名(和 1D SBP 的情况相同)
-
DfsGetNdSbpSignature: 根据一维签名拓展到多维
这个过程,如果深入到数据细节去看,会涉及 input/output、ranks、NdSbp 等多个维度,有点抽象复杂。如果从官方文档 2D SBP中说明的 ranks 和 NdSbp 的物理含义出发,会更容易理解。
以ranks=[[0, 1, 2], [3, 4, 5]]为例(ranks=[r1, r2])
这是一个二维的设备矩阵/阵列。算子的每个输入、输出也都有两个 sbp,NdSbpSignature 中的 value 是二维的,有两个槽位。假设 Op 的 1D Sbp 有 n 个签名。
从形式上看,NdSbpSignature 是先按 bn 组织数据。但是从数据分布的过程看,是先按SbpSignature组织数据。一个 NdSbpSignature 等价于 SbpSignature 数组。NdSbp中的每个槽位,都表示一个 1D Sbp 的数据分布(所有的 input/output一起分布)。
-
比如第 0 个槽位,就是在r1和r2这两个 sub group 之间分布数据,这个分布必须是一个有效的 1D SbpSignature(所有的 input/output一起分布)。
-
第 1 个槽位,对于r1,就是将分配给它的数据子集,再根据一个 SbpSignature 进行分布(所有的 input/output一起分布)。
所以,只需要按 SbpSignature整体 填满两个槽位就行。每个槽位各有 n 种可能,一共有 n*n 个候选签名。这样生成的候选集是完整的,不会漏掉候选项。这应该就是 direct product of 1D sbp signatures 的含义。
6
模块间协作关系
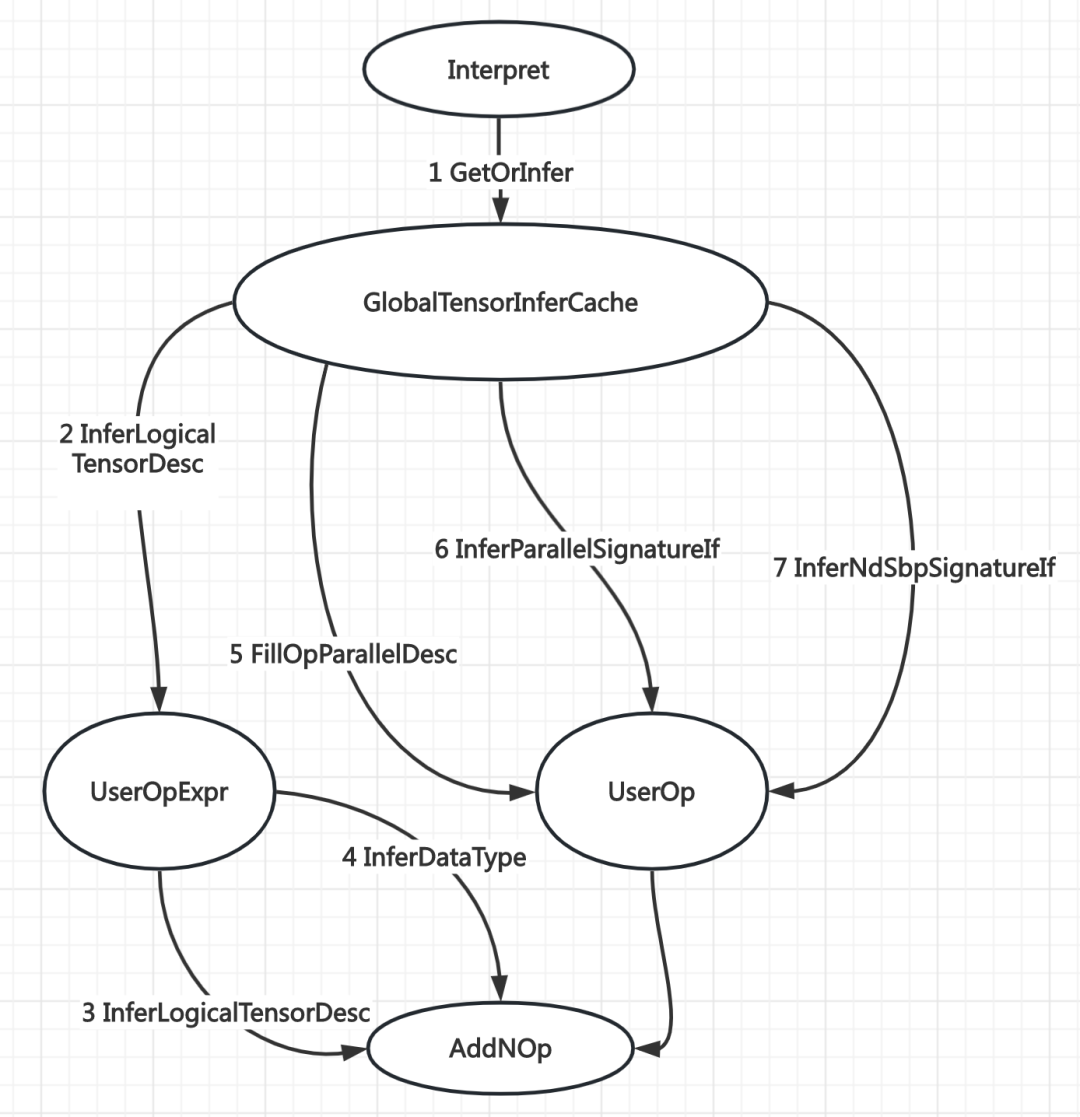
SbpSignature 推导的实现用了大量 functional 的代码。应该是为了不同模块间的信息屏蔽,或者父类、子类之间的逻辑复用、信息传递等目的,很多信息都封装到 function 中,需要时再检索、转换。
下图展示了不同模块之间的部分关系:
参考资料
-
oneflow v0.9.1(https://github.com/Oneflow-Inc/oneflow/tree/0ea44f45b360cd21f455c7b5fa8303269f7867f8/oneflow)
-
SBP Signature(https://docs.oneflow.org/master/parallelism/02_sbp.html#sbp-signature)
-
2D SBP(https://docs.oneflow.org/master/parallelism/04_2d-sbp.html)
-
placement api(https://oneflow.readthedocs.io/en/master/tensor_attributes.html?highlight=placement#oneflow-placement)
-
https://segmentfault.com/a/1190000042625900
其他人都在看