这篇文章里使用了pythorch提供的量化工具。我首先看到了 pytorch文档的这篇文章,但文档中仅有部分执行文件,我安装环境后,对代码进行修改,并执行到了PQT的部分,但是QAT训练总是报错(可能和我电脑上环境依赖有关系,PQT的执行是需要电脑中cudnn的),然后在查资料的过程中发现了官方提供了docker环境,我安装了docker环境,并得到以下的执行结果(PQT和QAT均能正常执行,后来发现根本还是显存的问题,pytorch TensorRT PQT,QAT +微型版本(小显存)),最后将环境配置成了vscode+docker的模式,以方便我对后续代码的调试。
-
docker pull nvcr.io/nvidia/pytorch:22.05-py3
-
docker run --gpus=all --rm -it --net=host --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 nvcr.io/nvidia/pytorch:22.05-py3 bash
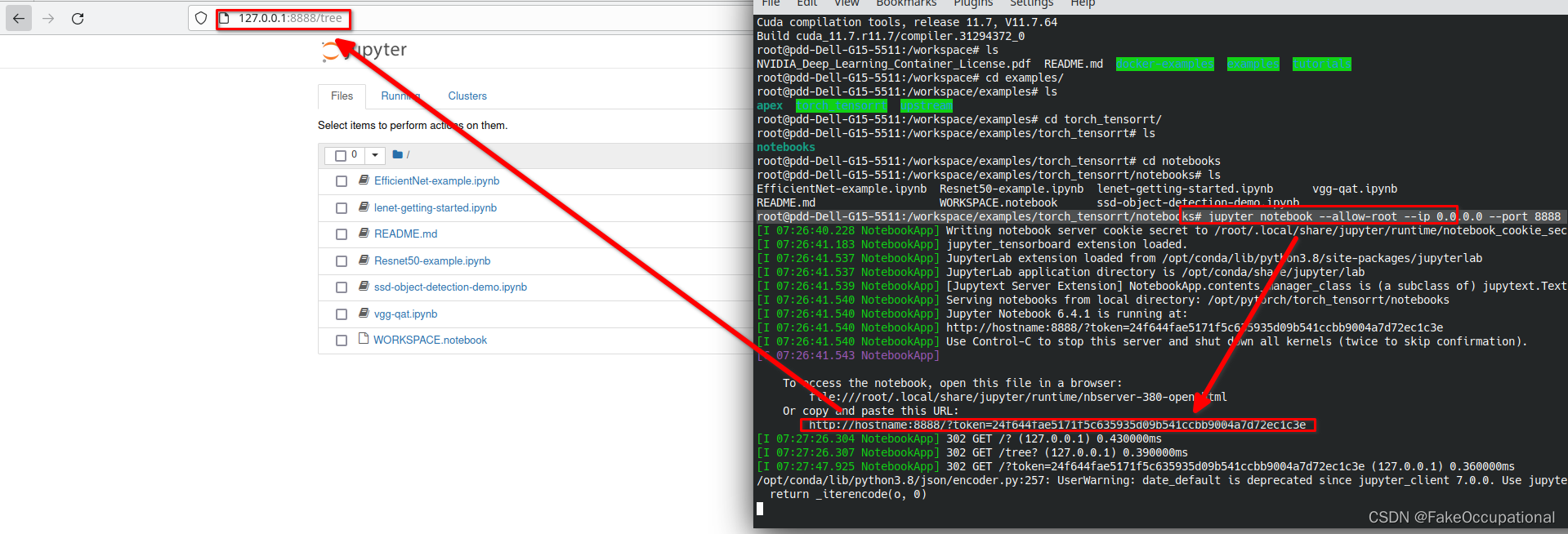
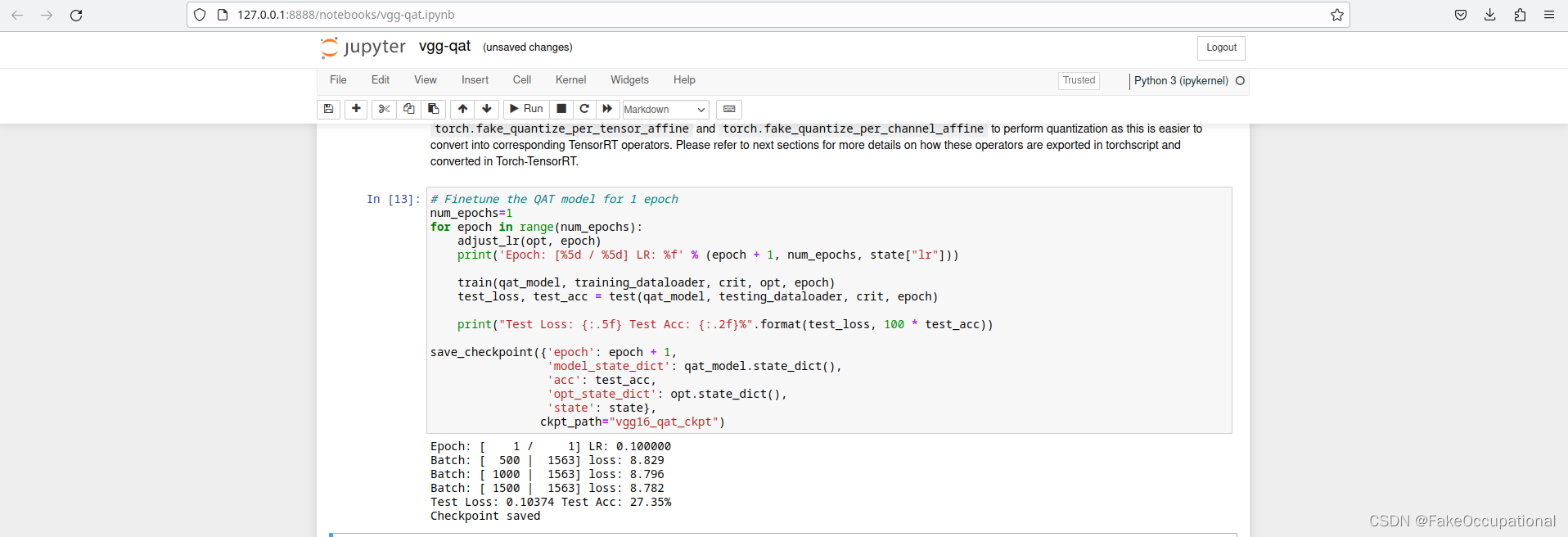
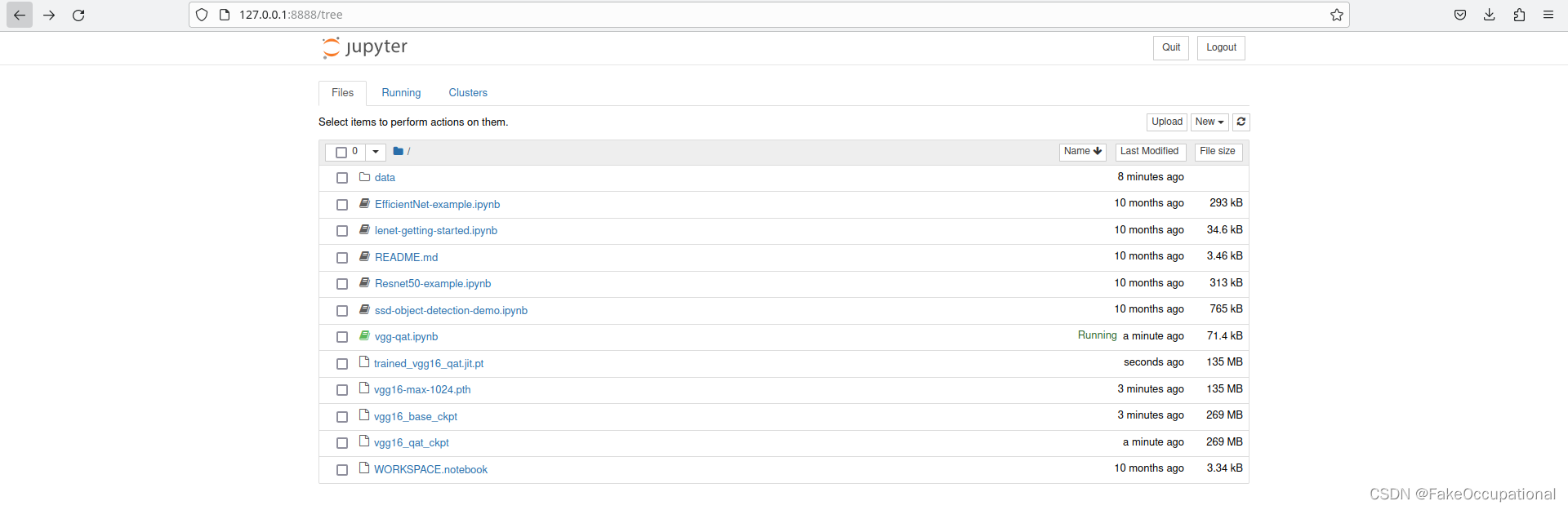
自己安装本地环境(torch-tensorrt 安装)
- 自己安装本地环境需要注意安装的顺序:
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
pip install nvidia-pyindex
pip install nvidia-tensorrt
pip install torch-tensorrt==1.2.0 --find-links https://github.com/pytorch/TensorRT/releases/expanded_assets/v1.2.0
# pip install tensorboard #ModuleNotFoundError: No module named ‘tensorboard
# pip install tqdm
# https://discuss.pytorch.org/t/how-to-install-torch-tensorrt-in-ubuntu/154527/6
- 按照以下的顺序安装会报错
# pip3 install nvidia-pyindex
# pip3 install nvidia-tensorrt -i https://pypi.douban.com/simple
# pip install torch-tensorrt==1.2.0 --find-links https://github.com/pytorch/TensorRT/releases/expanded_assets/v1.2.0 -i https://pypi.doubanio.com/simple
from torch_tensorrt._C import dtype, DeviceType, EngineCapability, TensorFormat
ImportError: libtorch_cuda_cu.so: cannot open shared object file: No such file or directory
简单修改的代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as data
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch_tensorrt
from torch.utils.tensorboard import SummaryWriter
import pytorch_quantization
from pytorch_quantization import nn as quant_nn
from pytorch_quantization import quant_modules
from pytorch_quantization.tensor_quant import QuantDescriptor
from pytorch_quantization import calib
from tqdm import tqdm
print(pytorch_quantization.__version__)
import os
import sys
# sys.path.insert(0, "../examples/int8/training/vgg16")
# print(sys.path)
# from vgg16 import vgg16
import torchvision
vgg16=torchvision.models.vgg16()
print(vgg16)
vgg16.classifier.add_module("add_linear",nn.Linear(1000,10)) # 在vgg16的classfier里加一层
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# ========== Define Training dataset and dataloaders =============#
training_dataset = datasets.CIFAR10(root='./data',
train=True,
download=True,
transform=transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
]))
training_dataloader = torch.utils.data.DataLoader(training_dataset,
batch_size=2,# 32
shuffle=True,
num_workers=2)
# ========== Define Testing dataset and dataloaders =============#
testing_dataset = datasets.CIFAR10(root='./data',
train=False,
download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
]))
testing_dataloader = torch.utils.data.DataLoader(testing_dataset,
batch_size=16,
shuffle=False,
num_workers=2)
def train(model, dataloader, crit, opt, epoch):
# global writer
model.train()
running_loss = 0.0
for batch, (data, labels) in enumerate(dataloader):
data, labels = data.cuda(), labels.cuda(non_blocking=True)
opt.zero_grad()
out = model(data)
loss = crit(out, labels)
loss.backward()
opt.step()
running_loss += loss.item()
if batch % 500 == 499:
print("Batch: [%5d | %5d] loss: %.3f" % (batch + 1, len(dataloader), running_loss / 100))
running_loss = 0.0
def test(model, dataloader, crit, epoch):
global writer
global classes
total = 0
correct = 0
loss = 0.0
class_probs = []
class_preds = []
model.eval()
with torch.no_grad():
for data, labels in dataloader:
data, labels = data.cuda(), labels.cuda(non_blocking=True)
out = model(data)
loss += crit(out, labels)
preds = torch.max(out, 1)[1]
class_probs.append([F.softmax(i, dim=0) for i in out])
class_preds.append(preds)
total += labels.size(0)
correct += (preds == labels).sum().item()
test_probs = torch.cat([torch.stack(batch) for batch in class_probs])
test_preds = torch.cat(class_preds)
return loss / total, correct / total
def save_checkpoint(state, ckpt_path="checkpoint.pth"):
torch.save(state, ckpt_path)
print("Checkpoint saved")
# CIFAR 10 has 10 classes
model = vgg16#(num_classes=len(classes), init_weights=False)
model = model.cuda()
# Declare Learning rate
lr = 0.1
state = {}
state["lr"] = lr
# Use cross entropy loss for classification and SGD optimizer
crit = nn.CrossEntropyLoss()
opt = optim.SGD(model.parameters(), lr=state["lr"], momentum=0.9, weight_decay=1e-4)
# Adjust learning rate based on epoch number
def adjust_lr(optimizer, epoch):
global state
new_lr = lr * (0.5**(epoch // 12)) if state["lr"] > 1e-7 else state["lr"]
if new_lr != state["lr"]:
state["lr"] = new_lr
print("Updating learning rate: {}".format(state["lr"]))
for param_group in optimizer.param_groups:
param_group["lr"] = state["lr"]
# Train the model for 25 epochs to get ~80% accuracy.
if not os.path.exists('vgg16_base_ckpt'):
num_epochs = 2
for epoch in range(num_epochs):
adjust_lr(opt, epoch)
print('Epoch: [%5d / %5d] LR: %f' % (epoch + 1, num_epochs, state["lr"]))
train(model, training_dataloader, crit, opt, epoch)
test_loss, test_acc = test(model, testing_dataloader, crit, epoch)
print("Test Loss: {:.5f} Test Acc: {:.2f}%".format(test_loss, 100 * test_acc))
save_checkpoint({'epoch': epoch + 1,
'model_state_dict': model.state_dict(),
'acc': test_acc,
'opt_state_dict': opt.state_dict(),
'state': state},
ckpt_path="vgg16_base_ckpt")
quant_modules.initialize()
# All the regular conv, FC layers will be converted to their quantozed counterparts due to quant_modules.initialize()
qat_model = vgg16#(num_classes=len(classes), init_weights=False)
qat_model = qat_model.cuda()
# vgg16_base_ckpt is the checkpoint generated from Step 3 : Training a baseline VGG16 model.
ckpt = torch.load("./vgg16_base_ckpt")
modified_state_dict={}
for key, val in ckpt["model_state_dict"].items():
# Remove 'module.' from the key names
if key.startswith('module'):
modified_state_dict[key[7:]] = val
else:
modified_state_dict[key] = val
# Load the pre-trained checkpoint
qat_model.load_state_dict(modified_state_dict)
opt.load_state_dict(ckpt["opt_state_dict"])
def compute_amax(model, **kwargs):
# Load calib result
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
if isinstance(module._calibrator, calib.MaxCalibrator):
module.load_calib_amax()
else:
module.load_calib_amax(**kwargs)
print(F"{name:40}: {module}")
model.cuda()
def collect_stats(model, data_loader, num_batches):
"""Feed data to the network and collect statistics"""
# Enable calibrators
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
module.disable_quant()
module.enable_calib()
else:
module.disable()
# Feed data to the network for collecting stats
for i, (image, _) in tqdm(enumerate(data_loader), total=num_batches):
model(image.cuda())
if i >= num_batches:
break
# Disable calibrators
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
module.enable_quant()
module.disable_calib()
else:
module.enable()
def calibrate_model(model, model_name, data_loader, num_calib_batch, calibrator, hist_percentile, out_dir):
"""
Feed data to the network and calibrate.
Arguments:
model: classification model
model_name: name to use when creating state files
data_loader: calibration data set
num_calib_batch: amount of calibration passes to perform
calibrator: type of calibration to use (max/histogram)
hist_percentile: percentiles to be used for historgram calibration
out_dir: dir to save state files in
"""
if num_calib_batch > 0:
print("Calibrating model")
with torch.no_grad():
collect_stats(model, data_loader, num_calib_batch)
if not calibrator == "histogram":
compute_amax(model, method="max")
calib_output = os.path.join(
out_dir,
F"{model_name}-max-{num_calib_batch*data_loader.batch_size}.pth")
torch.save(model.state_dict(), calib_output)
else:
for percentile in hist_percentile:
print(F"{percentile} percentile calibration")
compute_amax(model, method="percentile")
calib_output = os.path.join(
out_dir,
F"{model_name}-percentile-{percentile}-{num_calib_batch*data_loader.batch_size}.pth")
torch.save(model.state_dict(), calib_output)
for method in ["mse", "entropy"]:
print(F"{method} calibration")
compute_amax(model, method=method)
calib_output = os.path.join(
out_dir,
F"{model_name}-{method}-{num_calib_batch*data_loader.batch_size}.pth")
torch.save(model.state_dict(), calib_output)
#Calibrate the model using max calibration technique.
with torch.no_grad():
calibrate_model(
model=qat_model,
model_name="vgg16",
data_loader=training_dataloader,
num_calib_batch=32,
calibrator="max",
hist_percentile=[99.9, 99.99, 99.999, 99.9999],
out_dir="./")
# Finetune the QAT model for 1 epoch
num_epochs = 1
for epoch in range(num_epochs):
adjust_lr(opt, epoch)
print('Epoch: [%5d / %5d] LR: %f' % (epoch + 1, num_epochs, state["lr"]))
train(qat_model, training_dataloader, crit, opt, epoch)
test_loss, test_acc = test(qat_model, testing_dataloader, crit, epoch)
print("Test Loss: {:.5f} Test Acc: {:.2f}%".format(test_loss, 100 * test_acc))
save_checkpoint({'epoch': epoch + 1,
'model_state_dict': qat_model.state_dict(),
'acc': test_acc,
'opt_state_dict': opt.state_dict(),
'state': state},
ckpt_path="vgg16_qat_ckpt")
输出
2.1.2
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
Files already downloaded and verified
Files already downloaded and verified
Calibrating model
100%|██████████| 32/32 [00:15<00:00, 2.11it/s]
Epoch: [ 1 / 1] LR: 0.100000
Traceback (most recent call last):
File "/home/pdd/PycharmProjects/QAT/main.py", line 302, in <module>
train(qat_model, training_dataloader, crit, opt, epoch)
File "/home/pdd/PycharmProjects/QAT/main.py", line 176, in train
loss.backward()
File "/home/pdd/anaconda3/envs/trt2/lib/python3.8/site-packages/torch/_tensor.py", line 396, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/home/pdd/anaconda3/envs/trt2/lib/python3.8/site-packages/torch/autograd/__init__.py", line 173, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
Traceback (most recent call last):
File "/home/pdd/PycharmProjects/QAT/main.py", line 282, in <module>
train(qat_model, training_dataloader, crit, opt, epoch)
File "/home/pdd/PycharmProjects/QAT/main.py", line 77, in train
loss.backward()
File "/home/pdd/anaconda3/envs/trt2/lib/python3.8/site-packages/torch/_tensor.py", line 396, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/home/pdd/anaconda3/envs/trt2/lib/python3.8/site-packages/torch/autograd/__init__.py", line 173, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
相关资源
- https://github.com/quic/aimet
- https://www.nvidia.com/en-us/on-demand/session/gtcspring21-s31653/
FX
pytorch-lightning
- https://pytorch-lightning.readthedocs.io/en/stable/notebooks/lightning_examples/mnist-hello-world.html
- https://github.com/Lightning-AI/lightning/
openvino
pytorch TensorRT
-
https://pytorch.org/TensorRT/_notebooks/vgg-qat.html
-
https://docs.nvidia.com/deeplearning/tensorrt/pytorch-quantization-toolkit/docs/userguide.html
-
pytorch_quantization.quant_modules Namespace使用猴子补丁的动态模块替换。动态猴子用它们的量化版本修补模块。在内部,
状态由辅助类对象维护,该类对象有助于替换原始状态
模块回来。 -
https://huggingface.co/spaces/Theivaprakasham/yolov6/blob/main/tools/quantization/tensorrt/training_aware/QAT_quantizer.py
-
https://pytorch.org/TensorRT/getting_started/installation.html
-
https://blog.csdn.net/leviopku/article/details/112963733
-
https://zhuanlan.zhihu.com/p/361094949 QAT