中文分词
背景
词语的概念:词语(word)是最小独立使用的音义结合体(即为任务中的原子单词),能够独立表达语言和内容的最基本单元。
对于英文等体系的印-欧体系,一般会有空格作为间隔,但是对于其他体系(汉-藏体系,闪-含体系)等没有明显的词语分隔符,为了更好完成分词任务,方便后续任务展开,我们一般采用分词算法。平时自然语言处理使用比较多的中文分词是调用第三方库jieba。但是在下文中用正向最大匹配分词算(Forward Maximum Matching FMM)。
FMM代码
def fmm_word_seg(sentence, lexicon, max_len):
'''
sentence: 待分词的句子
lexicon:词典(所有单词的集合),一般为txt文件,每一行存储一个词典
max_len:词典中最长单词的长度
'''
begin = 0
end = min(begin + max_len, len(sentence))
words = []
while begin < end: # 这里的话使用了贪心算法
word = sentence[begin:end]
if word in lexicon or end - begin == 1:
# 考虑两组情况,一组为end==begin,即为只有字母的差距不需要分词(即为到临界条件),另外为在词典中直接开始分词
words.append(word)
begin = end # 更新begin为end,即为算后面的句子,前面在词典的已经被划分了,使用更新begin
end = min(begin + max_len, len(sentence)) # 更新新的end,即为最后句子的结尾要么是sentence的长度,要么在sentence之前
else:
end -= 1
return words
def load_dict():
f = open('lexicon.txt') # 词典文件,每一行存储一个单词
lexicon = set()
max_len = 0
for line in f:
word = line.strip() # 一般为跳过空格
lexicon.add(word)
if len(word) > max_len:
max_len = len(word)
f.close()
return lexicon, max_len
lexicon,max_len = load_dict()
words = fmm_word_seg(input("输入的句子:",lexicon, max_len))
for word in words:
print(word,)
FMM缺点
更倾向于切分较长的词语(通过begin和end的遍历变化可知)
容易造成切分歧义的问题
切分歧义:同一个句子有不一样的切分结果,例子:研究生命的起源可以且分为['研究生',‘命’,‘的’,‘起源’]或者是[‘研究’,‘生命’,‘的’,‘起源’]
对中文的定义不明确,即为可能出现多对一的情况。(因为中文情况比较难以理解,不同词语可能代表不一样的意思)
例子:‘哈尔滨市’=‘哈尔滨’,但是具体切分有不一样的结果,这个问题可以在后续的中文分词的规范进行调整
有一些词语未出现在lexicon(词典)中,就有可能造成未登录词的问题。
子词切分
一般情况下,有分隔符的词语就不需要在进行额外的分词,但是这些语言里面的单词可能有不一样的词义变化,容易造成数据矩阵稀疏,词表过大等问题,这种情况下运用简单的分词方法无法处理,所以我们一般会采取词形还原,词干提取,提取出单词的词根等特征,减少数据稀疏。
词形还原:将单词变成一个原型的单词,比如computer变成compute
词干处理有可能就是将词语的前缀,后缀等去除比如computing 变成compute
因为子词切分任务需要人为制定规则进行处理,robust(稳健性和适应性)较差,所以我们更倾向于将子词切分任务变成基于统计的无监督子词切分方法(Subword)。而且在预训练语言模型中被广泛使用。

子词切分定义:将一个单词切分为若干连续的片段
子词切分原理:使用尽量长,频次高的子词对单词进行切分
下面介绍比较多的是字节对编码(Byte Pair Encoding BPE)算法。
BPE算法(提取词干方法)
构造长度为L的子词表
主要是通过以下方式构建子词表,流程框架图如图所示。

具体步骤为将每个字符作为一个单词,划分之后计算相对应的频次,然后进行合并前面系数最多的单词(类似于哈夫曼树)成为一个新的单词。(每个单词后面的\w代表一个单词的分解符号)

原先的句子
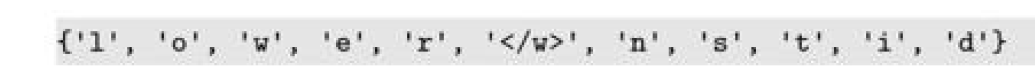
初始化的词表(做一个去重的操作,长度为11)

之后进行合并出现次数最高的e和s,去除s,增加一个es(因为s在语料库已经不存在了,s被合并为st,所以删除的是不存在的子词s),然后重新统计子词出现的长度(此时词表的长度为11)
不断循环,直至词表长度为所想要的L为止。
将单词切分为子词序列
我们可以先将单词按照子词长度从大到小排序,然后前项遍历子词此表,如果是的话就切分,如果子词全部遍历结束,单词中仍有子串未被切分,我们认为这个单词为低频串,用<UNK>进行标记。
例子如下,在子词表中的部分是我们不需要的部分,即为舍弃的部分,这里运用的是提取词干的方法。
句子:['the</w>','highest</w>','mountain</w>']
子词大小:['errrr</w>','tain</w>','moun','est</w>','high','the</w>','a</w>']
⼦词切分的结果为['the</w>','high','est</w>','moun','tain</w>']
编码结束之后,我们根据结果和子词词表一一对照即可,最后的时候根据<\w>的标志还原句子即可。
BPE代码
参考:https://zhuanlan.zhihu.com/p/448147465
BPE函数代码
import re, collections
def get_vocab(filename): # 这里的话是针对于文件中的单词进行划分加上统计,最终整理出来的是一个defaultdict类型的字典形式
vocab = collections.defaultdict(int)
'''
vocal的形式为['l o w e r </w>']:int
'''
with open(filename, 'r', encoding='utf-8') as fhand:
for line in fhand: # 每一行为n个单词,对每个行的单词出现频次进行统计,比如low出现了几次
words = line.strip().split() # 将每个单词进行切分
for word in words: # 这里的words为一个列表,大概为['l,o,w,e,r],每一个word
vocab[' '.join(list(word)) + ' </w>'] += 1
return vocab
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items(): # 对'l o w e r </w>':5的vocab进行处理,word为'l o w e r',
symbols = word.split() # symbol为[l, o, w, e, r]
# print("word:",word,'\n',"symbol:",symbols)
for i in range(len(symbols)-1):# (symbols)-1)的原因是因为需要统计相邻出现的次数
# print(pairs[symbols[i],symbols[i+1]])
# print(pairs)
'''
pairs在这里为为一下的形式,基本上回算相邻的字母之间的最高频数
defaultdict(<class 'int'>, {})
defaultdict(<class 'int'>, {('l', 'o'): 5})
defaultdict(<class 'int'>, {('l', 'o'): 5, ('o', 'w'): 5})
defaultdict(<class 'int'>, {('l', 'o'): 5, ('o', 'w'): 5, ('w', '</w>'): 5})
'''
pairs[symbols[i],symbols[i+1]] += freq # 统计相邻子词对的出现频次
return pairs
def merge_vocab(pair, v_in):
v_out = {}
# 这里的话会将最高频次进行合并
bigram = re.escape(' '.join(pair))
# 匹配到最高的那个字符,大量去除pair里面的字符,这里将他封装成一string类型的变量,这里为合并的子词
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
# print(p)
for word in v_in:
# 将子词替换为输出的词语,即为将句子变成,用'.join(pair)替换 word,这里的word为词表,所以价位做到词表替换
w_out = p.sub(''.join(pair), word)
# 剩下的w_out如果匹配不成功,那就没有变化
v_out[w_out] = v_in[word]
return v_out
def get_tokens(vocab):
tokens = collections.defaultdict(int)
for word, freq in vocab.items():
word_tokens = word.split()
for token in word_tokens:
tokens[token] += freq
return tokensBPE代码调用
vocab = {'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}
print('==========')
print('Tokens Before BPE')
tokens = get_tokens(vocab)
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(tokens)))
print('==========')
num_merges = 5
for i in range(num_merges):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print('Iter: {}'.format(i))
print('Best pair: {}'.format(best))
print('vocab:',vocab) # vocab返回的是一个词典的工作
# 此时的vocab的大概格式为{'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w es t </w>': 6, 'w i d es t </w>': 3}
# vocab: {'low </w>': 5, 'low e r </w>': 2, 'n e w est</w>': 6, 'w i d est</w>': 3}
tokens = get_tokens(vocab)
# print('token:',tokens)
# tokens返回的是是一个defaultdict词典,而且value只能是int类型两者不一致
# tokens的格式为token: defaultdict(<class 'int'>, {'l': 7, 'o': 7, 'w': 16, '</w>': 16, 'e': 8, 'r': 2, 'n': 6, 'es': 9, 't': 9, 'i': 3, 'd': 3})
# token: defaultdict(<class 'int'>, {'low': 7, '</w>': 7, 'e': 8, 'r': 2, 'n': 6, 'w': 9, 'est</w>': 9, 'i': 3, 'd': 3})
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(tokens)))其他分词方法
WordPiece选择能够选定提升语言模型中概率最大的相邻子词进行合并,提升语言模型概率最大的相邻子词的互信息值。是的两个子词在模型中具有较强的关联性。(运用了似然估计等方法)
如果需要查看wordPiece的原理,可以查看博客https://zhuanlan.zhihu.com/p/191648421
ULM算法(Unigram Language Model)是减量法,最开始初始化一个打次表,然后根据一定的评估准则不断丢弃词表中的单词,直到满足词表的大小。
而且将句子看成是Unicode编码序列,从而能够处理更多的语言的词语,而且在Bert模型里面运用到的就是WordPiece算法,即为在合并词语的时候优先经过一定的估计从而进行选择点互信息最丰富的进行合并。