自然语言处理是什么
——摘自《统计自然语言处理第二版》宗成庆
自然语言处理的定义
美国计算机科学家马纳瑞斯(Bill Manaris)在《从人-机交互的角度看自然语言处理》一文中给自然语言处理提出的如下定义:
自然语言处理(natural language processing, NLP)可以定义为研究在人与人交际中以及在人与计算机交际中的语言问题的一门学科。自然语言处理要研制表示语言能力(linguistic competence)和语言应用(linguistic performance)的模型,建立计算框架来实现这样的语言模型,提出相应的方法来不断地完善这样的语言模型,根据这样的语言模型设计各种实用系统,并探讨这些实用系统的评测技术。
基于统计和基于规则的区别
基于统计的自然语言处理的理论基础是哲学中的经验主义,基于规则的自然语言处理的理论基础是哲学中的理性主义。这些问题,说到底,是关于如何处理经验主义和理性主义关系的问题。——P28
语言
语言由语音、词汇和语法构成。语音和文字是构成语言的两个基本属性,语音是语言的物质外壳,文字则是记录语言的书写符号系统[黄伯荣等,1991]。
图灵测试
当时图灵提出这个测试的目的是用来判断计算机是否可以被认为“能思考”。后来这个测试被称为图灵
测试(Turing test),现已被多数人承认。图灵试图解决长久以来关于如何定义思考的哲学争论,他提出了一个虽然主观但可以操作的标准:如果一个计算机系统的表现(act)、反应(react)和互相作用(interact)都和有意识的个体一样,那么,这个计算机系统就应该被认为是有意识的。为此,图灵设计了一种“模仿游戏”,即现在所说的图灵测试:测试人在一段规定的时间内,在无法看到反应来源的情况下,根据两个实体(被测试的计算机系统和另外一个人)对他提出的各种问题的反应来判断做出反应的是人还是计算机。通过一系列这样的测试,从计算机被误判为人的几率就可以测出计算机系统所具有的智能程度。
自然语言处理的研究方向
1、机器翻译2、自动文摘3、信息检索4、文档分类5、问答系统6、信息过滤7、信息抽取8、文本挖掘9、舆情分析10、隐喻计算11、文字编辑和自动校对12、作文自动评分13、光读字符识别14、语音识别15、文语转换16、说话人识别/认证/验证
自然语言处理要达到的要求
任何一个自然语言处理系统,都无法回避歧义的消解问题。一个实用的自然语言处理系统必须具有较好的未知语言现象的处理能力,而且有足够的对各种可能输入形式的容错能力,即我们通常所说的系统的鲁棒性(robustness)问题。
自然语言处理的数学基础
熵
熵又称为自信息(self-information),可以视为描述一个随机变量的不确定性的数量。它表示信源X每发一个符号(不论发什么符号)所提供的平均信息量[姜丹,2001]。一个随机变量的熵越大,它的不确定性越大,那么,正确估计其值的可能性就越小。越不确定的随机变量越需要大的信息量用以确定其值。
条件熵和联合熵


熵率
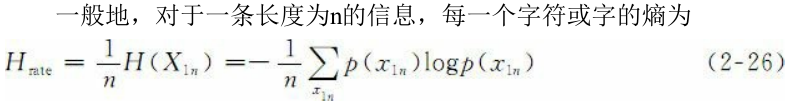

互信息


困惑度

