文章目录
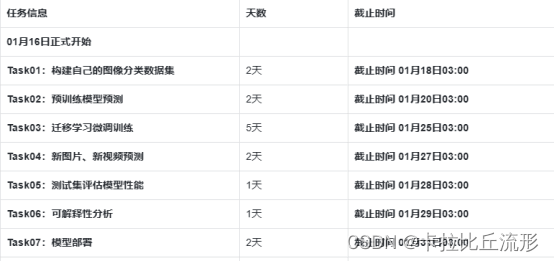
【教程地址】
同济子豪兄教学视频:https://space.bilibili.com/1900783/channel/collectiondetail?sid=606800
项目代码:https://github.com/TommyZihao/Train_Custom_Dataset
配置环境
# 下载安装依赖包
pip install numpy pandas matplotlib requests tqdm opencv-python pillow
# 下载安装Pytorch
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
# 安装mmcv -full
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10.0/index.html
创建目录
# 存放测试图片
os.mkdir('test_img')
# 存放结果文件
os.mkdir('output')
# 存放训练得到的模型权重
os.mkdir('checkpoints')
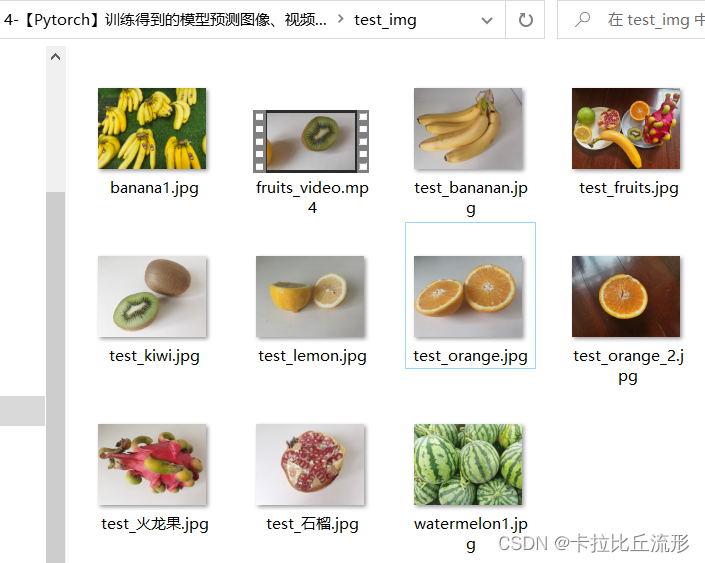
下载在三、利用迁移学习进行模型微调(Datawhale组队学习)得到的模型文件fruit30_pytorch_20230123.pth和“类别名称和ID索引号”的映射字典文件idx_to_labels.npy,如果没有也可以通过以下方式进行下载。最后下载一些图片和视频的测试文件存放在test_img文件夹中
# 下载样例模型文件
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/checkpoints/fruit30_pytorch_20220814.pth -P checkpoints
# 下载 类别名称 和 ID索引号 的映射字典
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/fruit30/idx_to_labels.npy
# 下载测试图像文件 至 test_img 文件夹
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_fruits.jpg -P test_img
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_orange_2.jpg -P test_img
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_bananan.jpg -P test_img
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_kiwi.jpg -P test_img
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_石榴.jpg -P test_img
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_orange.jpg -P test_img
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_lemon.jpg -P test_img
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_火龙果.jpg -P test_img
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/test/watermelon1.jpg -P test_img
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/test/banana1.jpg -P test_img
# 下载测试视频文件 至 test_img 文件夹
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/fruits_video.mp4 -P test_img
设置中文字体正常显示并测试一下
import matplotlib.pyplot as plt
%matplotlib inline
# windows操作系统
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
plt.plot([1,2,3], [100,500,300])
plt.title('matplotlib中文字体测试', fontsize=25)
plt.xlabel('X轴', fontsize=15)
plt.ylabel('Y轴', fontsize=15)
plt.show()

预测新图像
导入所需的工具包,并设置中文字体
import torch
import torchvision
import torch.nn.functional as F
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# windows操作系统设置中文字体
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
#导入pillow中文字体
from PIL import Image, ImageFont, ImageDraw
# 导入中文字体,指定字号
font = ImageFont.truetype('SimHei.ttf', 32)
载入图像并进行预处理
载入类别
idx_to_labels = np.load('idx_to_labels.npy', allow_pickle=True).item()
print(idx_to_labels)
{0: ‘哈密瓜’, 1: ‘圣女果’, 2: ‘山竹’, 3: ‘杨梅’, 4: ‘柚子’, 5: ‘柠檬’, 6: ‘桂圆’, 7: ‘梨’, 8: ‘椰子’, 9: ‘榴莲’, 10: ‘火龙果’, 11: ‘猕猴桃’, 12: ‘石榴’, 13: ‘砂糖橘’, 14: ‘胡萝卜’, 15: ‘脐橙’, 16: ‘芒果’, 17: ‘苦瓜’, 18: ‘苹果-红’, 19: ‘苹果-青’, 20: ‘草莓’, 21: ‘荔枝’, 22: ‘菠萝’, 23: ‘葡萄-白’, 24: ‘葡萄-红’, 25: ‘西瓜’, 26: ‘西红柿’, 27: ‘车厘子’, 28: ‘香蕉’, 29: ‘黄瓜’}
载入一张测试图片并对图片进行预处理
from PIL import Image
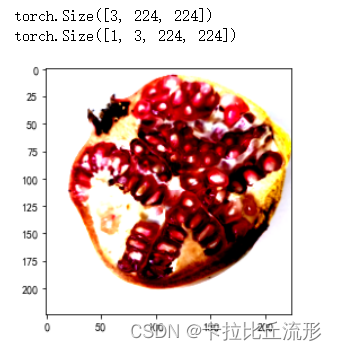
img_path = 'test_img/test_石榴.jpg'
img_pil = Image.open(img_path)
input_img = test_transform(img_pil) # 预处理
print(input_img.shape)
images = input_img.numpy()
plt.imshow(images.transpose((1,2,0))) # 转为(224, 224, 3)
input_img = input_img.unsqueeze(0).to(device)
print(input_img.shape)
导入训练好的模型
这里要注意训练的模型是用CPU版本训练得到的,而现在用GPU版本导入可能会报错,大家一定要注意版本的统一
model = torch.load('checkpoints/fruit30_pytorch_20230123.pth')
model = model.eval().to(device)#调成评估状态并加入到计算设备里面
前向预测
得到预测为各个类别的概率
# 执行前向预测,得到所有类别的 logit 预测分数
pred_logits = model(input_img)
# 对 logit 分数做 softmax 运算
pred_softmax = F.softmax(pred_logits, dim=1)
tensor([[1.5778e-07, 2.4981e-05, 2.5326e-05, 3.8147e-05, 6.1754e-05, 3.5412e-07,
3.0071e-07, 2.2314e-08, 6.2592e-07, 3.9356e-09, 5.2626e-06, 2.3320e-08,
9.9664e-01, 1.9379e-07, 3.9359e-08, 3.8175e-08, 4.4834e-06, 8.2782e-07,
1.9294e-04, 2.3078e-08, 2.7421e-04, 3.1726e-04, 1.0331e-05, 2.2196e-08,
5.5011e-04, 6.8984e-05, 1.5381e-04, 1.6270e-03, 6.9369e-07, 1.3640e-08]],
grad_fn=)
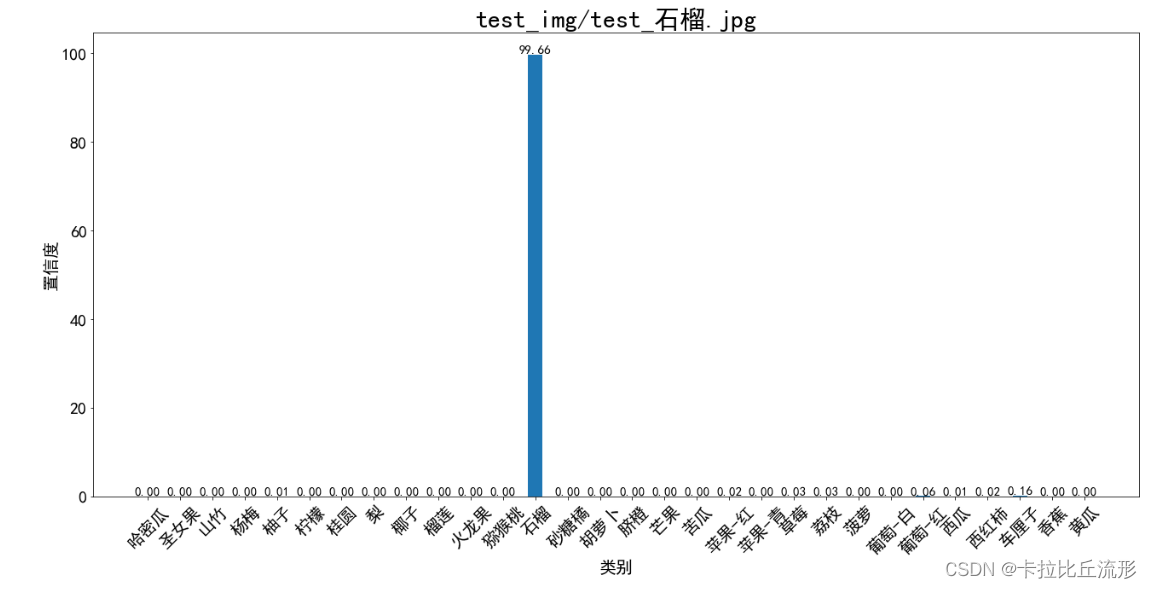
对预测结果进行可视化
plt.figure(figsize=(22, 10))
x = idx_to_labels.values()
y = pred_softmax.cpu().detach().numpy()[0] * 100
width = 0.45 # 柱状图宽度
ax = plt.bar(x, y, width)
plt.bar_label(ax, fmt='%.2f', fontsize=15) # 置信度数值
plt.tick_params(labelsize=20) # 设置坐标文字大小
plt.title(img_path, fontsize=30)
plt.xticks(rotation=45) # 横轴文字旋转
plt.xlabel('类别', fontsize=20)
plt.ylabel('置信度', fontsize=20)
plt.show()
将分类结果写入原图中
得到置信度最大的前10个结果
n = 10
top_n = torch.topk(pred_softmax, n) # 取置信度最大的 n 个结果
pred_ids = top_n[1].cpu().detach().numpy().squeeze() # 解析出类别
confs = top_n[0].cpu().detach().numpy().squeeze() # 解析出置信度
print(pred_ids)
print(confs)
[12 27 24 21 20 18 26 25 4 3]
[9.9664199e-01 1.6270019e-03 5.5011164e-04 3.1726481e-04 2.7420817e-04
1.9294333e-04 1.5380539e-04 6.8983565e-05 6.1754021e-05 3.8146878e-05]
将分类结果写在原图上
draw = ImageDraw.Draw(img_pil)
for i in range(n):
class_name = idx_to_labels[pred_ids[i]] # 获取类别名称
confidence = confs[i] * 100 # 获取置信度
text = '{:<15} {:>.4f}'.format(class_name, confidence)
print(text)
# 文字坐标,中文字符串,字体,rgba颜色
draw.text((50, 100 + 50 * i), text, font=font, fill=(255, 0, 0, 1))
img_pil
石榴 99.6642
车厘子 0.1627
葡萄-红 0.0550
荔枝 0.0317
草莓 0.0274
苹果-红 0.0193
西红柿 0.0154
西瓜 0.0069
柚子 0.0062
杨梅 0.0038
预测结果图和分类柱状图

fig = plt.figure(figsize=(18,6))
# 绘制左图-预测图
ax1 = plt.subplot(1,2,1)
ax1.imshow(img_pil)
ax1.axis('off')
# 绘制右图-柱状图
ax2 = plt.subplot(1,2,2)
x = idx_to_labels.values()
y = pred_softmax.cpu().detach().numpy()[0] * 100
ax2.bar(x, y, alpha=0.5, width=0.3, color='yellow', edgecolor='red', lw=3)
plt.bar_label(ax, fmt='%.2f', fontsize=10) # 置信度数值
plt.title('{} 图像分类预测结果'.format(img_path), fontsize=30)
plt.xlabel('类别', fontsize=20)
plt.ylabel('置信度', fontsize=20)
plt.ylim([0, 110]) # y轴取值范围
ax2.tick_params(labelsize=16) # 坐标文字大小
plt.xticks(rotation=90) # 横轴文字旋转
plt.tight_layout()
fig.savefig('output/预测图+柱状图.jpg')
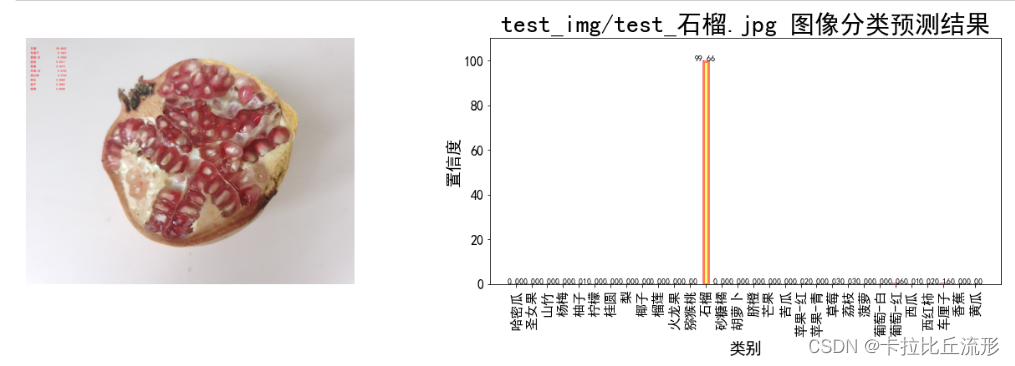
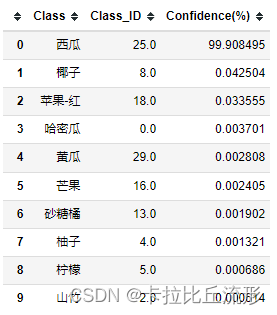
将预测结果以表格形式输出
pred_df = pd.DataFrame() # 预测结果表格
for i in range(n):
class_name = idx_to_labels[pred_ids[i]] # 获取类别名称
label_idx = int(pred_ids[i]) # 获取类别号
confidence = confs[i] * 100 # 获取置信度
pred_df = pred_df.append({
'Class':class_name, 'Class_ID':label_idx, 'Confidence(%)':confidence}, ignore_index=True) # 预测结果表格添加一行
display(pred_df) # 展示预测结果表格
预测新视频
import os
import time
import shutil
import tempfile
from tqdm import tqdm
import cv2
from PIL import Image
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
import gc
import torch
import torch.nn.functional as F
from torchvision import models
import mmcv
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device:', device)
# 后端绘图,不显示,只保存
import matplotlib
matplotlib.use('Agg')
# windows操作系统
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
from PIL import ImageFont, ImageDraw
# 导入中文字体,指定字号
font = ImageFont.truetype('SimHei.ttf', 32)
导入训练好的模型
model = torch.load('checkpoints/fruit30_pytorch_20230123.pth')
model = model.eval().to(device)
视频预测
输入输出视频路径
input_video = 'test_img/fruits_video.mp4'
# 创建临时文件夹,存放每帧结果
temp_out_dir = time.strftime('%Y%m%d%H%M%S')
os.mkdir(temp_out_dir)
print('创建临时文件夹 {} 用于存放每帧预测结果'.format(temp_out_dir))
载入类别
idx_to_labels = np.load('idx_to_labels.npy', allow_pickle=True).item()
图像预处理
from torchvision import transforms
# 测试集图像预处理-RCTN:缩放裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
单帧图像分类预测
图像分类预测函数
def pred_single_frame(img, n=5):
'''
输入摄像头画面bgr-array,输出前n个图像分类预测结果的图像bgr-array
'''
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR 转 RGB
img_pil = Image.fromarray(img_rgb) # array 转 pil
input_img = test_transform(img_pil).unsqueeze(0).to(device) # 预处理
pred_logits = model(input_img) # 执行前向预测,得到所有类别的 logit 预测分数
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
top_n = torch.topk(pred_softmax, n) # 取置信度最大的 n 个结果
pred_ids = top_n[1].cpu().detach().numpy().squeeze() # 解析出类别
confs = top_n[0].cpu().detach().numpy().squeeze() # 解析出置信度
# 在图像上写字
draw = ImageDraw.Draw(img_pil)
# 在图像上写字
for i in range(len(confs)):
pred_class = idx_to_labels[pred_ids[i]]
text = '{:<15} {:>.3f}'.format(pred_class, confs[i])
# 文字坐标,中文字符串,字体,rgba颜色
draw.text((50, 100 + 50 * i), text, font=font, fill=(255, 0, 0, 1))
img_bgr = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR) # RGB转BGR
return img_bgr, pred_softmax
可视化方案一:原始图像+预测结果文字
# 读入待预测视频
imgs = mmcv.VideoReader(input_video)
prog_bar = mmcv.ProgressBar(len(imgs))
# 对视频逐帧处理
for frame_id, img in enumerate(imgs):
## 处理单帧画面
img, pred_softmax = pred_single_frame(img, n=5)
# 将处理后的该帧画面图像文件,保存至 /tmp 目录下
cv2.imwrite(f'{
temp_out_dir}/{
frame_id:06d}.jpg', img)
prog_bar.update() # 更新进度条
# 把每一帧串成视频文件
mmcv.frames2video(temp_out_dir, 'output/output_pred.mp4', fps=imgs.fps, fourcc='mp4v')
shutil.rmtree(temp_out_dir) # 删除存放每帧画面的临时文件夹
print('删除临时文件夹', temp_out_dir)

可视化方案二:原始图像+预测结果文字+各类别置信度柱状图
def pred_single_frame_bar(img):
'''
输入pred_single_frame函数输出的bgr-array,加柱状图,保存
'''
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR 转 RGB
fig = plt.figure(figsize=(18,6))
# 绘制左图-视频图
ax1 = plt.subplot(1,2,1)
ax1.imshow(img)
ax1.axis('off')
# 绘制右图-柱状图
ax2 = plt.subplot(1,2,2)
x = idx_to_labels.values()
y = pred_softmax.cpu().detach().numpy()[0] * 100
ax2.bar(x, y, alpha=0.5, width=0.3, color='yellow', edgecolor='red', lw=3)
plt.xlabel('类别', fontsize=20)
plt.ylabel('置信度', fontsize=20)
ax2.tick_params(labelsize=16) # 坐标文字大小
plt.ylim([0, 100]) # y轴取值范围
plt.xlabel('类别',fontsize=25)
plt.ylabel('置信度',fontsize=25)
plt.title('图像分类预测结果', fontsize=30)
plt.xticks(rotation=90) # 横轴文字旋转
plt.tight_layout()
fig.savefig(f'{
temp_out_dir}/{
frame_id:06d}.jpg')
# 释放内存
fig.clf()
plt.close()
gc.collect()
# 读入待预测视频
imgs = mmcv.VideoReader(input_video)
prog_bar = mmcv.ProgressBar(len(imgs))
# 对视频逐帧处理
for frame_id, img in enumerate(imgs):
## 处理单帧画面
img, pred_softmax = pred_single_frame(img, n=5)
img = pred_single_frame_bar(img)
prog_bar.update() # 更新进度条
# 把每一帧串成视频文件
mmcv.frames2video(temp_out_dir, 'output/output_bar.mp4', fps=imgs.fps, fourcc='mp4v')
shutil.rmtree(temp_out_dir) # 删除存放每帧画面的临时文件夹
print('删除临时文件夹', temp_out_dir)
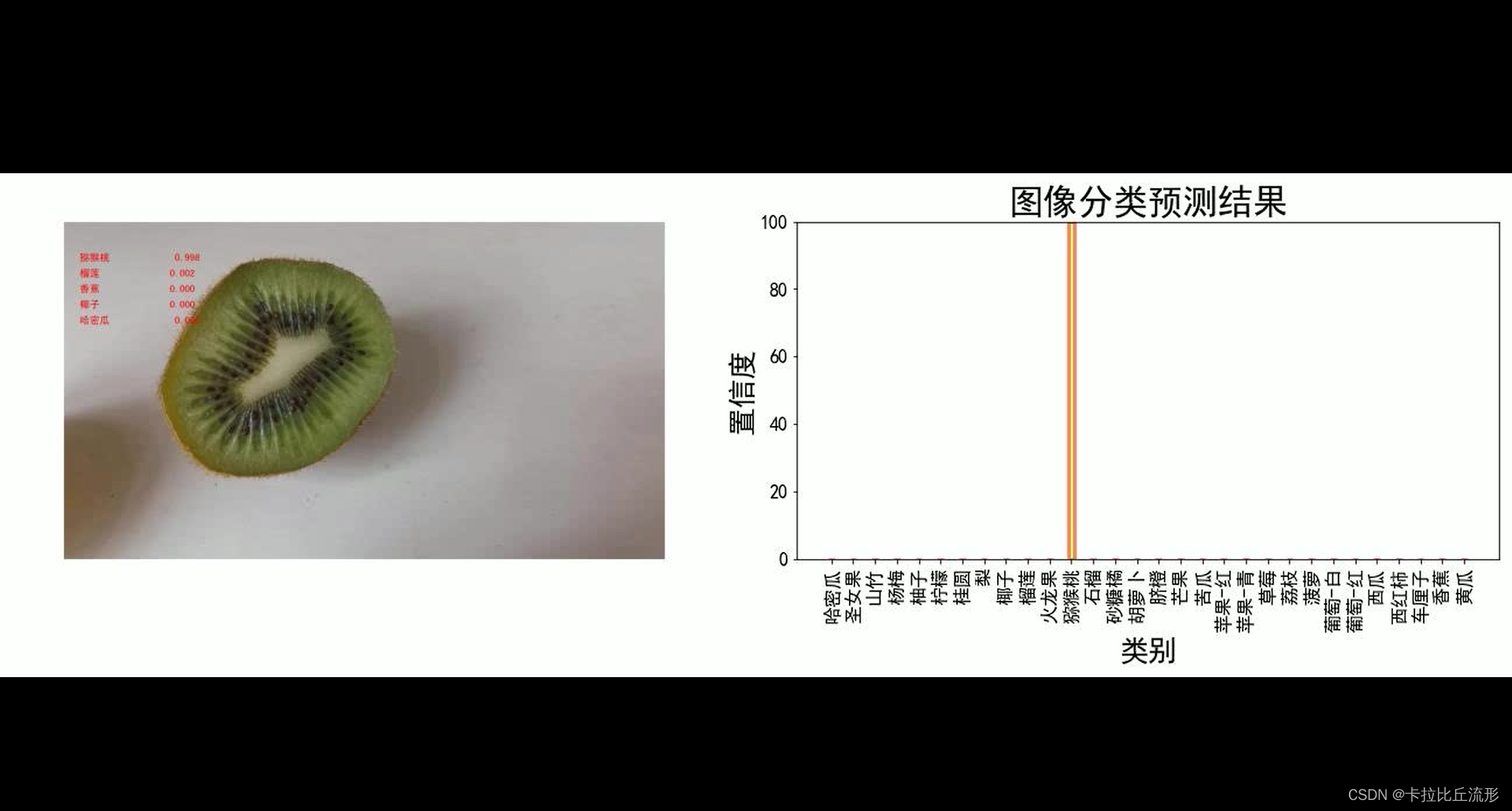
预测摄像头实时画面
导入依赖工具包
import os
import numpy as np
import pandas as pd
import cv2 # opencv-python
from PIL import Image, ImageFont, ImageDraw
from tqdm import tqdm # 进度条
import matplotlib.pyplot as plt
%matplotlib inline
import torch
import torch.nn.functional as F
from torchvision import models
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device:', device)
导入中文字体,指定字号
font = ImageFont.truetype('SimHei.ttf', 32)
载入类别
idx_to_labels = np.load('idx_to_labels.npy', allow_pickle=True).item()
{0: ‘哈密瓜’, 1: ‘圣女果’, 2: ‘山竹’, 3: ‘杨梅’, 4: ‘柚子’, 5: ‘柠檬’, 6: ‘桂圆’, 7: ‘梨’, 8: ‘椰子’, 9: ‘榴莲’, 10: ‘火龙果’, 11: ‘猕猴桃’, 12: ‘石榴’, 13: ‘砂糖橘’, 14: ‘胡萝卜’, 15: ‘脐橙’, 16: ‘芒果’, 17: ‘苦瓜’, 18: ‘苹果-红’, 19: ‘苹果-青’, 20: ‘草莓’, 21: ‘荔枝’, 22: ‘菠萝’, 23: ‘葡萄-白’, 24: ‘葡萄-红’, 25: ‘西瓜’, 26: ‘西红柿’, 27: ‘车厘子’, 28: ‘香蕉’, 29: ‘黄瓜’}
图像预处理
from torchvision import transforms
# 测试集图像预处理-RCTN:缩放裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
导入训练好的模型
model = torch.load('checkpoints/fruit30_pytorch_20230123.pth', map_location=torch.device('cpu'))
model = model.eval().to(device)
对一帧画面进行预测
获取摄像头的一帧画面
# 导入opencv-python
import cv2
import time
# 获取摄像头,传入0表示获取系统默认摄像头
cap = cv2.VideoCapture(1)
# 打开cap
cap.open(0)
time.sleep(1)
success, img_bgr = cap.read()
# 关闭摄像头
cap.release()
# 关闭图像窗口
cv2.destroyAllWindows()
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) # BGR转RGB
img_pil = Image.fromarray(img_rgb)
img_pil

对画面进行预测
input_img = test_transform(img_pil).unsqueeze(0).to(device) # 预处理
pred_logits = model(input_img) # 执行前向预测,得到所有类别的 logit 预测分数
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
n = 5
top_n = torch.topk(pred_softmax, n) # 取置信度最大的 n 个结果
pred_ids = top_n[1].cpu().detach().numpy().squeeze() # 解析出类别
confs = top_n[0].cpu().detach().numpy().squeeze() # 解析出置信度
draw = ImageDraw.Draw(img_pil)
# 在图像上写字
for i in range(len(confs)):
pred_class = idx_to_labels[pred_ids[i]]
text = '{:<15} {:>.3f}'.format(pred_class, confs[i])
# 文字坐标,中文字符串,字体,rgba颜色
draw.text((50, 100 + 50 * i), text, font=font, fill=(255, 0, 0, 1))
img = np.array(img_pil) # PIL 转 array
plt.imshow(img)
plt.show()

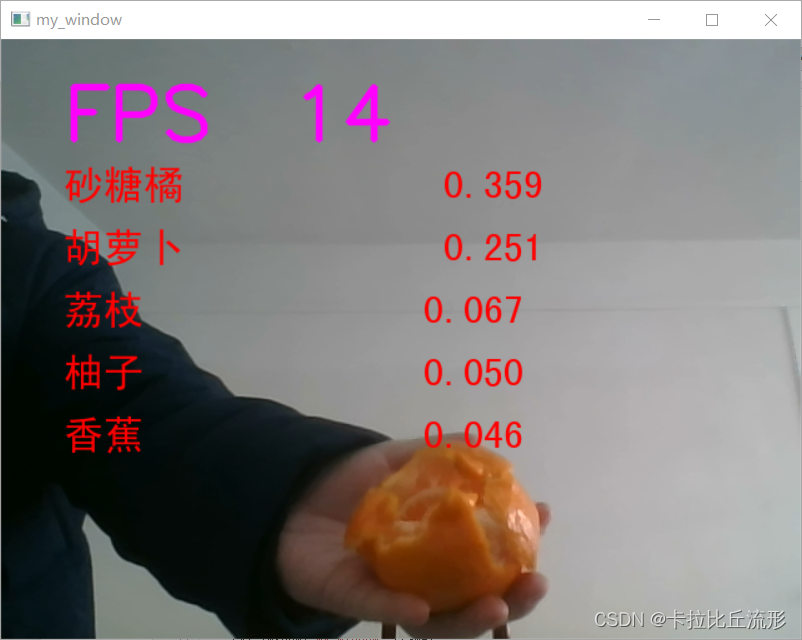
实时画面预测
处理单帧画面的函数
# 处理帧函数
def process_frame(img):
# 记录该帧开始处理的时间
start_time = time.time()
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR转RGB
img_pil = Image.fromarray(img_rgb) # array 转 PIL
input_img = test_transform(img_pil).unsqueeze(0).to(device) # 预处理
pred_logits = model(input_img) # 执行前向预测,得到所有类别的 logit 预测分数
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
top_n = torch.topk(pred_softmax, 5) # 取置信度最大的 n 个结果
pred_ids = top_n[1].cpu().detach().numpy().squeeze() # 解析预测类别
confs = top_n[0].cpu().detach().numpy().squeeze() # 解析置信度
# 使用PIL绘制中文
draw = ImageDraw.Draw(img_pil)
# 在图像上写字
for i in range(len(confs)):
pred_class = idx_to_labels[pred_ids[i]]
text = '{:<15} {:>.3f}'.format(pred_class, confs[i])
# 文字坐标,中文字符串,字体,bgra颜色
draw.text((50, 100 + 50 * i), text, font=font, fill=(255, 0, 0, 1))
img = np.array(img_pil) # PIL 转 array
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) # RGB转BGR
# 记录该帧处理完毕的时间
end_time = time.time()
# 计算每秒处理图像帧数FPS
FPS = 1/(end_time - start_time)
# 图片,添加的文字,左上角坐标,字体,字体大小,颜色,线宽,线型
img = cv2.putText(img, 'FPS '+str(int(FPS)), (50, 80), cv2.FONT_HERSHEY_SIMPLEX, 2, (255, 0, 255), 4, cv2.LINE_AA)
return img
调用摄像头获取每帧
# 调用摄像头逐帧实时处理模板
# 不需修改任何代码,只需修改process_frame函数即可
# 同济子豪兄 2021-7-8
# 导入opencv-python
import cv2
import time
# 获取摄像头,传入0表示获取系统默认摄像头
cap = cv2.VideoCapture(1)
# 打开cap
cap.open(0)
# 无限循环,直到break被触发
while cap.isOpened():
# 获取画面
success, frame = cap.read()
if not success:
print('Error')
break
## !!!处理帧函数
frame = process_frame(frame)
# 展示处理后的三通道图像
cv2.imshow('my_window',frame)
if cv2.waitKey(1) in [ord('q'),27]: # 按键盘上的q或esc退出(在英文输入法下)
break
# 关闭摄像头
cap.release()
# 关闭图像窗口
cv2.destroyAllWindows()
总结
本篇文章主要讲述了如何利用上次三、利用迁移学习进行模型微调(Datawhale组队学习)得到的图像分类模型,分别在新的图像文件、新的视频文件和摄像头实时画面上进行预测。
!!!注意:如果之前的图像分类模型是在CPU上训练得到的,这里用GPU版的pytorch导入模型的时候可能会出错,大家一定要注意版本的统一。