特征提取学习
通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。
PCA思想
-
将n维特征映射到k维上(k<n),这k维是全新的正交特征。 这k维特征称为主成分,是重新构造出来的k维特征,而不是简单地从n维特征中去除其余n-k维特征。
-
协方差:
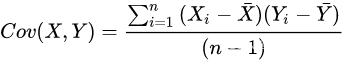
协方差为正说明X和Y为正相关关系,为负代表X和Y为负相关关系,为0时代表X和Y独立。协方差绝对值越大,两者对彼此的影响越大,反之越小。
PCA过程
- 特征中心化: 即每一维的数据都减去该维的均值,每一维代表一个特征。
代表每一维的均值。
-
求特征协方差矩阵,如果数据为三维(x,y,z),(有三个特征值)
-
计算协方差矩阵的特征值 (特征向量均归一化为单位向量)
-
将特征值按照从大到小的顺序排列,选择其中最大的k个,将其对应的k个特征向量分别作为列向量组成特征向量矩阵。其中k的选择标准一般情况下为:

-
将样本点投影到选取的特征向量上。假设样例为m,特征数为n。
这样就将原始样例的n维特征变为了k维,这k维就是原始特征在k维上的投影。
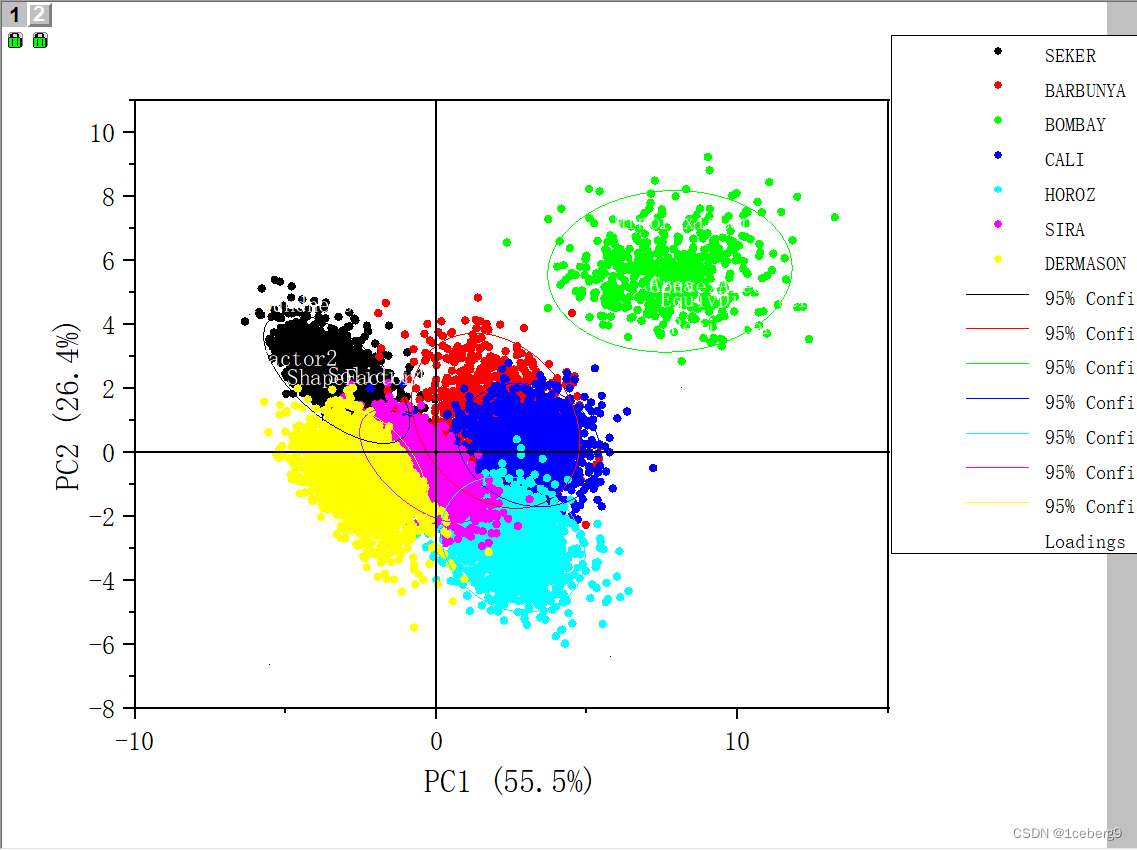
对DryBeans进行预分析
X_digits = x_train
y_digits = y_train
estimator = PCA(n_components=3)
X_pca = estimator.fit_transform(X_digits)
for i in range(len(colors)):
px = X_pca[:, 0][y_digits.as_matrix() == i]
py = X_pca[:, 1][y_digits.as_matrix()== i]
plt.scatter(px, py, c=colors[i])
plt.legend(np.arange(0,10).astype(str))
plt.xlabel('PC1')
plt.ylabel('PC2')
导入相关库文件
from sklearn.decomposition import PCA
PCA参数介绍
n_components =
- 默认值为保留所有特征值维度,即不进行主成分降维。
取大于等于1的整数时,即指定我们希望降维后的维数。
取0-1的浮点数时,即指定降维后的方差和占比,比例越大,保留的信息越多。系统会自行计算保留的维度个数。
PCA属性
-
components_:降维后,保留的成分。每一行代表一个主成分,各成分按方差大小排序。
-
explained_variance_:降维后 ,各成分的方差
-
explained_variance_ratio_:降维后,各成分的方差占比
选择合适的PCA维度
#获得数据,X为特征值,y为标记值
X = x_train
y = y_train
pca=PCA(n_components=0.99)
pca.fit(X,y)
ratio=pca.explained_variance_ratio_
print("pca.components_",pca.components_.shape)
print("pca_var_ratio",pca.explained_variance_ratio_.shape)
#绘制图形
plt.plot([i for i in range(X.shape[1])],
[np.sum(ratio[:i+1]) for i in range(X.shape[1])])
plt.xticks(np.arange(X.shape[1],step=5))
plt.yticks(np.arange(0,1.01,0.05))
plt.grid()
plt.show()
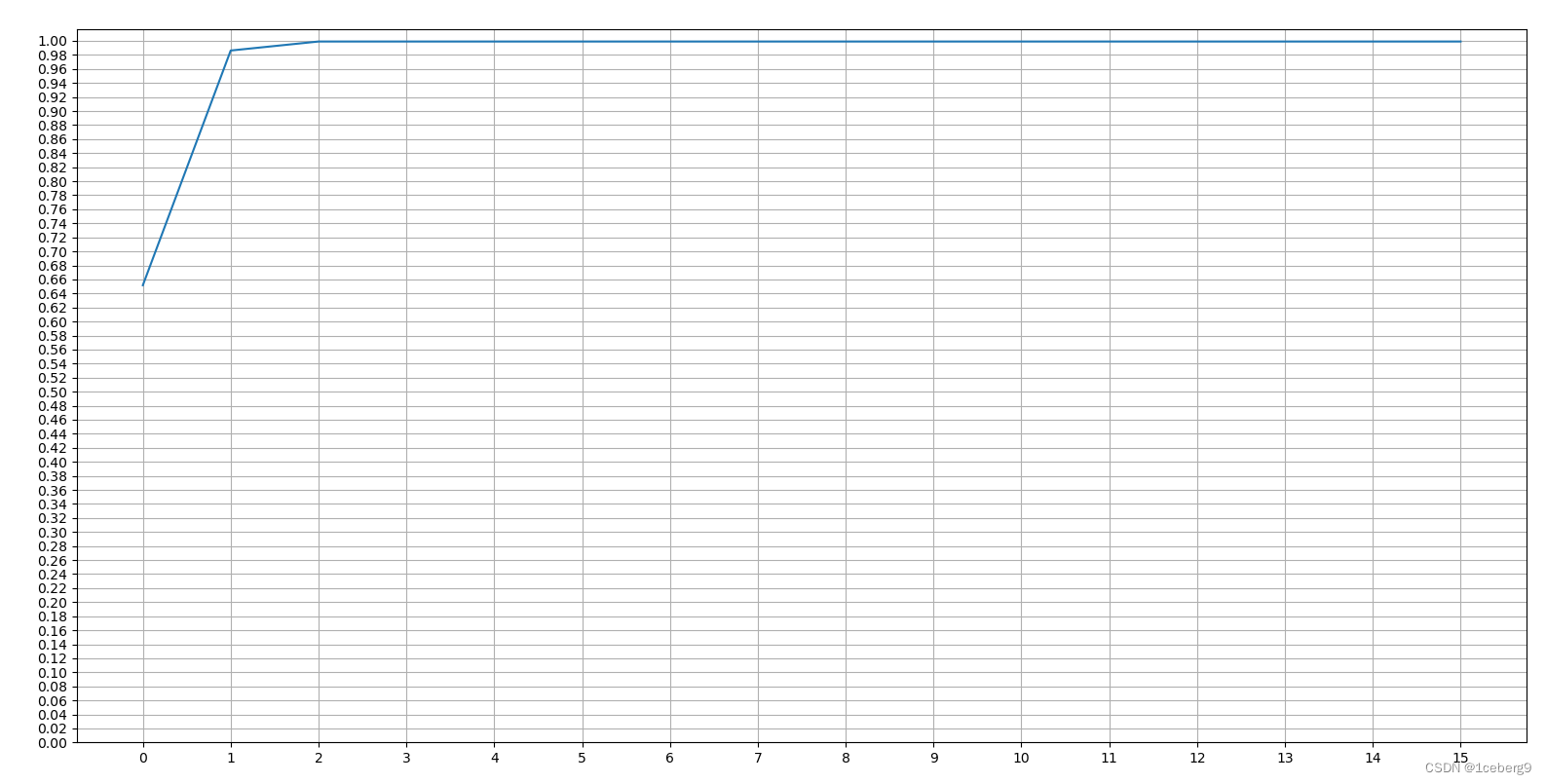
横坐标:表示保留的维度个数
纵坐标:降维后的所有成分的方差和
通过下图,我们可以发现随着降维个数的增加,方差和占比是先快速增长,然后就趋于平稳。
当降维后的维度至3维时,所有成分的方差和接近1.0,说明DryBeans数据集适合降维至3维。
代码封装
"""特征提取 """
pca = PCA(n_components=input_size)
feature = pca.fit_transform(feature)
# 将数据集分为训练集和测试集,if_normalize为是否归一化,test_size为训练集占得比例
X_train, X_test, y_train, y_test = split(feature, target, test_size=0.2, if_normalize=True)
代码封装至BP_Train.py中,后续只需要修改input_size即可。
细节补充
fit、transform、fit_transform区别
fit(): 求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。
transform(): 在fit的基础上,进行标准化,降维,归一化等操作。
fit_transform(): fit和transform的组合,既包括了训练又包含了转换。
测试
LR = 0.005
input_size = 2
准确率:0.52
LR = 0.005
input_size = 3
准确率:0.89
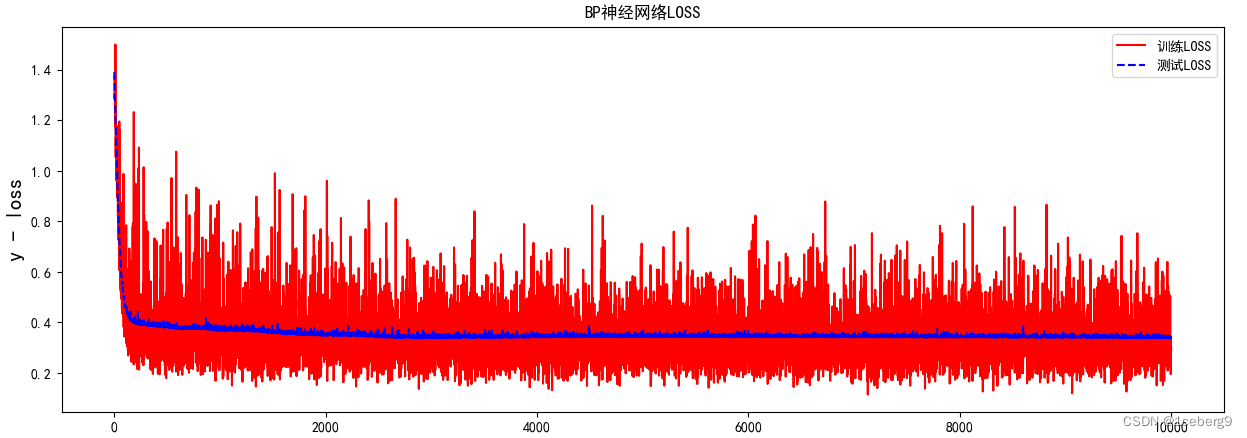
LR = 0.005
input_size = 4
准确率:0.89
时间:50min
1150次收敛至0.89
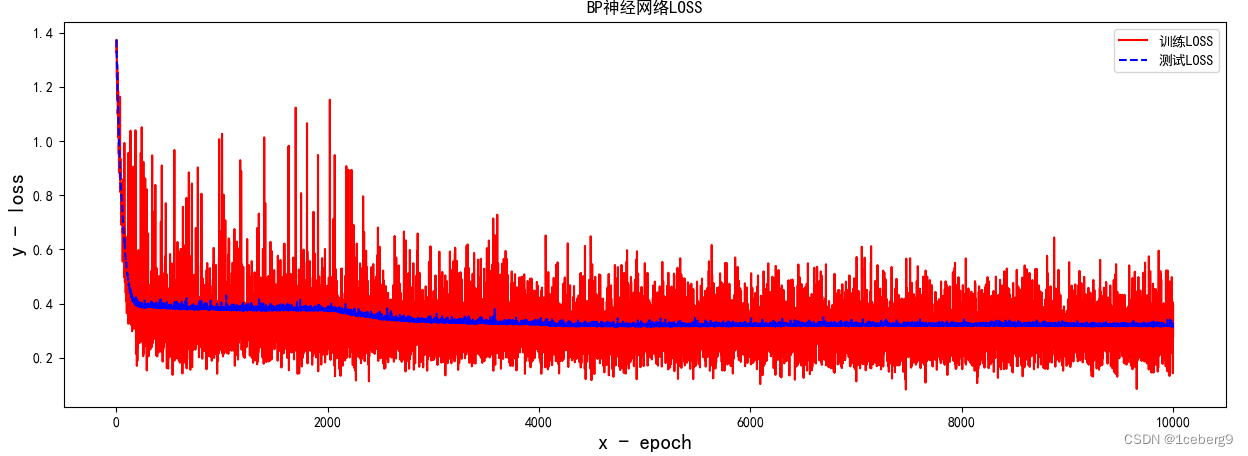
LR = 0.005
input_size = 5
准确率:0.915
时间:50min
500次左右即可收敛至0.9
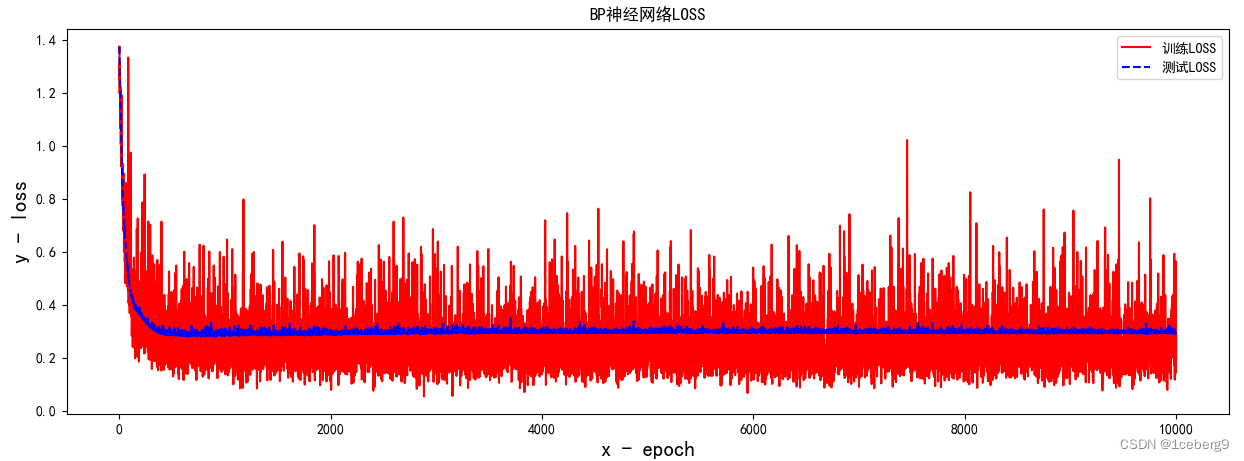
LR = 0.005
input_size = 6
准确率:0.925
时间:50min
5000次左右即可收敛至0.92
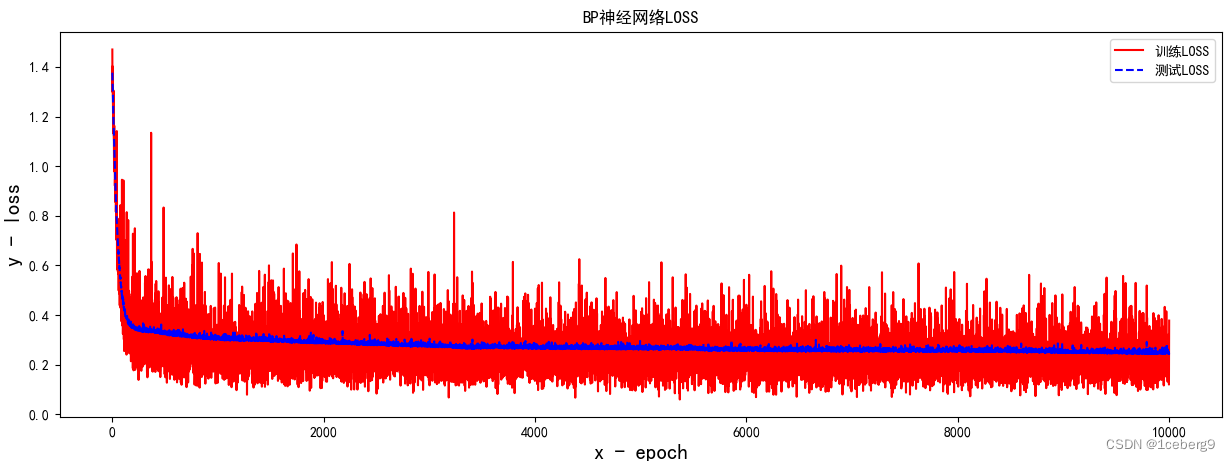
LR = 0.005
input_size = 7
准确率:0.925
时间:50min
5800次左右即可收敛至0.92
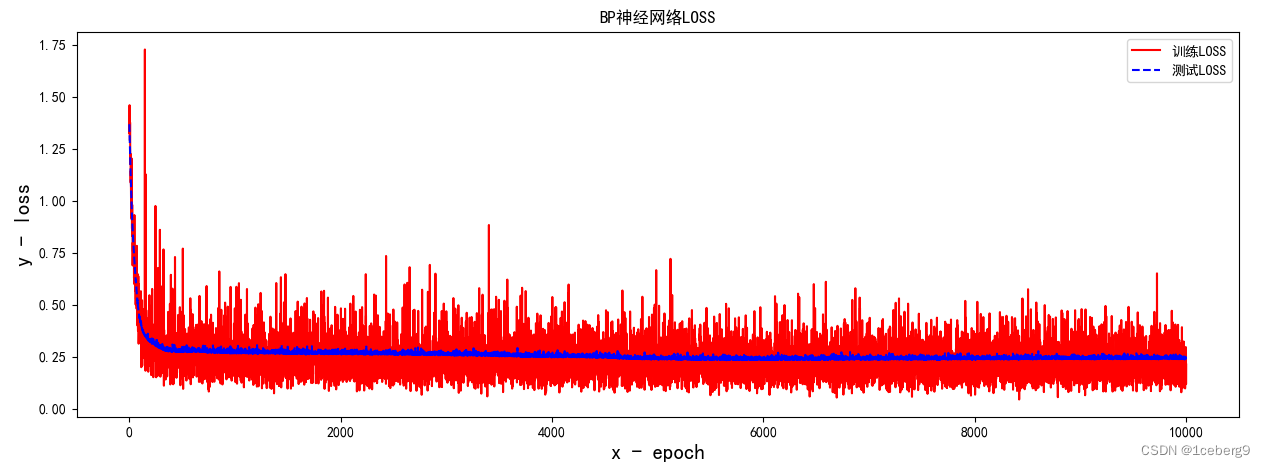
总结与后续问题
PCA的优点:能够大幅减少特征空间维度,降低了数据复杂度,并且方便模型拟合,大大减少训练时间。
PCA的缺点:可能会降低模型精度,因为会丢弃一些信息;转换过程复杂,结果难以解释;可能对异常值敏感,后续处理相关数据集再继续完善。