1. H264编码分层
- NAL层:(Network Abstraction Layer,视频数据网络抽象层): 它的作用是H264只要在网络上传输,在传输的过程每个包以太网是1500字节,而H264的帧往往会大于1500字节,所以要进行拆包,将一个帧拆成多个包进行传输,所有的拆包或者组包都是通过NAL层去处理的。
- VCL层:(Video Coding Layer,视频数据编码层): 对视频原始数据进行压缩

我们可以看到视频帧序列每一帧图像是由slice构成的,每一个slice是由多个宏块构成的,在实际传输的过程中,一般一帧图像就是一个slice,没有分那么细。
NAL单元的结构组成

- SODB:(String of Data Bits,原始数据比特流):由VCL层产生,数据长度不一定是8的倍数,所以处理起来比较麻烦
- RBSP:(Raw Byte Sequence Payload,SODB+trailing bits,编码后的数据流):算法是在SODB最后一位补1,不按字节对齐补0,如果补齐0,不知道在哪里结束,所以补1,如果不够8位则按位补0
- EBSP:(Encapsulate Byte Sequence Payload):生成编码后的数据流之后,我们还要在每个帧之前加一个起始位,需要开发者人为添加。起始位一般是十六进制的0001。但是在整个编码后的数据里,可能会出来连续的2个0x00。那这样就与起始位产生了冲突.那怎么处理了? H264规范里说明如果处理2个连续的0x00,就额外增加一个0x03 。这样就能预防压缩后的数据与起始位产生冲突 【EBSP 其实就是 RBSP 前面增加起始位】
- NALU: (NAL Header(1B)+EBSP).NALU就是在EBSP的基础上加1B的网络头.
Slice 宏块分层:
在上述的VCL层中,切片与宏块划分的具体情况如下,对于slice是由header和data组成,data中由很多的宏块(MacroBlock)组成,在宏块中存储的包括宏块的类型 mb_type,宏块的预测值mb_pred 和残差值 codec residual

实际上H264码流包含了两种格式,Annexb和RTP格式的。整体码流结构为如下形式:
在文件中保存的,每一个NAL单元前面都有一个startcode,00开头的起始码,这样由Startcode和NAL单元构成的就是Annexb格式。
在网上传输,不包含startcode,直接传输NAL单元叫RTP码流。
H264 原始码流的组成
2、码流总体结构:
h264的功能分为两层,视频编码层(VCL)和网络提取层(NAL)。H.264 的编码视频序列包括一系列的NAL 单元,每个NAL 单元包含一个RBSP。一个原始的H.264 NALU 单元常由 [StartCode] [NALU Header] [NALU Payload] 三部分组成,其中 Start Code 用于标示这是一个NALU 单元的开始,必须是"00 00 00 01" 或"00 00 01"。

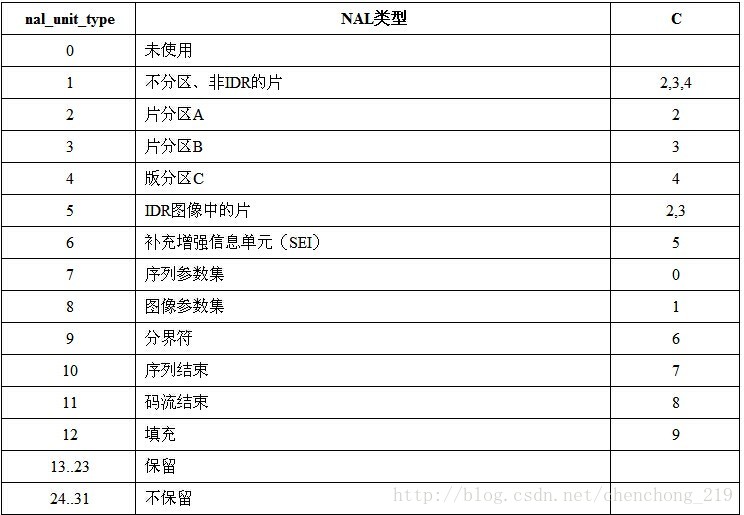
NAL 头部编码是表示 RBSP 的信息,有 12 种
NAL Header头部编码格式:
占一个字节,8 位,由三部分组成forbidden_bit(1bit),nal_reference_bit(2bits)(优先级),nal_unit_type(5bits)(类型)。
forbidden_bit:禁止位。
nal_reference_bit:当前NAL的优先级,值越大,该NAL越重要。
nal_unit_type :NAL类型
如下例子:

IDR帧(关键帧)
- IDR(Instantaneous Decoding Refresh)即时解码刷新。 在编码解码中为了方便,将GOP中首个I帧要和其他I帧区别开,把第一个I帧叫IDR,这样方便控制编码和解码流程,所以IDR帧一定是I帧,但I帧不一定是IDR帧;IDR帧的作用是立刻刷新,使错误不致传播,从IDR帧开始算新的序列开始编码。I帧有被跨帧参考的可能,IDR不会。
- I帧不用参考任何帧,但是之后的P帧和B帧是有可能参考这个I帧之前的帧的。IDR就不允许这样,例如:

- 其核⼼作⽤是,是为了解码的重同步,当解码器解码到 IDR 图像时,⽴即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始⼀个新的序列。这样,如果前⼀个序列出现重⼤错误,在这⾥可以获得重新同步的机会。IDR图像之后的图像永远不会使⽤IDR之前的图像的数据来解码。
IDR 关键帧的核⼼作⽤是,是为了解码的重同步,当解码器解码到 IDR 图像时,⽴即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始⼀个新的序列。这样,如果前⼀个序列出现重⼤错误,在这⾥可以获得重新同步的机会。IDR图像之后的图像永远不会使⽤IDR之前的图像的数据来解码。

如何定义 IBP帧和数据传输
- 分组,也就是将一系列变换不大的图像归为一个组,也就是一个序列,也可以叫GOP(画面组);
- 定义帧,将每组的图像帧归分为I帧、P帧和B帧三种类型;
- 预测帧, 以I帧做为基础帧,以I帧预测P帧,再由I帧和P帧预测B帧;
- 数据传输, 最后将I帧数据与预测的差值信息进行存储和传输。【这里是以预测的差值作为存储】
从图中我们需要得到一个概念,H264码流是由一个个的NAL单元组成,其中SPS、PPS、IDR和SLICE是NAL单元某一类型的数据。【由NAL 头部单元去定义的】
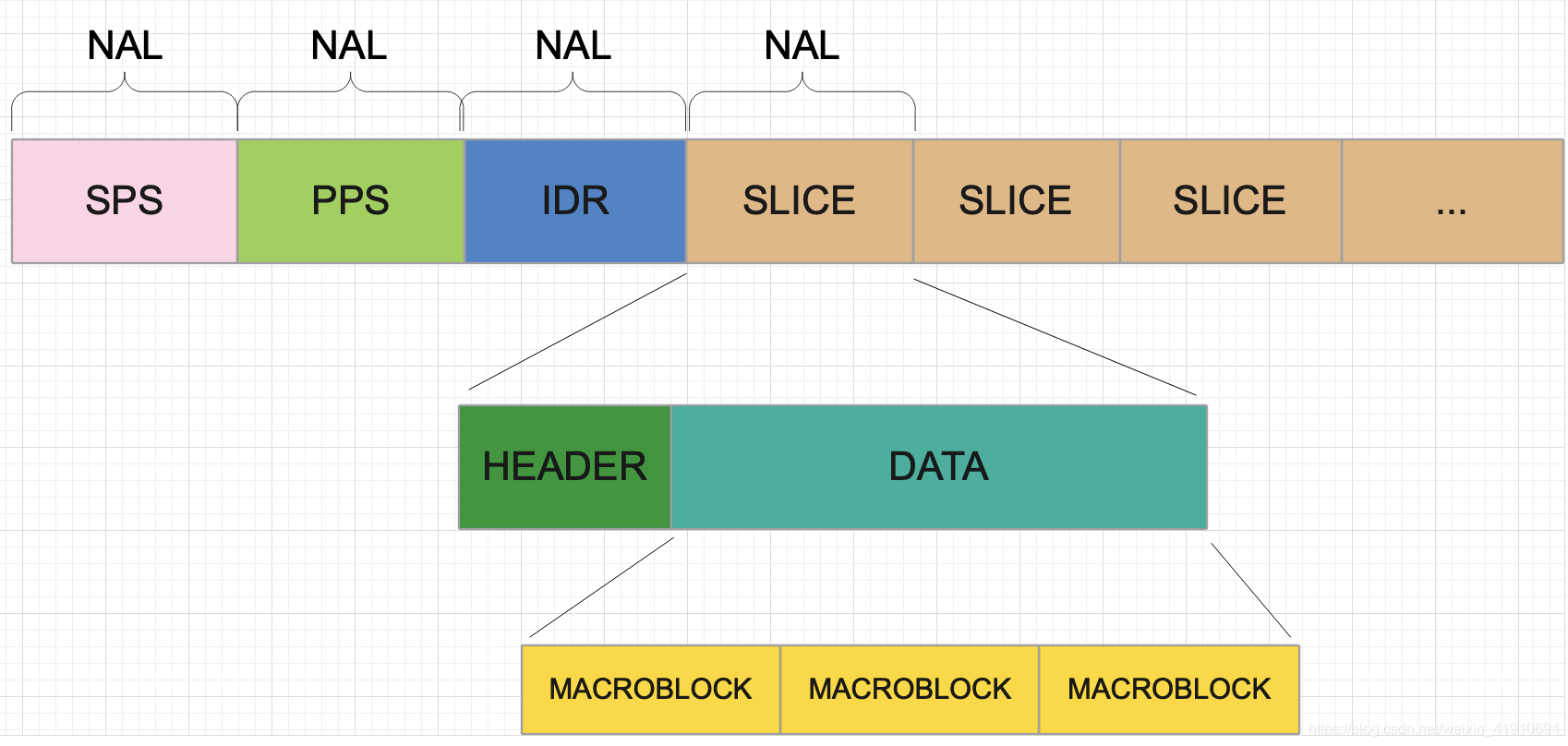
SPS 和 PPS
- SPS(Sequence Parameter Set:序列参数集)包含一些通用的参数,比如Profile和Level,比如视频帧的尺寸,参考帧的最大数量等,这些参数对整个Video Sequence或者Programme都是通用的。
- PPS(Picture Parameter Set:图像参数集)包含一些通用的参数,比如熵编码类型,有效的参考图像的数目和初始化参数等,这些参数可以应用到一个Video Sequence或者一部分编码帧。
1. SPS 序列参数集
H.264基础知识及视频码流解析_娃哈哈、的博客-CSDN博客
H264 获取SPS与PPS(附源码)_似乎已不再年轻的博客-CSDN博客
2. PPS 图像参数集
H264码流解析_瓜瓜是橘猫的博客-CSDN博客_h264码流解析
H264码流结构分析_chenchong_219的博客-CSDN博客_h264码流
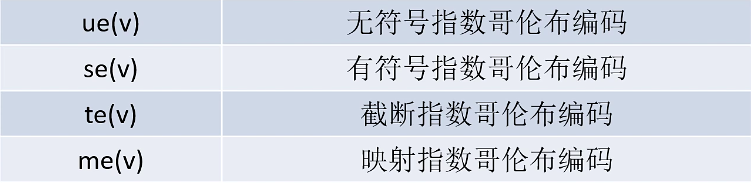
指数哥伦布编码格式
指数哥伦布编码格式是熵编码的一种。熵编码包括的编码方法有:香农-范诺编码、哈夫曼编码、算术编码、指数哥伦布编码、CAVLC、CABAC等。具体实施起来就是,对出现概率较大的符号,取较短的码长,而对出现概率较小的符号取较大的码长。这就是熵编码的中心思想
在计算机中,一般数字的编码都为二进制,但是由于以相等长度来记录不同数字,因此会出现很多的冗余信息,如下:

如数字1,原本只需要1个bit就能表示的数据,如今需要8个bit来表示,那么其余7个bit就可以看做是冗余数据,
在网络传输时,如果以原本等长的编码方式来传输数据,则会出现很大的冗余量,加重网络负担,但是如果只用有效字节来传输上述码流,则会是:10110011111111101,这样根本不能分离出原本的数据,哥伦布编码则是作为一种压缩编码算法,能很有效地对原本的数据进行压缩,并且能很容易地把编码后的码流分离成码字。

编码器

解码器
H.264中定义的指数哥伦布编码共分四类:
无符号指数哥伦布熵编码 示例:
1. 编码过程:
a、将待编码的数加1转换为最小的二进制序列(假设一共M位);
b、此二进制序列前面补充M-1个0;
示例:
对 4 进行无符号指数哥伦布熵编码
1、将4加1(为5)转换为最小的二进制序列即 101 (此是M=3)
2、此二进制序列前面补充M-1个0:即2个0
3、得出的4的无符号指数哥伦布熵编码的序列为 00101
2. 解码过程:
1、获取二进制序列开头连续的N个0
2、读取之后的N+1位的值,假设为X
3、X-1获取解码后的值
示例:
如对 00101进行无符号指数哥伦布熵解码
1、获取开头连续的N个0, 此时N = 2
2、再向后读取N+1位的值,即 101,为5
3、 5 - 1 =4 获取其解码后码值