文章目录
安装配置环境
下载相应的包
pip install numpy pandas matplotlib seaborn plotly requests tqdm opencv-python pillow wandb
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
下载字体,使用Linux的wget命令,也可以复制链接进行下载
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/SimHei.ttf --no-check-certificate
创建目录
import os
# 存放结果文件
os.mkdir('output')
# 存放训练得到的模型权重
os.mkdir('checkpoints')
# 存放生成的图表
os.mkdir('图表')
设置中文字体
import matplotlib.pyplot as plt
%matplotlib inline
# windows操作系统
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
# Mac操作系统,参考 https://www.ngui.cc/51cto/show-727683.html
# 下载 simhei.ttf 字体文件
# !wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/SimHei.ttf
# Linux操作系统,例如 云GPU平台:https://featurize.cn/?s=d7ce99f842414bfcaea5662a97581bd1
# 如果报错 Unable to establish SSL connection.,重新运行本代码块即可
# !wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/SimHei.ttf -O /environment/miniconda3/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/SimHei.ttf --no-check-certificate
# !rm -rf /home/featurize/.cache/matplotlib
# import matplotlib
# import matplotlib.pyplot as plt
# %matplotlib inline
# matplotlib.rc("font",family='SimHei') # 中文字体
# plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
准备图像分类数据集
# 下载数据集压缩包
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/fruit30/fruit30_split.zip
# 解压
!unzip fruit30_split.zip >> /dev/null
# 删除压缩包
!rm fruit30_split.zip
迁移学习微调训练图像分类模型
导入环境
# 导入工具包
import time
import os
import numpy as np
from tqdm import tqdm
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
%matplotlib inline
# 忽略烦人的红色提示
import warnings
warnings.filterwarnings("ignore")
# 设置matplotlib中文字体
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
# 获取计算硬件
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)
图像预处理
from torchvision import transforms
# 训练集图像预处理:缩放裁剪、图像增强、转 Tensor、归一化
train_transform = transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),#随机的水平翻转
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 测试集图像预处理-RCTN:缩放、裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
载入图像分类数据集
设置数据集的文件路径
# 数据集文件夹路径
dataset_dir = 'fruit30_split'
train_path = os.path.join(dataset_dir, 'train')
test_path = os.path.join(dataset_dir, 'val')
print('训练集路径', train_path)
print('测试集路径', test_path)
训练集路径 fruit30_split\train
测试集路径 fruit30_split\val
导入测试集和训练集
from torchvision import datasets
# 载入训练集
train_dataset = datasets.ImageFolder(train_path, train_transform)
# 载入测试集
test_dataset = datasets.ImageFolder(test_path, test_transform)
查看训练集的图像信息
print('训练集图像数量', len(train_dataset))
print('类别个数', len(train_dataset.classes))
print('各类别名称', train_dataset.classes)
训练集图像数量 4375
类别个数 30
各类别名称 [‘哈密瓜’, ‘圣女果’, ‘山竹’, ‘杨梅’, ‘柚子’, ‘柠檬’, ‘桂圆’, ‘梨’, ‘椰子’, ‘榴莲’, ‘火龙果’, ‘猕猴桃’, ‘石榴’, ‘砂糖橘’, ‘胡萝卜’, ‘脐橙’, ‘芒果’, ‘苦瓜’, ‘苹果-红’, ‘苹果-青’, ‘草莓’, ‘荔枝’, ‘菠萝’, ‘葡萄-白’, ‘葡萄-红’, ‘西瓜’, ‘西红柿’, ‘车厘子’, ‘香蕉’, ‘黄瓜’]
查看测试集的图像信息
print('测试集图像数量', len(test_dataset))
print('类别个数', len(test_dataset.classes))
print('各类别名称', test_dataset.classes)
测试集图像数量 1078
类别个数 30
各类别名称 [‘哈密瓜’, ‘圣女果’, ‘山竹’, ‘杨梅’, ‘柚子’, ‘柠檬’, ‘桂圆’, ‘梨’, ‘椰子’, ‘榴莲’, ‘火龙果’, ‘猕猴桃’, ‘石榴’, ‘砂糖橘’, ‘胡萝卜’, ‘脐橙’, ‘芒果’, ‘苦瓜’, ‘苹果-红’, ‘苹果-青’, ‘草莓’, ‘荔枝’, ‘菠萝’, ‘葡萄-白’, ‘葡萄-红’, ‘西瓜’, ‘西红柿’, ‘车厘子’, ‘香蕉’, ‘黄瓜’]
建立类别和索引号之间映射关系
# 映射关系:类别 到 索引号
print(train_dataset.class_to_idx)
# 映射关系:索引号 到 类别
idx_to_labels = {
y:x for x,y in train_dataset.class_to_idx.items()}
print(idx_to_labels)
# 保存为本地的 npy 文件
np.save('idx_to_labels.npy', idx_to_labels)
np.save('labels_to_idx.npy', train_dataset.class_to_idx)
{‘哈密瓜’: 0, ‘圣女果’: 1, ‘山竹’: 2, ‘杨梅’: 3, ‘柚子’: 4, ‘柠檬’: 5, ‘桂圆’: 6, ‘梨’: 7, ‘椰子’: 8, ‘榴莲’: 9, ‘火龙果’: 10, ‘猕猴桃’: 11, ‘石榴’: 12, ‘砂糖橘’: 13, ‘胡萝卜’: 14, ‘脐橙’: 15, ‘芒果’: 16, ‘苦瓜’: 17, ‘苹果-红’: 18, ‘苹果-青’: 19, ‘草莓’: 20, ‘荔枝’: 21, ‘菠萝’: 22, ‘葡萄-白’: 23, ‘葡萄-红’: 24, ‘西瓜’: 25, ‘西红柿’: 26, ‘车厘子’: 27, ‘香蕉’: 28, ‘黄瓜’: 29}
{0: ‘哈密瓜’, 1: ‘圣女果’, 2: ‘山竹’, 3: ‘杨梅’, 4: ‘柚子’, 5: ‘柠檬’, 6: ‘桂圆’, 7:
‘梨’, 8: ‘椰子’, 9: ‘榴莲’, 10: ‘火龙果’, 11: ‘猕猴桃’, 12: ‘石榴’, 13: ‘砂糖橘’, 14:
‘胡萝卜’, 15: ‘脐橙’, 16: ‘芒果’, 17: ‘苦瓜’, 18: ‘苹果-红’, 19: ‘苹果-青’, 20: ‘草莓’,
21: ‘荔枝’, 22: ‘菠萝’, 23: ‘葡萄-白’, 24: ‘葡萄-红’, 25: ‘西瓜’, 26: ‘西红柿’, 27:
‘车厘子’, 28: ‘香蕉’, 29: ‘黄瓜’}
定义数据加载器
from torch.utils.data import DataLoader
BATCH_SIZE = 32
# 训练集的数据加载器
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4
)
# 测试集的数据加载器
test_loader = DataLoader(test_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=4
)
查看一个batch的图像和标注
每个batch有32张三通道的224×224的彩色图片,得到每张图片的索引号
# DataLoader 是 python生成器,每次调用返回一个 batch 的数据
images, labels = next(iter(train_loader))
print(images.shape)
print(labels)
torch.Size([32, 3, 224, 224])
tensor([29, 15, 24, 15, 16, 5, 15, 3, 13, 26, 15, 10, 1, 18, 24, 14, 28, 13,
21, 20, 14, 11, 10, 2, 22, 14, 23, 12, 27, 16, 27, 14])
可视化一个batch的图像和标注
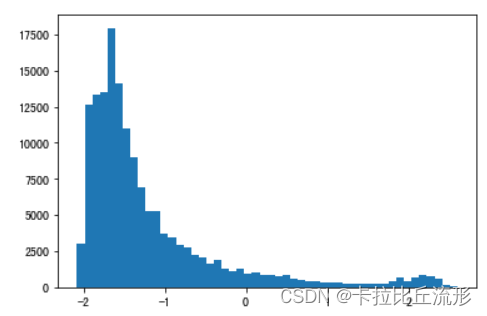
选取batch中的第6张图片进行查看,并可视化像素分布
# 将数据集中的Tensor张量转为numpy的array数据类型
images = images.numpy()
images[5].shape
plt.hist(images[5].flatten(), bins=50)#可视化像素分布
plt.show()
(3, 224, 224)
# batch 中经过预处理的图像
idx = 5
plt.imshow(images[idx].transpose((1,2,0))) # 转为(224, 224, 3)
plt.title('label:'+str(labels[idx].item()))
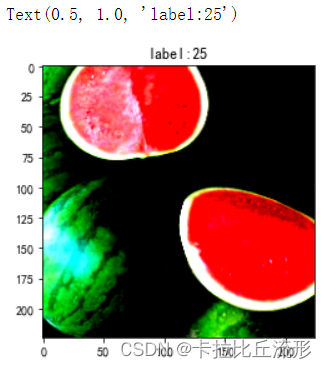
label = labels[idx].item()
print(label)
pred_classname = idx_to_labels[label]
print(pred_classname)
25
西瓜
# 原始图像
idx = 5
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
plt.imshow(np.clip(images[idx].transpose((1,2,0)) * std + mean, 0, 1))
plt.title('label:'+ pred_classname)
plt.show()

模型的构建与测试可视化
导入训练需使用的工具包
from torchvision import models
import torch.optim as optim
from torch.optim import lr_scheduler#学习率降低的优化策略
常见的迁移学习训练方式
选择一:只微调训练模型最后一层(全连接分类层)
当数据分布类似的时候推荐使用
model = models.resnet18(pretrained=True) # 载入预训练模型
# 修改全连接层,使得全连接层的输出与当前数据集类别数对应
# 新建的层默认 requires_grad=True
model.fc = nn.Linear(model.fc.in_features, n_class)
model.fc
# 只微调训练最后一层全连接层的参数,其它层冻结
optimizer = optim.Adam(model.fc.parameters())
Linear(in_features=512, out_features=30, bias=True)
选择二:微调训练所有层
数据分布和预训练模型的数据集分布不太一致时使用
model = models.resnet18(pretrained=True) # 载入预训练模型
model.fc = nn.Linear(model.fc.in_features, n_class)
optimizer = optim.Adam(model.parameters())
选择三:随机初始化模型全部权重,从头训练所有层
数据分布和ImageNet完全不一样
model = models.resnet18(pretrained=False) # 只载入模型结构,不载入预训练权重参数
model.fc = nn.Linear(model.fc.in_features, n_class)
optimizer = optim.Adam(model.parameters())
这三种方式的选择主要和你所用的数据集的数据量和数据分布是否和原始的ImageNet的数据一致来进行选择
训练配置
model = model.to(device)
# 交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 训练轮次 Epoch
EPOCHS = 30
# 学习率降低策略
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
模型训练与评估
模拟一个batch的训练
# 获得一个 batch 的数据和标注
images, labels = next(iter(train_loader))
images = images.to(device)
labels = labels.to(device)
# 输入模型,执行前向预测
outputs = model(images)
# 获得当前 batch 所有图像的预测类别 logit 分数
print(outputs.shape)
# 由 logit,计算当前 batch 中,每个样本的平均交叉熵损失函数值
loss = criterion(outputs, labels)
# 反向传播“三部曲”
optimizer.zero_grad() # 清除梯度
loss.backward() # 反向传播
optimizer.step() # 优化更新
# 获得当前 batch 所有图像的预测类别
_, preds = torch.max(outputs, 1)
print(preds)
print(labels)
由于此时模型还没开始训练,因此预测的基本是错误的
torch.Size([32, 30])
tensor([28, 5, 5, 19, 25, 28, 28, 8, 13, 25, 21, 28, 28, 23, 28, 28, 29, 28,
25, 5, 28, 14, 8, 28, 16, 23, 23, 28, 25, 28, 25, 8])
tensor([28, 22, 23, 4, 2, 3, 21, 27, 21, 3, 13, 13, 11, 21, 24, 19, 14, 12,
24, 5, 28, 8, 12, 17, 22, 2, 11, 4, 7, 17, 8, 18])
训练开始之前,记录日志,得到最开始的训练日志和测试日志如下
epoch = 0
batch_idx = 0
best_test_accuracy = 0
# 训练日志-训练集
df_train_log = pd.DataFrame()
log_train = {
}
log_train['epoch'] = 0
log_train['batch'] = 0
images, labels = next(iter(train_loader))
log_train.update(train_one_batch(images, labels))
df_train_log = df_train_log.append(log_train, ignore_index=True)
df_train_log
# 训练日志-测试集
df_test_log = pd.DataFrame()
log_test = {
}
log_test['epoch'] = 0
log_test.update(evaluate_testset())
df_test_log = df_test_log.append(log_test, ignore_index=True)
df_test_log


函数:在训练集上训练
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_auc_score
def train_one_batch(images, labels):
'''
运行一个 batch 的训练,返回当前 batch 的训练日志
'''
# 获得一个 batch 的数据和标注
images = images.to(device)
labels = labels.to(device)
outputs = model(images) # 输入模型,执行前向预测
loss = criterion(outputs, labels) # 计算当前 batch 中,每个样本的平均交叉熵损失函数值
# 优化更新权重
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 获取当前 batch 的标签类别和预测类别
_, preds = torch.max(outputs, 1) # 获得当前 batch 所有图像的预测类别
preds = preds.cpu().numpy()
loss = loss.detach().cpu().numpy()
outputs = outputs.detach().cpu().numpy()
labels = labels.detach().cpu().numpy()
log_train = {
}
log_train['epoch'] = epoch
log_train['batch'] = batch_idx
# 计算分类评估指标
log_train['train_loss'] = loss
log_train['train_accuracy'] = accuracy_score(labels, preds)
# log_train['train_precision'] = precision_score(labels, preds, average='macro')
# log_train['train_recall'] = recall_score(labels, preds, average='macro')
# log_train['train_f1-score'] = f1_score(labels, preds, average='macro')
return log_train
函数:在整个测试集上评估
def evaluate_testset():
'''
在整个测试集上评估,返回分类评估指标日志
'''
loss_list = []
labels_list = []
preds_list = []
with torch.no_grad():
for images, labels in test_loader: # 生成一个 batch 的数据和标注
images = images.to(device)
labels = labels.to(device)
outputs = model(images) # 输入模型,执行前向预测
# 获取整个测试集的标签类别和预测类别
_, preds = torch.max(outputs, 1) # 获得当前 batch 所有图像的预测类别
preds = preds.cpu().numpy()
loss = criterion(outputs, labels) # 由 logit,计算当前 batch 中,每个样本的平均交叉熵损失函数值
loss = loss.detach().cpu().numpy()
outputs = outputs.detach().cpu().numpy()
labels = labels.detach().cpu().numpy()
loss_list.append(loss)
labels_list.extend(labels)
preds_list.extend(preds)
log_test = {
}
log_test['epoch'] = epoch
# 计算分类评估指标
log_test['test_loss'] = np.mean(loss)
log_test['test_accuracy'] = accuracy_score(labels_list, preds_list)
log_test['test_precision'] = precision_score(labels_list, preds_list, average='macro')
log_test['test_recall'] = recall_score(labels_list, preds_list, average='macro')
log_test['test_f1-score'] = f1_score(labels_list, preds_list, average='macro')
return log_test
创建wandb可视化项目
登录wandb
- 安装 wandb:pip install wandb
- 登录 wandb:在命令行中运行wandb login
- 按提示复制粘贴API Key至命令行中
import wandb
wandb.init(project='fruit30', name=time.strftime('%m%d%H%M%S'))
模型训练
记录训练日志和测试日志
for epoch in range(1, EPOCHS+1):
print(f'Epoch {
epoch}/{
EPOCHS}')
## 训练阶段
model.train()
for images, labels in tqdm(train_loader): # 获得一个 batch 的数据和标注
batch_idx += 1
log_train = train_one_batch(images, labels)
df_train_log = df_train_log.append(log_train, ignore_index=True)
wandb.log(log_train)
lr_scheduler.step()
## 测试阶段
model.eval()
log_test = evaluate_testset()
df_test_log = df_test_log.append(log_test, ignore_index=True)
wandb.log(log_test)
# 保存最新的最佳模型文件
if log_test['test_accuracy'] > best_test_accuracy:
# 删除旧的最佳模型文件(如有)
old_best_checkpoint_path = 'checkpoints/best-{:.3f}.pth'.format(best_test_accuracy)
if os.path.exists(old_best_checkpoint_path):
os.remove(old_best_checkpoint_path)
# 保存新的最佳模型文件
new_best_checkpoint_path = 'checkpoints/best-{:.3f}.pth'.format(log_test['test_accuracy'])
torch.save(model, new_best_checkpoint_path)
print('保存新的最佳模型', 'checkpoints/best-{:.3f}.pth'.format(best_test_accuracy))
best_test_accuracy = log_test['test_accuracy']
df_train_log.to_csv('训练日志-训练集.csv', index=False)
df_test_log.to_csv('训练日志-测试集.csv', index=False)
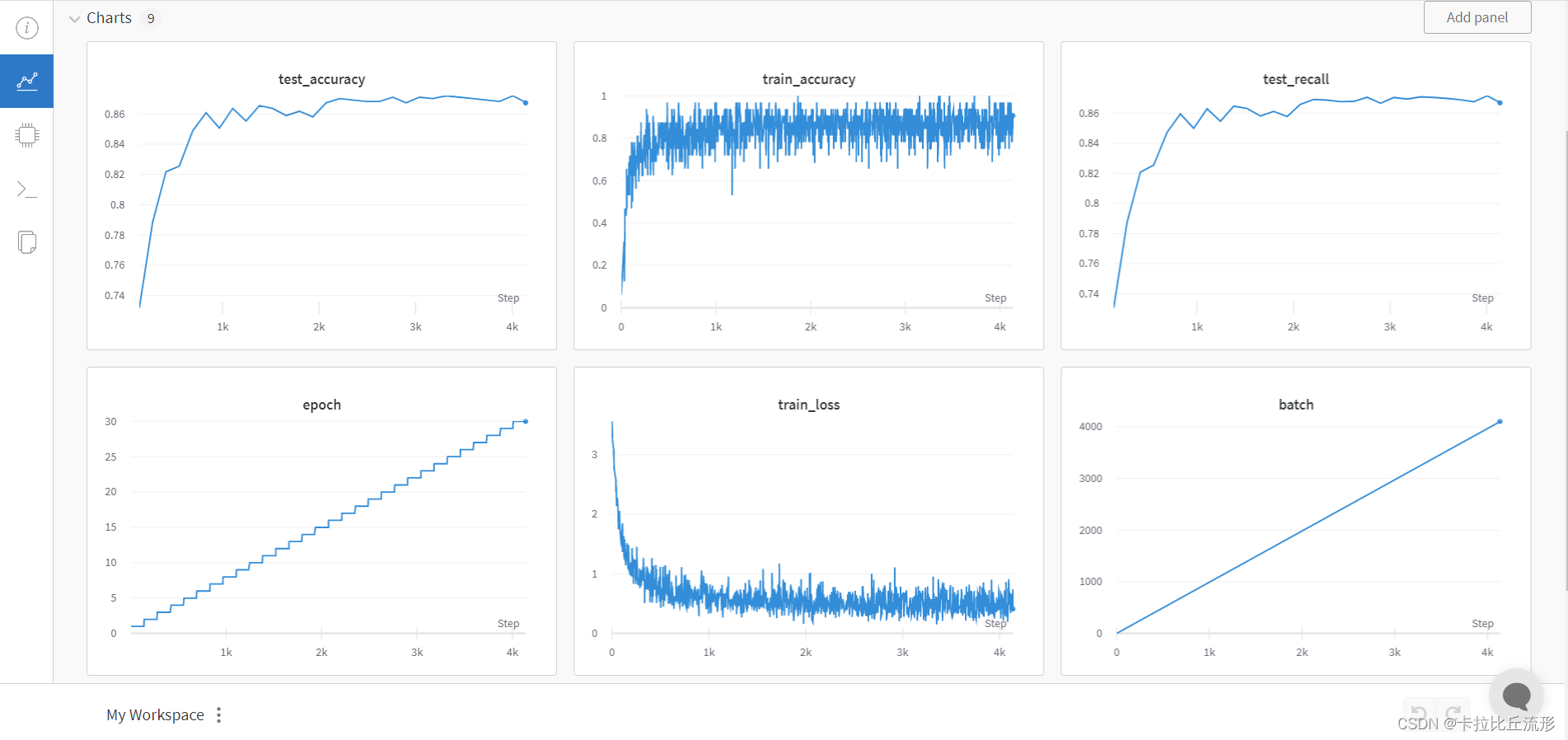
wandb对日志数据的可视化图片如下
模型测试
# 载入最佳模型作为当前模型
model = torch.load('checkpoints/best-{:.3f}.pth'.format(best_test_accuracy))
model.eval()
print(evaluate_testset())
{‘epoch’: 30, ‘test_loss’: 0.29709128, ‘test_accuracy’: 0.8719851576994434, ‘test_precision’: 0.876300961279176, ‘test_recall’: 0.8708395025743249, ‘test_f1-score’: 0.8716524317357935}
可视化训练日志
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# windows操作系统
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
载入训练日志表格
df_train = pd.read_csv('训练日志-训练集.csv')
df_test = pd.read_csv('训练日志-测试集.csv')
df_train
df_test
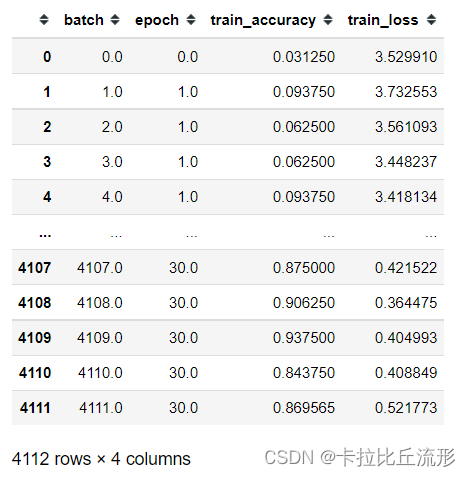
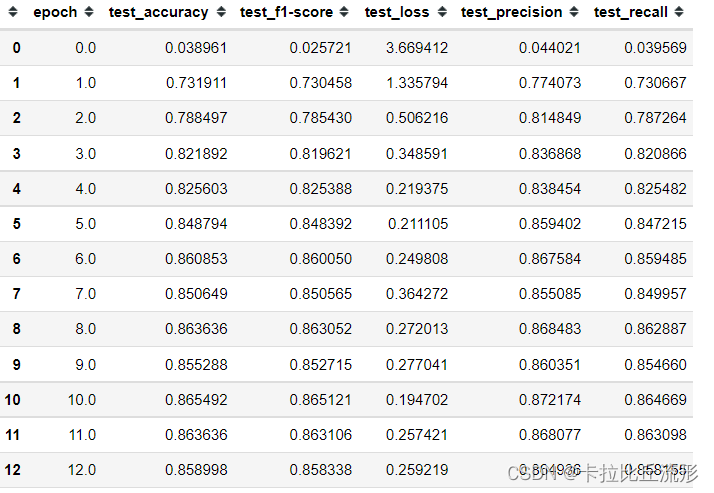
训练集损失函数可视化
plt.figure(figsize=(16, 8))
x = df_train['batch']
y = df_train['train_loss']
plt.plot(x, y, label='训练集')
plt.tick_params(labelsize=20)
plt.xlabel('batch', fontsize=20)
plt.ylabel('loss', fontsize=20)
plt.title('训练集损失函数', fontsize=25)
plt.savefig('图表/训练集损失函数.pdf', dpi=120, bbox_inches='tight')
plt.show()
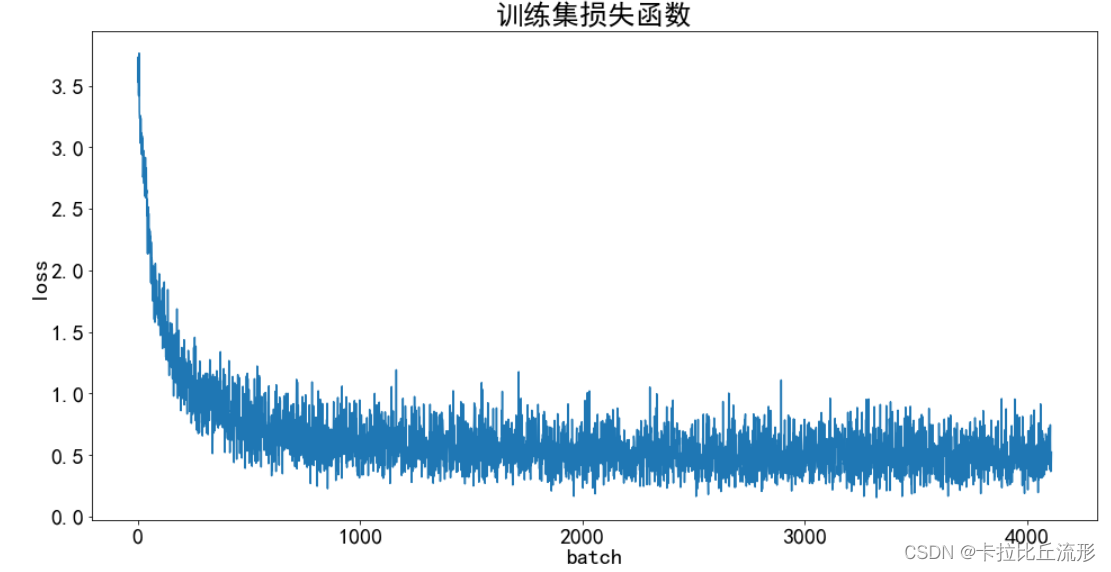
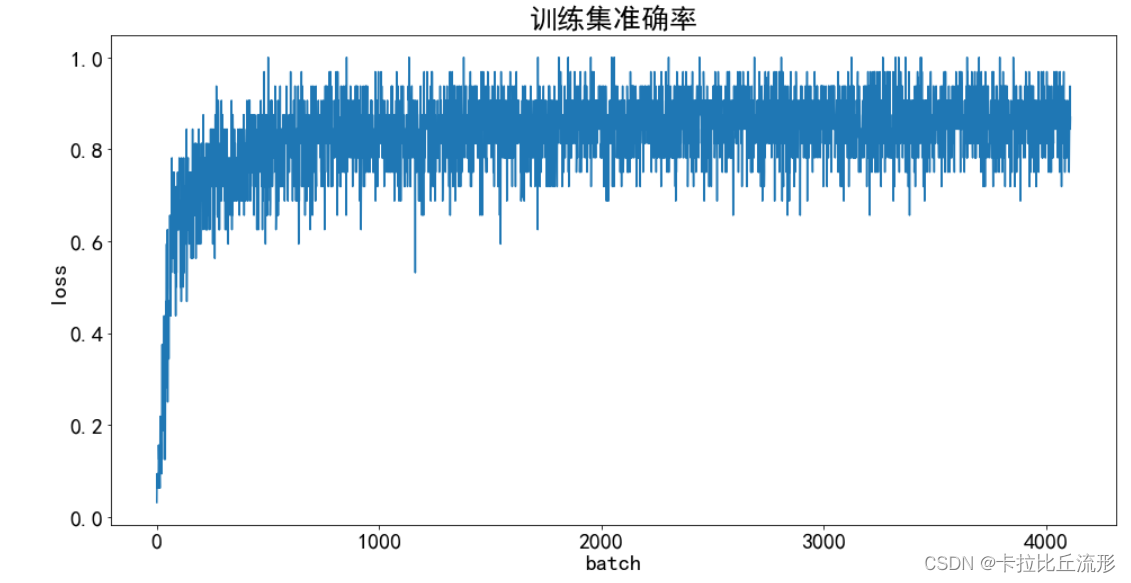
训练集准确率可视化
plt.figure(figsize=(16, 8))
x = df_train['batch']
y = df_train['train_accuracy']
plt.plot(x, y, label='训练集')
plt.tick_params(labelsize=20)
plt.xlabel('batch', fontsize=20)
plt.ylabel('loss', fontsize=20)
plt.title('训练集准确率', fontsize=25)
plt.savefig('图表/训练集准确率.pdf', dpi=120, bbox_inches='tight')
plt.show()
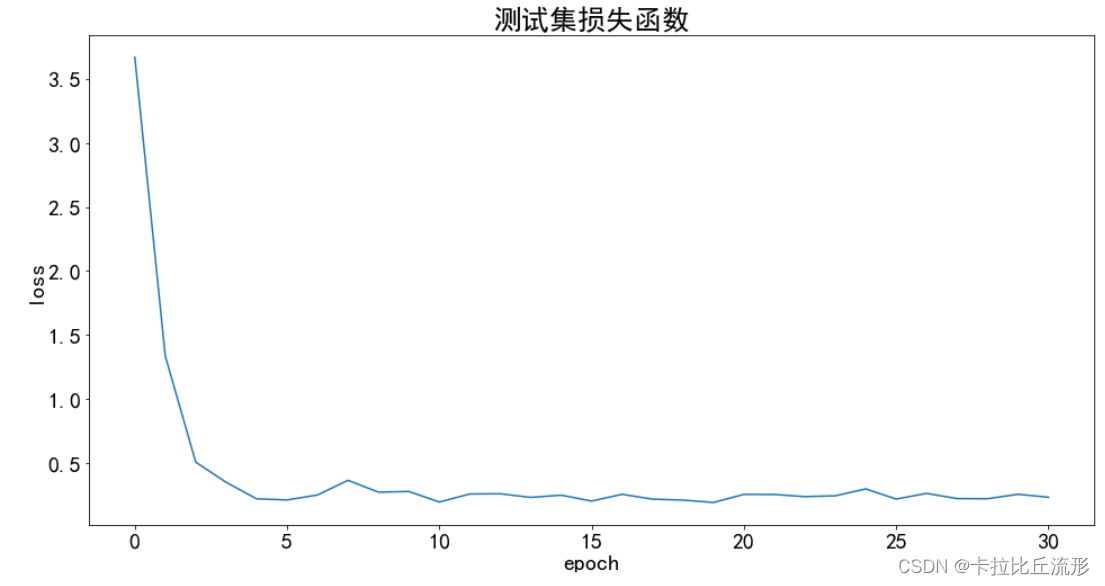
测试集损失函数可视化
plt.figure(figsize=(16, 8))
x = df_test['epoch']
y = df_test['test_loss']
plt.plot(x, y, label='测试集')
plt.tick_params(labelsize=20)
plt.xlabel('epoch', fontsize=20)
plt.ylabel('loss', fontsize=20)
plt.title('测试集损失函数', fontsize=25)
plt.savefig('图表/测试集损失函数.pdf', dpi=120, bbox_inches='tight')
plt.show()
测试集各评估指标可视化
from matplotlib import colors as mcolors
import random
random.seed(124)
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'tab:blue', 'tab:orange', 'tab:green', 'tab:red', 'tab:purple', 'tab:brown', 'tab:pink', 'tab:gray', 'tab:olive', 'tab:cyan', 'black', 'indianred', 'brown', 'firebrick', 'maroon', 'darkred', 'red', 'sienna', 'chocolate', 'yellow', 'olivedrab', 'yellowgreen', 'darkolivegreen', 'forestgreen', 'limegreen', 'darkgreen', 'green', 'lime', 'seagreen', 'mediumseagreen', 'darkslategray', 'darkslategrey', 'teal', 'darkcyan', 'dodgerblue', 'navy', 'darkblue', 'mediumblue', 'blue', 'slateblue', 'darkslateblue', 'mediumslateblue', 'mediumpurple', 'rebeccapurple', 'blueviolet', 'indigo', 'darkorchid', 'darkviolet', 'mediumorchid', 'purple', 'darkmagenta', 'fuchsia', 'magenta', 'orchid', 'mediumvioletred', 'deeppink', 'hotpink']
markers = [".",",","o","v","^","<",">","1","2","3","4","8","s","p","P","*","h","H","+","x","X","D","d","|","_",0,1,2,3,4,5,6,7,8,9,10,11]
linestyle = ['--', '-.', '-']
def get_line_arg():
'''
随机产生一种绘图线型
'''
line_arg = {
}
line_arg['color'] = random.choice(colors)
# line_arg['marker'] = random.choice(markers)
line_arg['linestyle'] = random.choice(linestyle)
line_arg['linewidth'] = random.randint(1, 4)
# line_arg['markersize'] = random.randint(3, 5)
return line_arg
metrics = ['test_accuracy', 'test_precision', 'test_recall', 'test_f1-score']
plt.figure(figsize=(16, 8))
x = df_test['epoch']
for y in metrics:
plt.plot(x, df_test[y], label=y, **get_line_arg())
plt.tick_params(labelsize=20)
plt.ylim([0, 1])
plt.xlabel('epoch', fontsize=20)
plt.ylabel(y, fontsize=20)
plt.title('测试集分类评估指标', fontsize=25)
plt.savefig('图表/测试集分类评估指标.pdf', dpi=120, bbox_inches='tight')
plt.legend(fontsize=20)
plt.show()

总结与扩展
本篇文章主要介绍了通过迁移学习微调训练自己的图像分类模型。常见的迁移学习的方式有以下三种:只微调训练模型最后一层(全连接分类层);微调训练所有层;随机初始化模型全部权重,从头训练所有层。不同的迁移学习范式复用的是不同层次的卷积神经网络的特征和权重,我们在选择迁移学习方式的时候主要要考虑我们的数据集和预训练模型所用的数据集之间的分布和数据量大小差异。对训练过程中产生的日志数据我们可以进行可视化,我们可以使用wandb创建自己的可视化项目。
注意事项
-
严禁把测试集图像用于训练(反向传播更新权重)
-
抛开baseline基准模型谈性能(速度、精度),都是耍流氓
-
测试集上的准确率越高,模型就一定越好吗?
-
常用数据集中存在大量的错标、漏标:https://mp.weixin.qq.com/s/4NbIA4wsNdX-N2uMOUmPLA
创新点展望
-
更换不同预训练图像分类模型
-
分别尝试三种不同的迁移学习训练配置:只微调训练模型最后一层(全连接分类层)、微调训练所有层、随机初始化模型全部权重,从头训练所有层
-
更换不同的优化器、学习率
扩展阅读
同济子豪兄的论文精读视频:https://openmmlab.feishu.cn/docs/doccnWv17i1svV19T0QquS0gKFc
开源图像分类算法库 MMClassificaiton:https://github.com/open-mmlab/mmclassification
机器学习分类评估指标
公众号 人工智能小技巧 回复 混淆矩阵
手绘笔记讲解:https://www.bilibili.com/video/BV1iJ41127wr?p=3
混淆矩阵:
https://www.bilibili.com/video/BV1iJ41127wr?p=4
https://www.bilibili.com/video/BV1iJ41127wr?p=5
ROC曲线:
https://www.bilibili.com/video/BV1iJ41127wr?p=6
https://www.bilibili.com/video/BV1iJ41127wr?p=7
https://www.bilibili.com/video/BV1iJ41127wr?p=8
F1-score:https://www.bilibili.com/video/BV1iJ41127wr?p=9
F-beta-score:https://www.bilibili.com/video/BV1iJ41127wr?p=10