一维数据格式化和处理
一维数据:由对等关系的有序或无序数据构成,采用线性方式组织
一维数据的表示
如果数据间有序:使用列表类型
ls = [3.1398, 3.1349, 3.1376]
列表类型可以表达一维有序数据 - for循环可以遍历数据,进而对每个数据进行处理
如果数据间无序:使用集合类型
st = {3.1398, 3.1349, 3.1376}
集合类型可以表达一维无序数据 - for循环可以遍历数据,进而对每个数据进行处理
一维数据的读入处理
从空格分隔的文件中读入数据
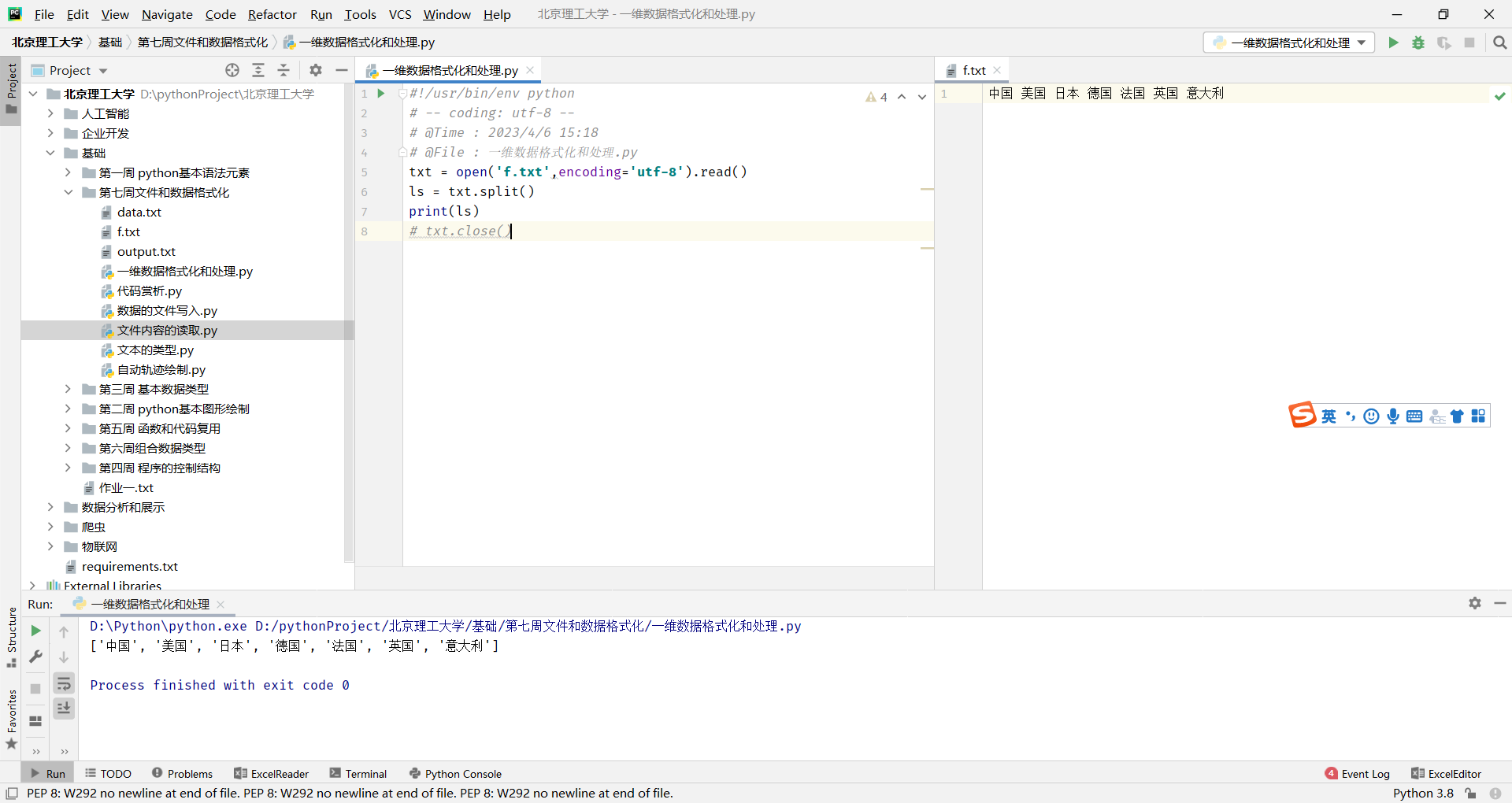
从特殊符号分隔的文件中读入数据
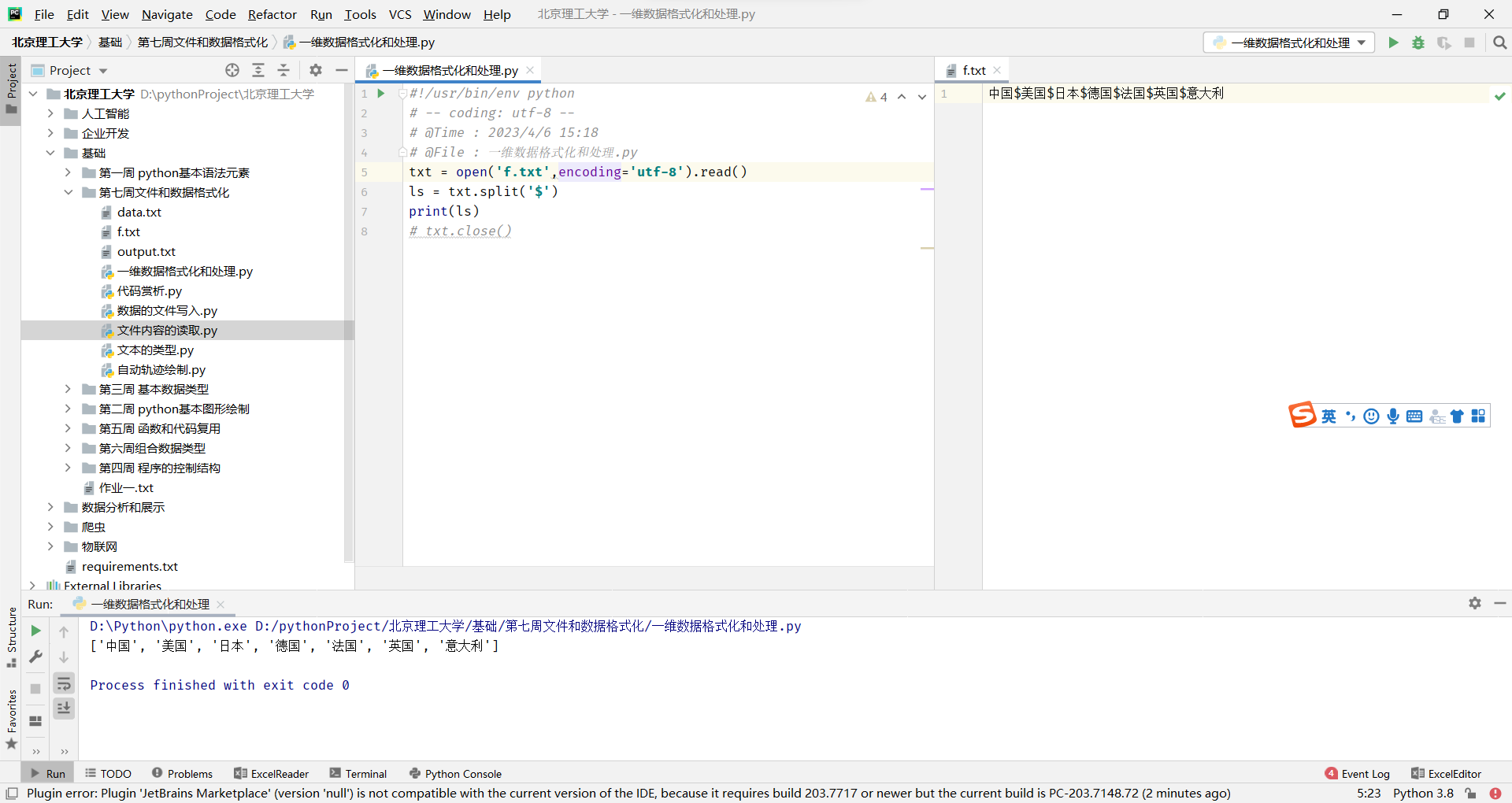
采用空格分隔方式将数据写入文件

采用特殊分隔方式将数据写入文件
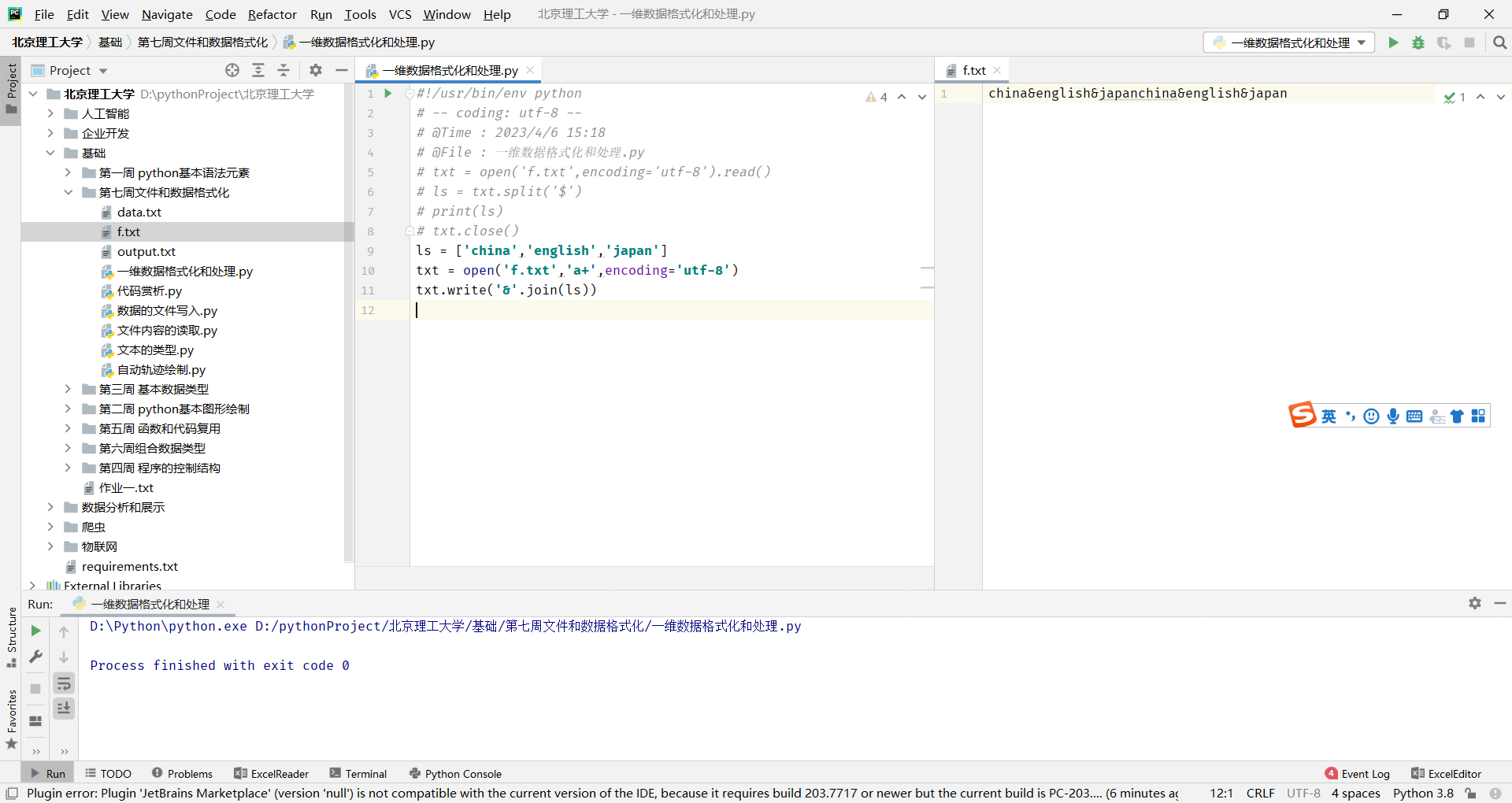
二维数据格式化和处理
二维数据的表示
二维数据一般可以理解为我们说的表格
列表类型可以表达二维数据,使用二维列表
[[3.1398, 3.1349, 3.1376], [3.1413, 3.1404, 3.1401] ]
使用两层for循环遍历每个元素
外层列表中每个元素可以对应一行,也可以对应一列
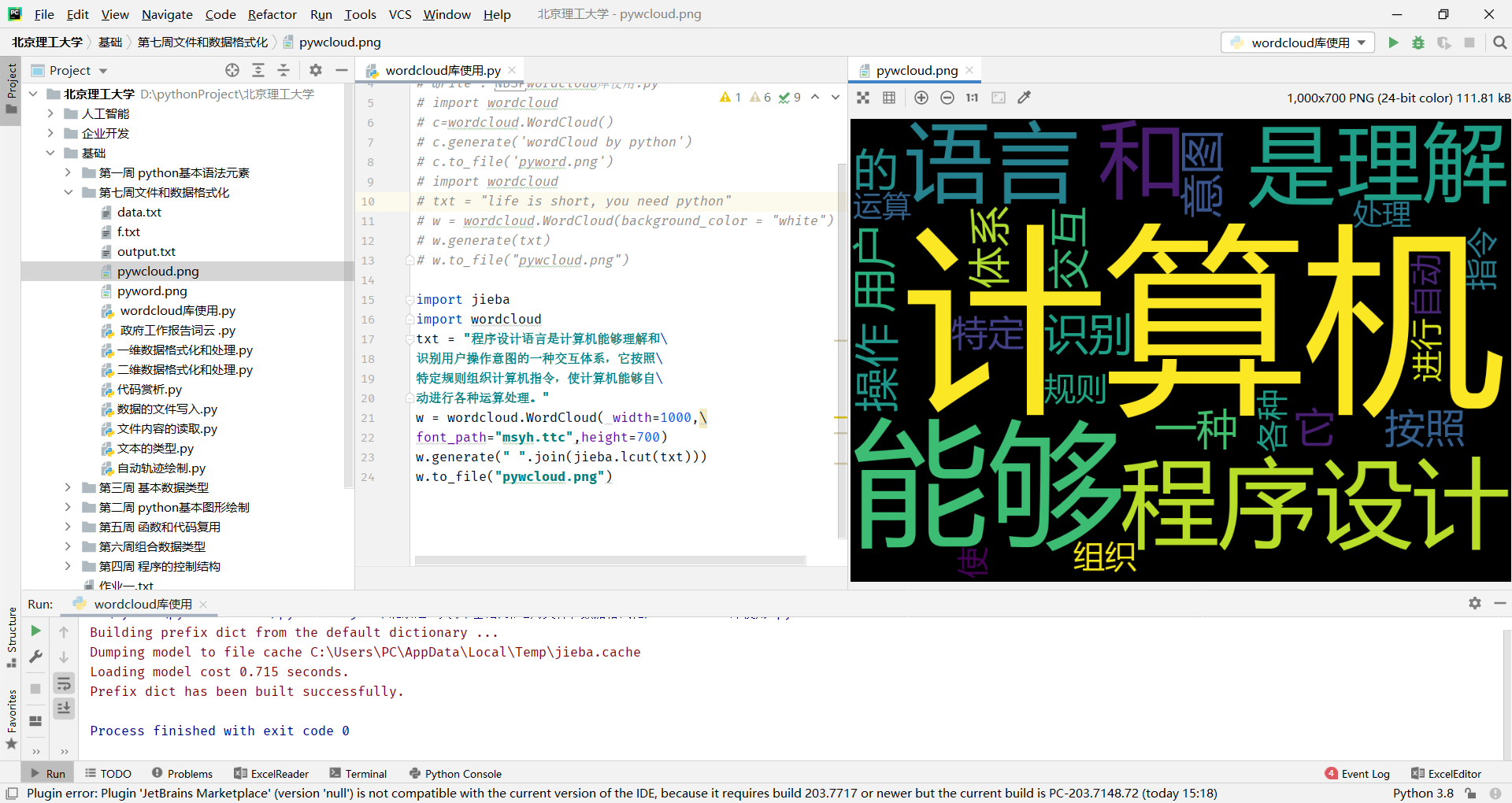
CSV格式与二维数据存储
CSV: Comma-Separated Values
国际通用的一二维数据存储格式,一般.csv扩展名
每行一个一维数据,采用逗号分隔,无空行
Excel和一般编辑软件都可以读入或另存为csv文件
 左边为一个表格,存储为csv格式变成了右边
左边为一个表格,存储为csv格式变成了右边
csv文件的规则
如果某个元素缺失,逗号仍要保留
二维数据的表头可以作为数据存储,也可以另行存储
逗号为英文半角逗号,逗号与数据之间无额外空格



wordcloud库使用
wordcloud库的安装
(cmd命令行) pip install wordcloud

wordcloud库基本使用
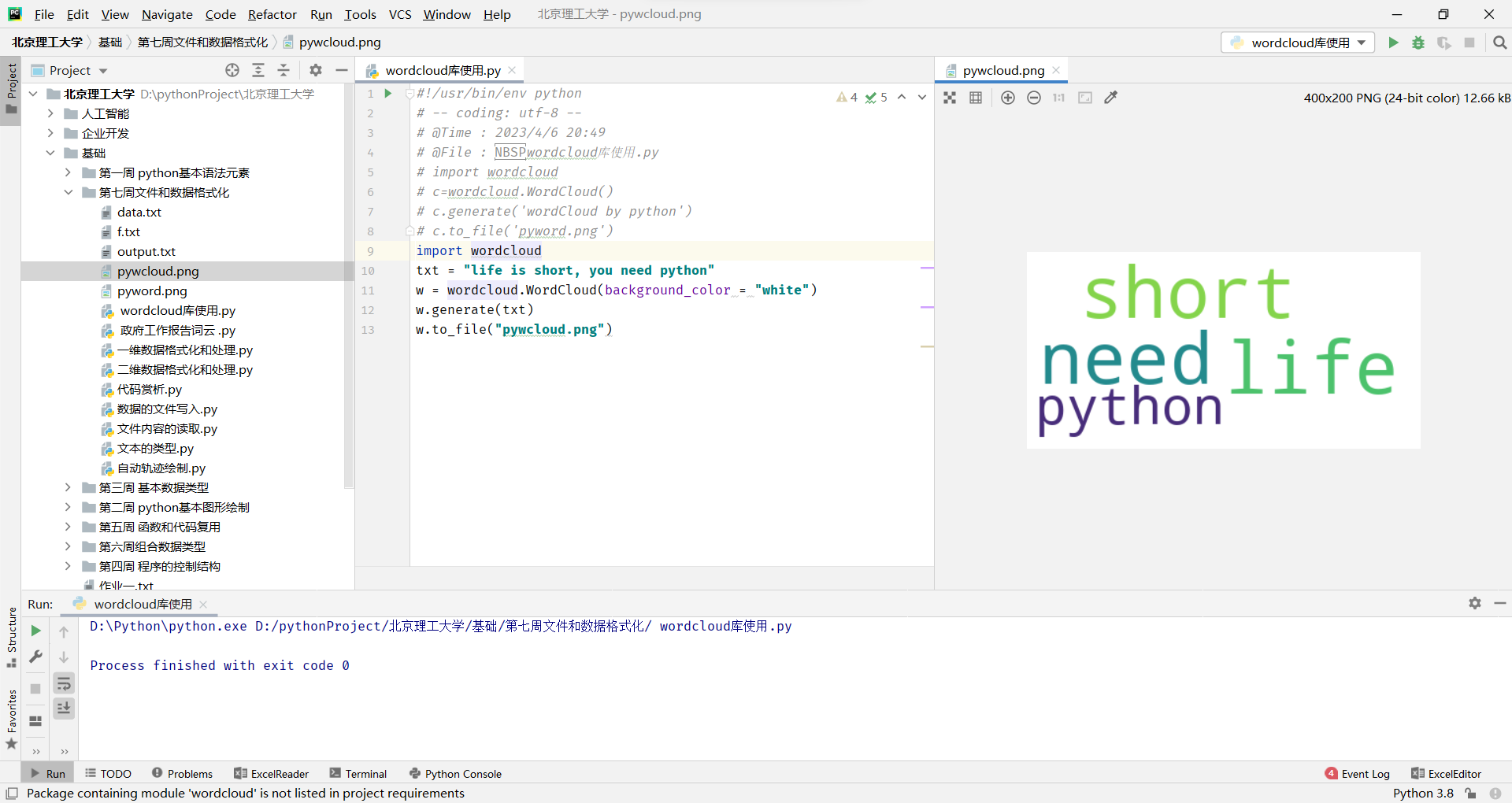
wordcloud库把词云当作一个WordCloud对象
wordcloud.WordCloud()代表一个文本对应的词云
可以根据文本中词语出现的频率等参数绘制词云
词云的绘制形状、尺寸和颜色都可以设定
w = wordcloud.WordCloud()
以WordCloud对象为基础
配置参数、加载文本、输出文件



 配置对象参数
配置对象参数



 政府工作报告词云
政府工作报告词云
问题分析
直观理解政策文件
需求:对于政府工作报告等政策文件,如何直观理解?
体会直观的价值:生成词云 & 优化词云
政府工作报告等文件 -> 有效展示的词云
基本思路
- 步骤1:读取文件、分词整理 - 步骤2:设置并输出词云 - 步骤3:观察结果,优化迭代
https://python123.io/resources/pye/新时代中国特色社会主义.txt
https://python123.io/resources/pye/关于实施乡村振兴战略的意见.txt

#!/usr/bin/env python
# -- coding: utf-8 --
# @Time : 2023/4/6 19:57
# @File : 政府工作报告词云 .py
import jieba
import wordcloud
f = open("关于实施乡村振兴战略的意见.txt", "r", encoding="utf-8")
t = f.read()
f.close()
ls = jieba.lcut(t)
txt = " ".join(ls)
w = wordcloud.WordCloud( font_path = "msyh.ttc",\
width = 1000, height = 700, background_color = "white", \
)
w.generate(txt)
w.to_file("grwordcloud.png")生成更有型的词云
wordcloud库提供了mask参数,通过覆盖的方式,可以生成任意形状的词云。比如:你要生成五角星,那么你就要提供背景为白色的五角星图片
