知识融合常见的流程和步骤
1知识融合
经由信息抽取之后的信息单元间的关系是扁平化的,缺乏层次性和逻辑性,同时存在大量冗余甚至错误的信息碎片。知识融合旨在解决如何将关于同一个实体或概念的多源描述信息融合起来,将多个知识库中的知识进行整合,形成一个知识库的过程。知识融合中常见问题有数据质量问题:命名模糊,数据输入错误,数据格式不一致,缩写问题。在这个过程中,主要关键技术包含指代消解、实体消歧、实体链接。
1.1 指代消解
(1)显性代词消解,是指当前的照应语与上下文出现的词、短语或句子(句群)存在密切的语义关联性,指代依存于上下文语义中,在不同的语言环境中可能指代不同的实体,具有非对称性和非传递性。
(2)零代词消解,是恢复零代词指代前文语言学单位的过程,有时也被称为省略恢复。
(3)共指消解
主要是指两个名词(包括代名词、名词短语)指向真实世界中的同一参照体。多源异构数据在集成的过程中,通常会出现一个现实世界实体对应多个表象的现象,导致这种现象发生的原因可能是:拼写错误、命名规则不同、名称变体、缩写等等。而这种现象会导致集成后的数据存在大量冗余数据、不一致数据等问题,从而降低了集成后数据的质量,进而影响了基于集成后的数据做分析挖掘的结果。分辨多个实体表象是否对应同一个实体的问题即为实体统一。如重名现象,南京航天航空大学(南航)
1.1.1 解决指代消解的方法
(1)基于两者混用的方法

(2) 模式匹配
模式匹配主要是发现不同关联数据源中属性之间的映射关系,主要解决三元组中谓词之间的冲突问题;另一种解释:解决不同关联数据源对相同属性采用不同标识符的问题,从而实现异构数据源的集成

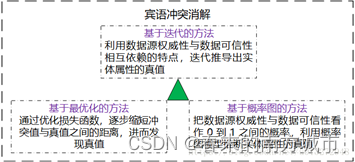
(3)宾语冲突消解
宾语冲突消解是解决多源关联数据宾语不一致问题。
1.2 实体消歧
实体消歧的本质在于一个词有很多可能的意思,也就是在不同的上下文中所表达的含义不太一样。如:我的手机是苹果。我喜欢吃苹果。按照实体消歧任务领域不同,实体消歧系统可分为:
| 文本类型 |
消歧方法 |
| 结构化文本 |
实体指称项被表示为一个结构化的文本记录,如list列表、知识库等;缺少上下文,主要依赖字符串比较和实体关系信息完成消歧; |
| 非结构化文本 |
实体指称项被表示为一段非结构化文本;存在大量上下文,主要利用指称项上下文和背景知识完成消歧。常用方法:基于聚类的实体消歧、基于实体链接的实体消歧。 |
1.2.1 解决实体消歧的方法
(1)基于词典的词义消歧
基于词典的词义消歧方法研究的早期代表工作是Lesk 于1986 的工作。给定某个待消解词及其上下文,该工作的思想是计算语义词典中各个词义的定义与上下文之间的覆盖度,选择覆盖度最大的作为待消解词在其上下文下的正确词义。但由于词典中词义的定义通常比较简洁,这使得与待消解词的上下文得到的覆盖度为0,造成消歧性能不高。
(2)有监督词义消歧
有监督的消歧方法使用词义标注语料来建立消歧模型,研究的重点在于特征的表示。常见的上下文特征可以归纳为三个类型:
1.词汇特征通常指待消解词上下窗口内出现的词及其词性;
2.句法特征利用待消解词在上下文中的句法关系特征,如动-宾关系、是否带主/宾语、主/宾语组块类型、主/宾语中心词等;
3.语义特征在句法关系的基础上添加了语义类信息,如主/宾语中心词的语义类,甚至还可以是语义角色标注类信息。
(3)无监督和半监督词义消歧
虽然有监督的消歧方法能够取得较好的消歧性能,但需要大量的人工标注语料,费时费力。为了克服对大规模语料的需要,半监督或无监督方法仅需要少量或不需要人工标注语料。一般说来,虽然半监督或无监督方法不需要大量的人工标注数据,但依赖于一个大规模的未标注语料,以及在该语料上的句法分析结果。
1.3 实体链接(Entity Linking)
实体链接(entity linking)是指对于从非结构化数据(如文本)或半结构化数据(如表格)中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。其基本思想是首先根据给定的实体指称项,从知识库中选出一组候选实体对象,然后通过相似度计算将指称项链接到正确的实体对象,通过打分的方法对指称项最高的实体作为目标实体。
实体链接的输入包括两部分:
(1)目标实体知识库:知识库通常包括:实体表、实体的文本描述、实体的结构化信息(属性/属性值对)、实体的辅助性信息(实体类别);也经常提供额外的结构化语义信息(实体之间的关联)。
(2)待消歧实体指称项及其上下文信息。
1.3.1 实现实体链接的方法
(1)向量空间模型
基于实体指称项上下文与目标实体上下文中特征的共现信息来确定。向量表示抽取有效的特征表示,有效地计算向量之间的相似度。
(2)主题一致性模型
实体指称项的候选实体概念与指称项上下文中的其他实体概念的一致性程度
(3)协同实体链接
上面只处理单个实体指称项的链接问题,忽略了单篇文档内所有实体指称项的目标实体之间的关系。对文档内所有实体指称项进行协同链接有助于提升实体链接的性能。
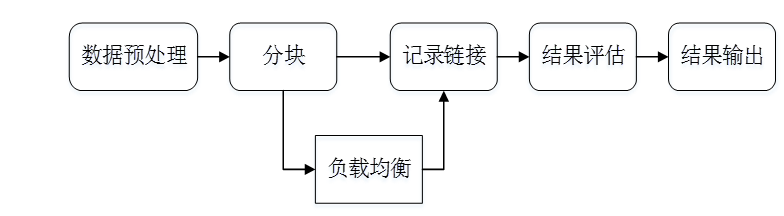
2知识融合常见的流程和步骤

2.1数据预处理
数据预处理阶段,原始数据的质量会直接影响到最终链接的结果,不同的数据集对同一实体的描述方式往往是不相同的,对这些数据进行归一化是提高后续链接精确度的重要步骤。常用的数据预处理有:
语法正规化:
语法匹配:如联系电话的表示方法
综合属性:如家庭地址的表达方式
数据正规化:
移除空格、《》、“”、-等符号
输入错误类的拓扑错误
用正式名字替换昵称和缩写等
2.2 分块 (Blocking)
从给定的知识库中的所有实体对中,选出潜在匹配的记录对作为候选项,并将候选项的大小尽可能的缩小。这么做的原因是因为数据太多了不可能去一一连接。常用的分块方法有基于Hash函数的分块、邻近分块等。
2.3 负载均衡
负载均衡 (Load Balance)来保证所有块中的实体数目相当,从而保证分块对性能的提升程度。最简单的方法是多次Map-Reduce操作。
2.4记录链接
假设两个实体的记录x 和y, x和y在第i个属性上的值是<script type = "math/tex" id="MathJax-Element-8">x_i, y_i</script>, 那么通过如下两步进行记录连接:
属性相似度: 综合单个属性相似度得到属性相似度向量:
实体相似度: 根据属性相似度向量得到一个实体的相似度。
2.4.1属性相似度的计算
属性相似度的计算有多种方法,常用的有编辑距离、集合相似度计算、基于向量的相似度计算等。
(1)编辑距离: Levenstein、 Wagner and Fisher、 Edit Distance with Afine Gaps
(2)集合相似度计算: Jaccard系数, Dice
(3)基于向量的相似度计算: Cosine相似度、TFIDF相似度
2.4.2实体相似度的计算
使用聚类的方法如层次聚类,相关性聚类,Canopy+k-means,使用聚合的方法如加权平均,手动制定规则,分类器等,还可以使用知识表示学习的方法如联合知识嵌入方法等。
(1)基于聚合的方法:
1)加权平均:对相似度得分向量的各个分量进行加权求和,得到最终的实体相似度
2)手动制定规则:给每一个相似度向量的分量设置一个阈值,若超过该阈值则将两实体相连
3)分类器:采用无监督/半监督训练生成训练集合分类
(2)基于聚类的方法:
1)层次聚类:通过计算不同类别数据点之间的相似度对在不同的层次的数据进行划分,最终形成树状的聚类结构。
2)相关性聚类:使用最小的代价找到一个聚类方案。
3)Canopy + K-means:不需提前指定K值进行聚类
(3)基于知识表示学习的方法
将知识图谱中的实体和关系都映射低维空间向量,直接用数学表达式来计算各个实体之间相似度。这类方法不依赖任何的文本信息,获取到的都是数据的深度特征。如使用联合知识嵌入将两个KG的三元组糅合在一起共同训练,并将预链接实体对视为具有SameAS关系的三元组,从而对两个KG的空间进行约束,通过带参数共享和软对齐的TransE实现
3.知识融合实践
3.1TF-IDF(Term Frequency-inverse Document Frequency)
TF-IDF是一种针对关键词的统计分析方法,用于评估一个词对一个文件集或者一个语料库的重要程度。一个词的重要程度跟它在文章中出现的次数成正比,跟它在语料库出现的次数成反比。这种计算方式能有效避免常用词对关键词的影响,提高了关键词与文章之间的相关性。


![]()
3.2 去重重复实体和相关信息。
数据集:example_input_with_true_ids.csv;example_messy_input.csv

标签是True Id,特征为:Sitename, Address, Zip, Phone。
按照上面标的Id号给出相关的信息。第一条信息对应着上面Id=0的样本。

对于所选取的特征进行判断,运行完之后生成结果:

预测结果中,重复数据的ID号预测相同。
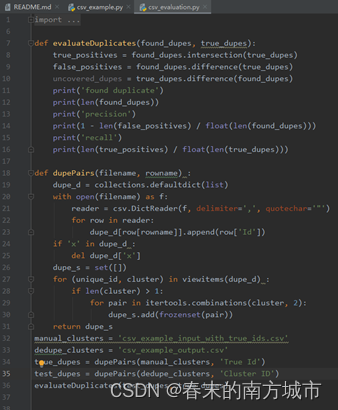
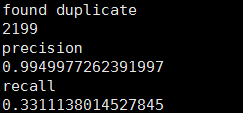
模型预测:通过计算预测值和真实值得交集和差集的个数进行准确率和回归率的计算。该例子有2199个重复样本,准确率为0.9949977%,回归率为0.33。
3.3 知识链接(将两个不同的数据集连接起来),
用余弦相似性度量原理对文本类型字段进行比较。
要求:待连接的两个数据集中每个数据集都不应包含重复的数据集。来自第一个数据集的记录最多且只能匹配来自第二个数据集的一个记录或者不匹配,即要么不匹配要么只能匹配一个,所以如果一个数据集下有重复数据。
数据集:AbtBuy_Abt.csv,AbtBuy_Buy.csv,格式一样,都包含四个字段。unique_id, title, description, price. Unique_id 含义是两个样本是否是一个样本,若是Unique_id是相同的。


代码功能是判断来自两个表的这一样本对是不是同一种标识。表中出现了Text类型数据,该方法就是使用余弦相似性度量对文本类型字段进行比较。这是两个文件所共有的单词量的度量。由于稀有词的重叠比普通词的重叠更重要,所以这个方法可以更有用。还可以根据不同场景下的语料库去学习权重。

最终生成的预测结果:
Cluster ID:是否属于同一知识的标示
source file:数据集的来源,如果来源于第一个csv为0,否则为1.
unique_id:就是原csv中的unique_id
模型评价:
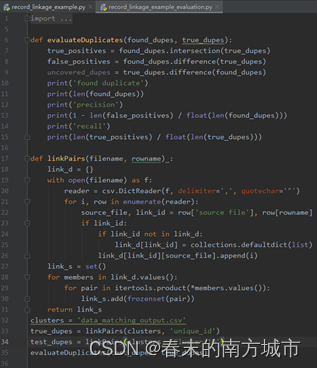
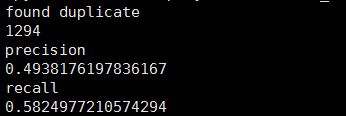
表示两张表中有1294个样本属于同一个标识。
3.4 消除歧义
person_id :表示人的id
Lat Lng:发明者的地址(经纬度)
Coauthor:合著者
Name:发明人名字
Class:分配给该发明人的专利上的4位数ipc技术代码

若person_id 的 leuven_id相同就代表是同一类

结果:(消除歧义后)

3.5 基于Silk的知识融合
Silk是一个集成异构数据源的开源框架。编程语言为Python。提供了专门的 Silk-LSL 语言来进行具体处理。提供了图形化用户界面Silk Workbench,用户可以很方便的进行记录链接。Silk 的整体框架如下图所示:
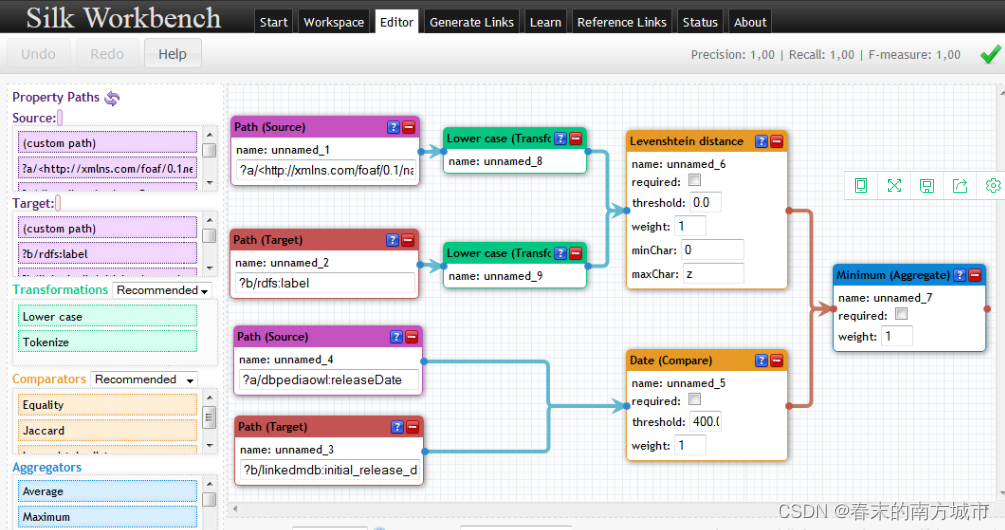
Workbench 引导用户完成创建链接任务的过程,以便链接两个数据源。它提供以下组件:工作区(workspace) 浏览器:允许用户浏览工作区中的项目。链接任务可以从项目加载并稍后返回。链接规则编辑器(Linkage Rule Editor):一种图形编辑器,使用户可以轻松创建和编辑链接规则。 窗口小部件将在树视图中显示当前链接规范,同时允许使用拖放进行编辑。评估(Evaluation):允许用户执行当前的链接规则。 在即时生成链接时会显示这些链接。生成的链接参考链接集未指定其正确性,用户可以确认或拒绝其正确性。用户可以请求关于如何组成特定链接的相似性得分的详细摘要。
3.6 使用Dedupe包实现实体匹配
dedupe是一个python 包,在知识融合领域有着重要作用!主要就是用来实体匹配。dedupe是一个用于fuzzy matching, record deduplication 和 entity-resolution的python库。它基于active learing的方法,只需用户标注它在计算过程选择的少量数据,即可有效地训练出复合的blocking方法和record间相似性的计算方法,并通过聚类完成匹配。dedupe支持多种灵活的数据类型和自定义类型。
dedupe 论文:http://www.cs.utexas.edu/~ml/papers/marlin-dissertation-06.pdf
dedupe 源码:https://github.com/dedupeio/dedupe
dedupe demo: GitHub - dedupeio/dedupe-examples: Examples for using the dedupe library
dedupe 中文网站:dedupe: 知识链接python库 - 工具 - 开放知识图谱
dedupe 官方网站:Dedupe 2.0.11 — dedupe 2.0.11 documentation
dedupe API说明:Library Documentation — dedupe 2.0.11 documentation
3.7 真实例子实践
3.7.1 去重重复实体和相关信息。
数据集:example_input_with_true_ids.csv;example_messy_input.csv
标签是True Id,特征为:Sitename, Address, Zip, Phone。
按照上面标的Id号给出相关的信息。
运行过程中,将不能做出判断的样本打印出来让人工来判断,3种结果即y(是重复),n(不是重复),u(不确定)。
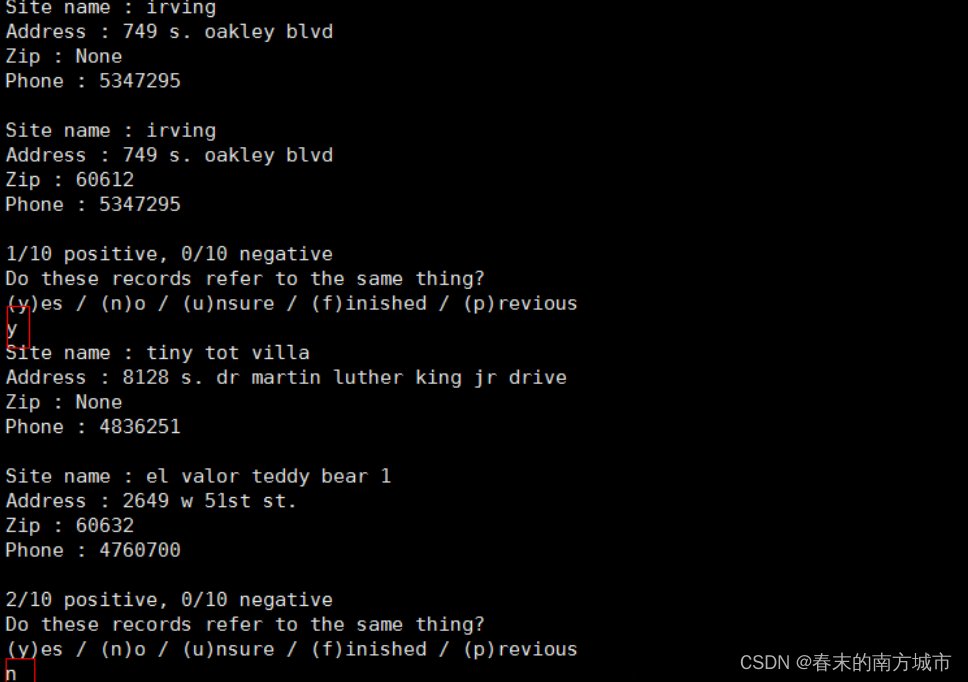
预测结果中,重复数据的ID号预测相同。
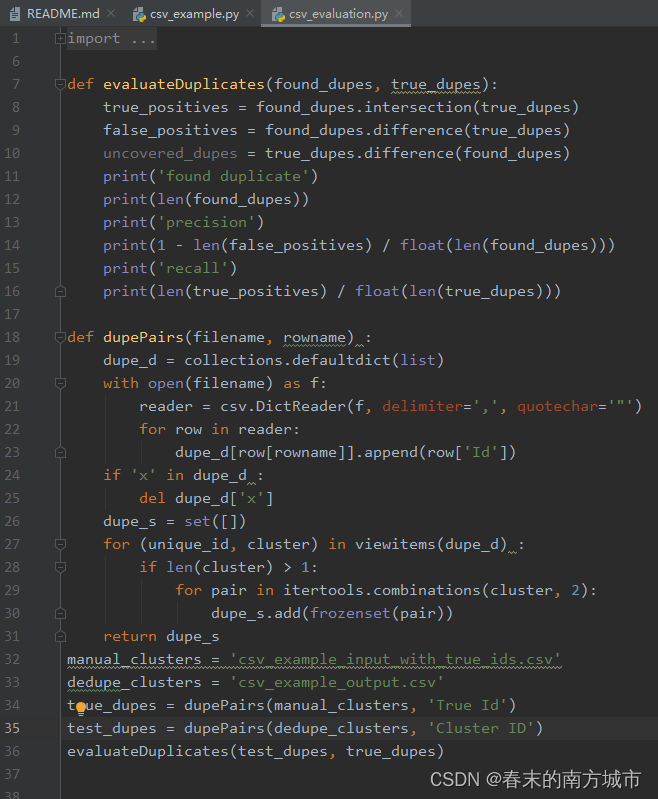
模型预测:通过计算预测值和真实值得交集和差集的个数进行准确率和回归率的计算。该例子有2199个重复样本,准确率为0.9949977%,回归率为0.33。
3.7.2 知识链接
将两个不同的数据集连接起来,用余弦相似性度量对文本类型字段进行比较,余弦相似性度量原理
要求:待连接的两个数据集中每个数据集都不应包含重复的数据集。来自第一个数据集的记录最多且只能匹配来自第二个数据集的一个记录或者不匹配,即要么不匹配要么只能匹配一个,所以如果一个数据集下有重复数据。
数据集:AbtBuy_Abt.csv,AbtBuy_Buy.csv,格式一样,都包含四个字段。unique_id, title, description, price.

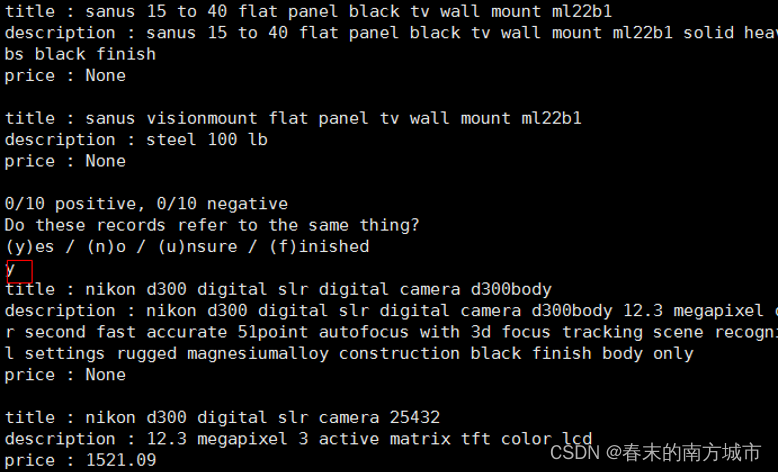
代码功能是判断来自两个表的这一样本对是不是同一种标识。
最终生成的预测结果:
Cluster ID:是否属于同一知识的标示
source file:数据集的来源,如果来源于第一个csv为0,否则为1.
unique_id:就是原csv中的unique_id
模型评价:

表示两张表中有1294个样本属于同一个标识。
3.7.3 消除歧义
person_id :表示人的id
Lat Lng:发明者的地址(经纬度)
Coauthor:合著者
Name:发明人名字
Class:分配给该发明人的专利上的4位数ipc技术代码
若person_id 和 leuven_id相同就代表是同一类
结果:(消除歧义后)
总结:基于dedupe的相关例子,本质上都是去除重复,通过各种数据类型来对样本进行比较,计算相似度,再进行聚类,达到将重复的数据聚集到同一类下,实现去重的目的。