大模型训练加速(FlashAttention): 用于训练LLM的GPU加速的一个进展-PART2
机器AI学习 数据AI挖掘 2023-11-09 11:27 Posted on 江苏
在快速发展的大型语言模型中,对更快、更高效的模型的追求是永无止境的。最近,LLM领域的一个革命性概念引起了极大的关注,即FlashAttention。这个概念,通常被称为FlashAttention V1,是一种有望显著加速在GPU上训练LLM的技术。
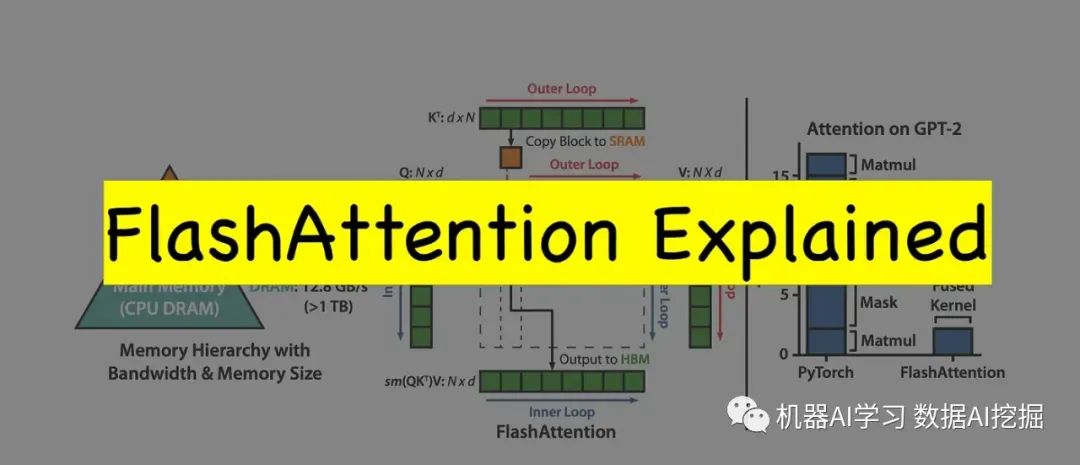
在这篇博客文章中,我们将深入研究FlashAttention的复杂性、其核心概念,以及它被认为是深度学习模型GPU加速的进步的原因。
快速回顾
在我们深入了解FlashAttention的细节之前,让我们回顾一下与GPU架构和深度学习相关的一些基本概念。在FlashAttention系列的第1部分中,我们探讨了从硬盘到主存再到GPU的数据流。我们还讨论了GPU中使用的各种术语,并探讨了内存层次结构的概念。如果您需要更详细的解释,建议您阅读本系列的第1部分。
此外,了解自我关注在变形金刚中的作用至关重要。自我注意是变压器中的一种基本操作,其固有的时间和记忆复杂性为O(n²)。要理解FlashAttention的意义,必须有坚实的基础。如果您需要更详细的解释,建议您浏览此视频。
什么是FlashAttention?
Flash Attention是优化注意力机制的突破,注意力机制是基于Transformer的模型的关键组成部分。注意力机制负责学习输入序列不同部分之间的关系。在传统的自我注意中,时间和记忆的复杂性是O(n²),这可能是训练深度学习模型的主要瓶颈。
另一方面,FlashAttention提供了一种替代方法,有望比传统的自我关注快3倍。它通过利用GPU架构的强大功能并有效利用张量核或CUDA核来实现这一点。事实上,FlashAttention V2声称比前代快2倍,可能比标准注意力机制快6倍。
FlashAttention的核心概念
FlashAttention的神奇之处在于它的核心概念,即平铺和重新计算。这些概念共同作用以减少对GPU的高带宽存储器(HBM)的读写注意力权重的需要。让我们仔细看看这两种机制:
Tiling:Tiling包括将Q(Query)、K(Key)和V(Value)矩阵拆分为更小的块或块。这些块被加载到更快的片上SRAM(静态随机存取存储器)中,并在块级别进行处理,从而减少了对HBM的频繁存储器访问的需要。
推荐:另一方面,在后传球时使用推荐,这对LLM的训练至关重要。代替从HBM读取用于反向传播的注意力权重,
FlashAttention在片上SRAM中有效地重新计算权重,这明显更快。这增加了浮点运算(flops)的数量,但减少了内存访问的数量,从而减少了墙上的时钟时间
内核融合:提高效率
内核融合是提高FlashAttention效率的另一个关键因素。它包括将多个函数组合为在CUDA内核上执行的单个函数(内核)。这种功能的融合减少了对多个存储器访问的需要,并提高了模型的整体效率。
训练速度和质量
FlashAttention的优点之一是它对训练速度的影响。训练LLM,像GPT-2和GPT-3这样的巨头,通过FlashAttention变得明显更快。在某些情况下,训练速度提高了15%,使其成为研究人员和开发人员的宝贵工具。
此外,FlashAttention可以在较长的序列上训练模型。更长的序列可以产生更高质量的模型,这是在各种自然语言处理任务中获得最先进结果的一个显著优势。
局限性和未来前景
虽然FlashAttention V1在深度学习的GPU加速方面取得了进步,但它也有局限性。一些挑战包括缺乏针对CUDA的明确功能以及需要多GPU支持。然而,正在进行的研究和FlashAttention V2的出现可能会解决其中的许多局限性。
结论
FlashAttention是深度学习领域的一个显著进步。优化注意力机制,减少内存访问,加快训练速度,为希望突破LLM界限的研究人员和开发人员打开了新的大门。
在本系列的第3部分中,我们将深入研究Flash Attention算法,研究其复杂性、实现细节和实际应用.