文章目录
引言
本篇记上篇原理后对整个构建知识图谱的过程进行一个比较系统的实践过程。同样,实验代码记录自实验楼的射雕英雄传,根据个人习惯与理解程度,进行了重新排版与修改,实验过程与结果在个人腾讯云上完成。
命名实体识别
1. 数据预处理
原始文本和标签分别定义为:
raw_text = '''张无忌,金庸武侠小说《倚天屠龙记》人物角色,中土明教第三十四代教主。武当七侠之一张翠山与天鹰教紫微堂主殷素素之子,明教四大护教法王之一金毛狮王谢逊义子。
张翠山,《倚天屠龙记》第一卷的男主角,在武当七侠之中排行第五,人称张五侠。与天鹰教殷素素结为夫妇,生下张无忌,后流落到北极冰海上的冰火岛,与谢逊相识并结为兄弟。
殷素素,金庸武侠小说《倚天屠龙记》第一卷的女主人公。天鹰教紫薇堂堂主,容貌娇艳无伦,智计百出,亦正亦邪。与武当五侠张翠山同赴王盘山,结果被金毛狮王谢逊强行带走,三人辗转抵达冰火岛。殷素素与张翠山在岛上结为夫妇,并诞下一子张无忌。
谢逊,是金庸武侠小说《倚天屠龙记》中的人物,字退思,在明教四大护教法王中排行第三,因其满头金发,故绰号“金毛狮王”。
'''
annotations = {
'name':['张无忌','张翠山','殷素素','谢逊'], 'book':['倚天屠龙记'],'org':['明教','武当','天鹰教']}
raw_text, annotations
将标注转换为 BMEO 格式:
import re
# 先去掉原始文本中的换行和空格符
raw_text = raw_text.replace('\n', '').replace(' ', '')
# 初始化 label:将其全部初始化为 O
labels = len(raw_text)*['O']
# 通过 key-value 的方式遍历 annotations 字典,进行转换
for ann, entities in annotations.items():
for entity in entities:
# 先生成实体对应的 BME 标注类型
B, M, E = [['{}_{}'.format(ann,i)] for i in ['B','M','E']]
# 计算实体词中的数量
M_len = len(entity) - 2
# 生成 label,如果词中数为0,则直接为 BE,不然按数量添加 M
label = B + M * M_len + E if M_len else B + E
# 从原始文本中找到实体对应出现的所有位置
idxs = [r.start() for r in re.finditer(entity, raw_text)]
for idx in idxs:
# 替换原 label 中的 O 为实际 label
labels[idx:idx+len(entity)] = label
# 打印原始文本和对应转换后的 label
for ann,label in zip(raw_text,labels):
print(ann, label)
"""
张 name_B
无 name_M
忌 name_E
, O
金 O
庸 O
武 O
侠 O
小 O
说 O
《 O
倚 book_B
天 book_M
屠 book_M
龙 book_M
记 book_E
......
"""
数据预处理,先统计训练集中每个字出现的次数,然后建立字典表,只记录出现次数不小于 2 的字:
from collections import Counter
import numpy as np
from keras.preprocessing.sequence import pad_sequences
# 统计每个字出现的次数
word_counts = Counter(raw_text)
# 建立字典表,只记录出现次数不小于 2 的字
vocab = [w for w, f in iter(word_counts.items()) if f >= 2]
word_counts, vocab
"""
(Counter({'张': 8,
'无': 4,
'忌': 3,
',': 21,
'金': 7,
'庸': 3,
'武': 6,
'侠': 7,
......
'下',
'冰',
'上',
'火',
'岛',
'并',
'亦'])
"""
原始的数据集是字符串格式的,每句话用句号隔开,在训练过程中,我们需要把每句话拆开作为一个样本,因为每句话的长度不同,所以要定义一个最大长度,对于小于这个最大长度的句子,在左边或者右边填充固定的数字。
label_set = list(set(labels))
# 拆分训练集,每一句话作为一个样本,先找到每个句号的位置
sentence_len = [r.start()+1 for r in re.finditer('。', raw_text)]
# 进行拆分,这里要注意最后一个句号后面不需要拆分,所以最后一个位置不需要取到
split_text = np.split(list(raw_text), sentence_len[:-1])
split_label = np.split(labels, sentence_len[:-1])
split_text, split_label
"""
([array(['张', '无', '忌', ',', '金', '庸', '武', '侠', '小', '说', '《', '倚', '天',
'屠', '龙', '记', '》', '人', '物', '角', '色', ',', '中', '土', '明', '教',
'第', '三', '十', '四', '代', '教', '主', '。'], dtype='<U1'),
array(['武', '当', '七', '侠', '之', '一', '张', '翠', '山', '与', '天', '鹰', '教',
'紫', '微', '堂', '主', '殷', '素', '素', '之', '子', ',', '明', '教', '四',
'大', '护', '教', '法', '王', '之', '一', '金', '毛', '狮', '王', '谢', '逊',
'义', '子', '。'], dtype='<U1'),
array(['张', '翠', '山', ',', '《', '倚', '天', '屠', '龙', '记', '》', '第', '一',
'卷', '的', '男', '主', '角', ',', '在', '武', '当', '七', '侠', '之', '中',
'排', '行', '第', '五', ',', '人', '称', '张', '五', '侠', '。'], dtype='<U1'),
.......
"""
构建词袋模型,这里要将字典从 2 开始编号,把 0 和 1 空出来,0 作为填充元素,1 作为不在字典中的字的编号
word2idx = dict((w,i+2) for i,w in enumerate(vocab))
label2idx = [[label_set.index(w) for w in s] for s in split_label]
word2idx, label2idx
构建输入,即对于样本中每一个字,从词袋模型中找到这个字对应的 idx,出现频率过低的字,并没有出现在词袋模型
# 构建输入,即对于样本中每一个字,从词袋模型中找到这个字对应的 idx,出现频率过低的字,并没有出现在词袋模型中,此时将这些字的 idx 取为 1
train_x = [[word2idx.get(w, 1) for w in s] for s in split_text]
max_len = 64
# 在输入的左边填充 0,在输出的左端填充-1
train_x = pad_sequences(train_x, max_len, value=0)
train_y = pad_sequences(label2idx, max_len, value=-1)
train_y = np.expand_dims(train_y, 2)
train_x.shape, train_y.shape
"""
((9, 64), (9, 64, 1))
"""
2. 构建模型并预测
在 Keras 中,已经包含了 BiLSTM 模型中的各个组件,只需导入构建就可以了,而 CRF 层需要导入第三方库 keras-contrib 来使用。
from keras.models import Sequential
from keras.layers import Embedding, Bidirectional, LSTM
from keras_contrib.layers import CRF
from keras_contrib.losses import crf_loss
# 定义模型的超参
EMBED_DIM = 200
BiRNN_UNITS = 200
# 初始化模型
model = Sequential()
# 添加 Embedding 层,将输入转换成向量
model.add(Embedding(len(vocab)+2, EMBED_DIM, mask_zero=True))
# 添加 BiLstm 层
model.add(Bidirectional(LSTM(BiRNN_UNITS // 2, return_sequences=True)))
# 初始化 crf
crf = CRF(len(train_y), sparse_target=True)
# 将 crf 添加到模型中
model.add(crf)
model.summary()
# 编译模型
model.compile('adam', loss=crf_loss, metrics=[crf.accuracy])
"""
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, None, 200) 13600
_________________________________________________________________
bidirectional_1 (Bidirection (None, None, 200) 240800
_________________________________________________________________
crf_1 (CRF) (None, None, 9) 1908
=================================================================
Total params: 256,308
Trainable params: 256,308
Non-trainable params: 0
_________________________________________________________________
WARNING:tensorflow:From /xxxxxx/optimizers.py:790: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.
"""
模型训练:
model.fit(train_x, train_y, batch_size=9, epochs=120)
model.save('model.h5')
"""
......
Epoch 118/120
9/9 [==============================] - 0s 11ms/step - loss: 1.9226 - crf_viterbi_accuracy: 0.9421
Epoch 119/120
9/9 [==============================] - 0s 11ms/step - loss: 1.9138 - crf_viterbi_accuracy: 0.9421
Epoch 120/120
9/9 [==============================] - 0s 12ms/step - loss: 1.9049 - crf_viterbi_accuracy: 0.9421
"""
模型预测:
text = '谢逊,是金庸武侠小说《倚天屠龙记》中的人物,字退思,在明教四大护教法王中排行第三,因其满头金发,故绰号“金毛狮王"。'
# 将预测数据转换为特征向量
pred_x = [word2idx.get(w, 1) for w in text]
pred_x = pad_sequences([pred_x], max_len)
# 使用模型进行预测
pred = model.predict(pred_x)
# 去除多余的维度
pred = np.squeeze(pred)[-len(text):]
# 把输出向量转换为 label 对应的 idx
result = [np.argmax(r) for r in pred]
# 打印输出结果
reslut_labels = [label_set[i] for i in result]
for w, l in zip(text, reslut_labels):
print(w, l)
3. 总结
我们会发现与前面基本一致,至此,一个简单的命名实体识别实验,结束。
在本实验中,我们了解了命名实体识别任务的定义,并用了 BiLstm-CRF 模型,结合简单的数据集实现了整个命名实体识别任务中的数据处理、训练与预测。 虽然在本节实验中数据集规模较小,而且并没有切分验证集与测试集,但在实际的调试中,为了先确保数据管道与网络模型是否搭建正确,应先用少量数据集训练至过拟合,然后逐渐增大数据规模,并切分验证集和测试集,在验证集上对模型进行调优。
关系抽取
1. 数据预处理
生成原始文本和标签定义,并将 lists 中的实体、关系与文本都单独拆分开来,并对文本进行位置编码。
# 对于 lists 中每一个子列表,第一个元素为实体1,第二个元素为实体2,第三个元素为实体1对实体2的关系,第四个元素为文本。
lists = [['杨康','杨铁心','子女','杨康,杨铁心与包惜弱之子,金国六王爷完颜洪烈的养子。'],
['杨康','杨铁心','子女','丘处机与杨铁心、郭啸天结识后,以勿忘“靖康之耻”替杨铁心的儿子杨康取名。'],
['杨铁心','包惜弱','配偶','金国六王爷完颜洪烈因为贪图杨铁心的妻子包惜弱的美色,杀害了郭靖的父亲郭啸天。'],
['杨铁心','包惜弱','配偶','杨康,杨铁心与包惜弱之子,金国六王爷完颜洪烈的养子。'],
['张翠山','殷素素','配偶','张无忌,武当七侠之一张翠山与天鹰教紫微堂主殷素素之子。'],
['小龙女','杨过','师傅','小龙女是杨过的师父,与杨过互生情愫,但因师生恋不容于世。'],
['黄药师','黄蓉','父','黄药师,黄蓉之父,对其妻冯氏(小字阿衡)一往情深。'],
['郭啸天','郭靖','父','郭靖之父郭啸天和其义弟杨铁心因被段天德陷害,死于临安牛家村。']]
relation2idx = {
'子女':0,'配偶':1,'师傅':2,'父':3}
datas, labels, pos_list1, pos_list2 = [], [], [], []
translation = 32
for entity1, entity2, relation, text in lists:
# 找到第一个实体出现的下标
idx1 = text.index(entity1)
# 找到第二个实体出现的下标
idx2 = text.index(entity2)
sentence, pos1, pos2 = [], [], []
for i, w in enumerate(text):
sentence.append(w)
# 计算句子中每个字与实体1首字的距离
pos1.append(i-idx1+translation)
# 计算句子中每个字与实体2首字的距离
pos2.append(i-idx2+translation)
datas.append(sentence)
labels.append(relation2idx[relation])
pos_list1.append(pos1)
pos_list2.append(pos2)
datas, labels, pos_list1, pos_list2
"""
([['杨',
'康',
',',
'杨',
'铁',
'心',
'与',
'包',
'惜',
'弱',
......
53,
54,
55,
56,
57,
58,
59,
60,
61]])
"""
统计每个字出现的次数,并构建词袋模型:
from collections import Counter
word_counts = Counter(sum(datas, []))
# 建立字典表,只记录出现次数不小于 2 的字
vocab = [w for w, f in iter(word_counts.items()) if f >= 2]
# 构建词袋模型,和上一节实验相同,将字典从 2 开始编号,把 0 和 1 空出来,0 作为填充元素,1 作为不在字典中的字的编号
word2idx = dict((w,i+2) for i,w in enumerate(vocab))
word2idx
"""
{'杨': 2,
'康': 3,
',': 4,
'铁': 5,
'心': 6,
......
'生': 39,
'情': 40,
'于': 41,
'黄': 42,
'其': 43}
"""
构建模型的输入数据集:
import numpy as np
from keras.preprocessing.sequence import pad_sequences
from keras.utils.np_utils import to_categorical
# 构建输入,即对于样本中每一个字,从词袋模型中找到这个字对应的 idx,出现频率过低的字,并没有出现在词袋模型中,此时将这些字的 idx 取为 1
train_x = [[word2idx.get(w, 1) for w in s] for s in datas]
max_len = 64
# 在输入的左边填充 0
train_x = pad_sequences(train_x, max_len, value=0)
## 填充位置编码
train_pos1 = pad_sequences(pos_list1, max_len, value=0)
train_pos2 = pad_sequences(pos_list2, max_len, value=0)
# one_hot 编码 label
train_y = to_categorical(labels, num_classes=len(relation2idx))
train_x.shape, train_y.shape, train_pos1.shape, train_pos2.shape
"""
((8, 64), (8, 4), (8, 64), (8, 64))
"""
2. 模型构建并预测
因为网络有多个输入:文本与位置编码,属于复杂模型,因此我们这里使用 Keras 的函数式 API 来定义网络结构:
from keras.layers import Input, Embedding, concatenate, Conv1D, GlobalMaxPool1D, Dense, LSTM
from keras.models import Model
# 定义输入层
words = Input(shape=(max_len,),dtype='int32')
position1 = Input(shape=(max_len,),dtype='int32')
position2 = Input(shape=(max_len,),dtype='int32')
# Embedding 层将输入进行编码
pos_emb1 = Embedding(output_dim=16, input_dim=256)(position1)
pos_emb2 = Embedding(output_dim=16, input_dim=256)(position2)
word_emb = Embedding(output_dim=16, input_dim=256)(words)
# 分别拼接 文本编码与位置1 和文本编码与位置2
concat1 = concatenate([word_emb, pos_emb1])
concat2 = concatenate([word_emb, pos_emb2])
# 卷积池化层
conv1 = Conv1D(filters=128, kernel_size=3)(concat1)
pool1 = GlobalMaxPool1D()(conv1)
conv2 = Conv1D(filters=128, kernel_size=3)(concat2)
pool2 = GlobalMaxPool1D()(conv2)
# 拼接,最后接全连接层,激活函数为 softmax
concat = concatenate([pool1, pool2])
out = Dense(units=len(relation2idx),activation='softmax')(concat)
model = Model(inputs=[words, position1, position2],outputs=out)
# 编译模型
model.compile(optimizer='ADAM', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
"""
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 64) 0
__________________________________________________________________________________________________
input_2 (InputLayer) (None, 64) 0
__________________________________________________________________________________________________
input_3 (InputLayer) (None, 64) 0
__________________________________________________________________________________________________
embedding_3 (Embedding) (None, 64, 16) 4096 input_1[0][0]
__________________________________________________________________________________________________
embedding_1 (Embedding) (None, 64, 16) 4096 input_2[0][0]
__________________________________________________________________________________________________
embedding_2 (Embedding) (None, 64, 16) 4096 input_3[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 64, 32) 0 embedding_3[0][0]
embedding_1[0][0]
__________________________________________________________________________________________________
concatenate_2 (Concatenate) (None, 64, 32) 0 embedding_3[0][0]
embedding_2[0][0]
__________________________________________________________________________________________________
conv1d_1 (Conv1D) (None, 62, 128) 12416 concatenate_1[0][0]
__________________________________________________________________________________________________
conv1d_2 (Conv1D) (None, 62, 128) 12416 concatenate_2[0][0]
__________________________________________________________________________________________________
global_max_pooling1d_1 (GlobalM (None, 128) 0 conv1d_1[0][0]
__________________________________________________________________________________________________
global_max_pooling1d_2 (GlobalM (None, 128) 0 conv1d_2[0][0]
__________________________________________________________________________________________________
concatenate_3 (Concatenate) (None, 256) 0 global_max_pooling1d_1[0][0]
global_max_pooling1d_2[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 4) 1028 concatenate_3[0][0]
==================================================================================================
Total params: 38,148
Trainable params: 38,148
Non-trainable params: 0
"""
模型训练:
model.fit([train_x, train_pos1, train_pos2], train_y, batch_size=8, epochs=50)
model.save('model.h5')
"""
Epoch 48/50
8/8 [==============================] - 0s 4ms/step - loss: 0.4164 - acc: 1.0000
Epoch 49/50
8/8 [==============================] - 0s 2ms/step - loss: 0.3934 - acc: 1.0000
Epoch 50/50
8/8 [==============================] - 0s 997us/step - loss: 0.3710 - acc: 1.0000
"""
模型预测:
test_instance = ['张翠山','殷素素','张无忌,武当七侠之一张翠山与天鹰教紫微堂主殷素素之子。']
# 将预测数据转换为向量
pred_x = [word2idx.get(w, 1) for w in test_text]
idx1 = test_text.index(test_ne1)
idx2 = test_text.index(test_ne2)
pos1 = [i-idx1+translation for i in range(len(test_text))]
pos2 = [i-idx2+translation for i in range(len(test_text))]
pred_x = pad_sequences([pred_x], max_len, value=0)
test_pos1 = pad_sequences([pos1], max_len, value=0)
test_pos2 = pad_sequences([pos2], max_len, value=0)
# 翻转 relation2idx 字典
idx2relation = dict(zip(relation2idx.values(),relation2idx.keys()))
# 使用模型进行预测
pred = model.predict([pred_x, test_pos1, test_pos2])
# 模型预测最大值的位置作为预测值
output_idx = np.argmax(pred)
# 找到 idx2relation 中实际的标签
output_label = idx2relation[output_idx]
pred, output_idx, output_label
"""
(array([[0.07475965, 0.7902418 , 0.04980448, 0.08519404]], dtype=float32),
1,
'配偶')
"""
3. 总结
至此,就完成了一个小型的网络来实现任务中的抽取预测。由于小型的神经网络的参数量较少,拟合能力有限,从而随着训练数据量的增加就会出现欠拟合的现象。因此,用少量数据集在小型网络上训练完成后,再逐渐增大数据量,同时将小型网络复杂化,如使用现有的 PCNN,Attention-BiLSTM 等用于关系抽取的经典神经网络结构,将任务的精度提升到我们想要的结果。
数据入库
neo4j数据库插入数据有三种方式,分别为:
- load csv 批量导入方法
- neo4j-admin import 批量导入方法
- Cypher 实战用法
load csv方式
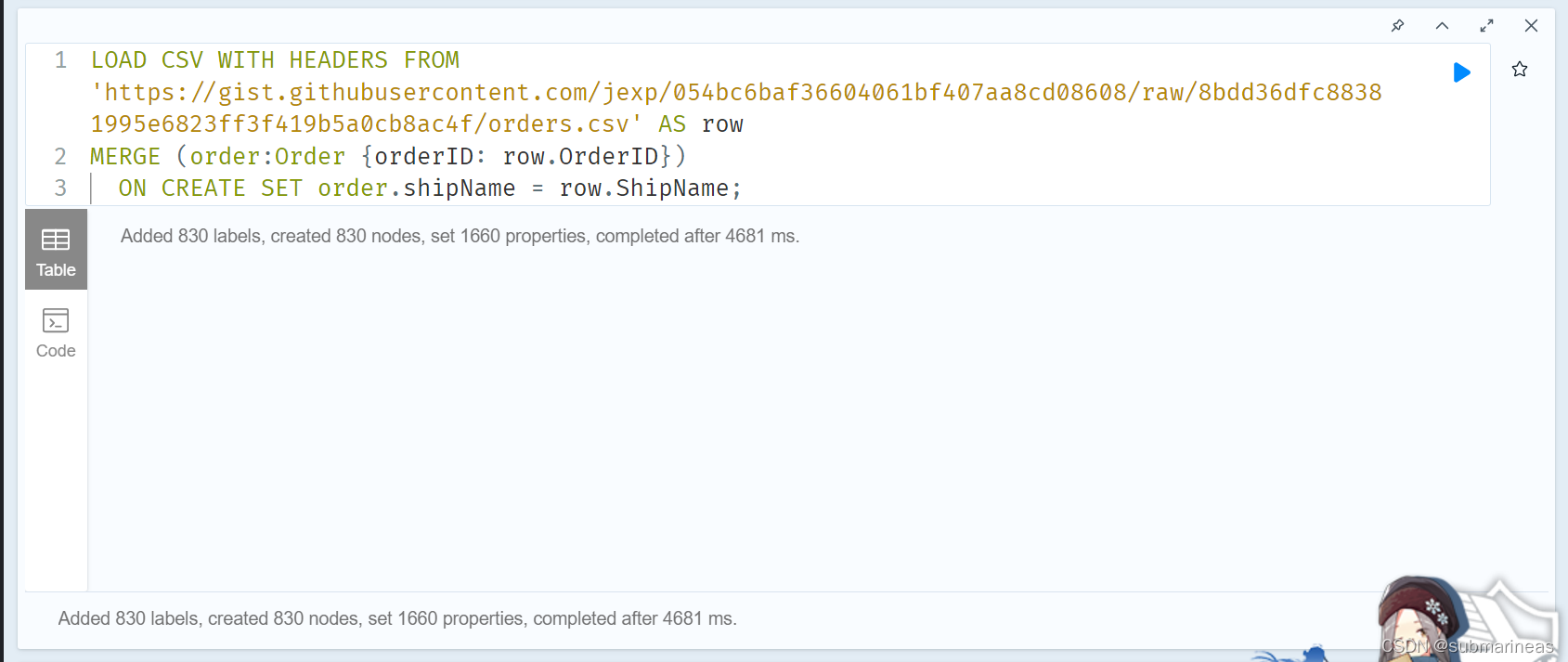
LOAD CSV 是 Cypher 提供的 ETL(Extract-Transform-Load) 工具, 允许从本地或者互联网上导入 CSV 文件。 导入本地文件时,Neo4j 默认的设置是把文件导入的根目录限制在当前库的 import 文件夹下。
一个单元格中可能为空,或者一个实体,或者多个实体。多个实体之间用中文逗号隔开。所以,我们需要更改neo4j.conf 文件,添加关联关系:
cypher.lenient_create_relationship=true
这一句命令的目的是在构建关系时遇到 null-[]-() 一类的情况时可以自动跳过而不报错。
关于csv文件的导入,这里推荐官网的案例直接跑一遍,因为我发现语法还是有点复杂的,并且如果要建立一个很完整的kg,每个导入语句之间都有很强的关联性,所以官网的demo为:
https://neo4j.com/developer/guide-importing-data-and-etl/
neo4j-admin import方式与Cypher用法
在使用 neo4j-admin import 时,需要先 sudo neo4j stop 停止 Neo4j 服务,同时删除旧的 graph.db 文件(通过 neo4j.conf 可以知道在 /var/lib/neo4j/data/databases 目录下)。这里也不再演示,因为我原来有数据,只是需要注意的是,我在用docker搭建neo4j的过程中,出现了一个问题,如下:

暂时还没有找到什么解决方案,我在搭建的那篇笔记中对这个问题进行了记录和推测,可能是版本,也可能是镜像。说白话可以试试要换了整个服务重新搭。。。这里Mark一下,与cypher,实验了很多个查询和创建语句,但碍于篇幅和理解得不深,这里不再记录了,后续有机会会新开一帖,最后再记录下我在GitHub上找到的一个感觉很不错的demo。
GitHub项目实验
虽然说和上一篇博文内容说的一样,在我整个跑完过后,还是对于KG的概念有些模糊,我对于整个流程还是有所迷惑,所以就去GitHub找到了一些比较好的项目,这里选择花时间最多的一个作为演示效果,其它的放在参考与推荐项里。
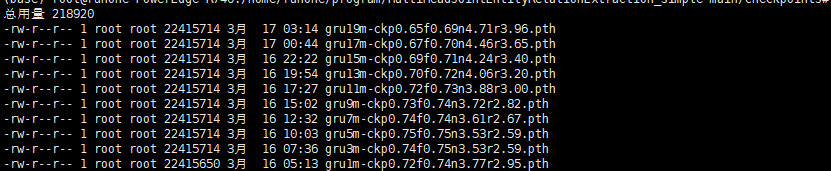
使用了MultiHeadJointEntityRelationExtraction_simple这个项目,根据提示,默认训练了GRU模型,我大概修改了epoch,以及一些比较耗时但没多大必要的层级,但发现依然是很慢,大概一个epoch需要至少一小时:

然后该作者写了批次模型参数保存,与断点训练,我大概训练了20个epoch:
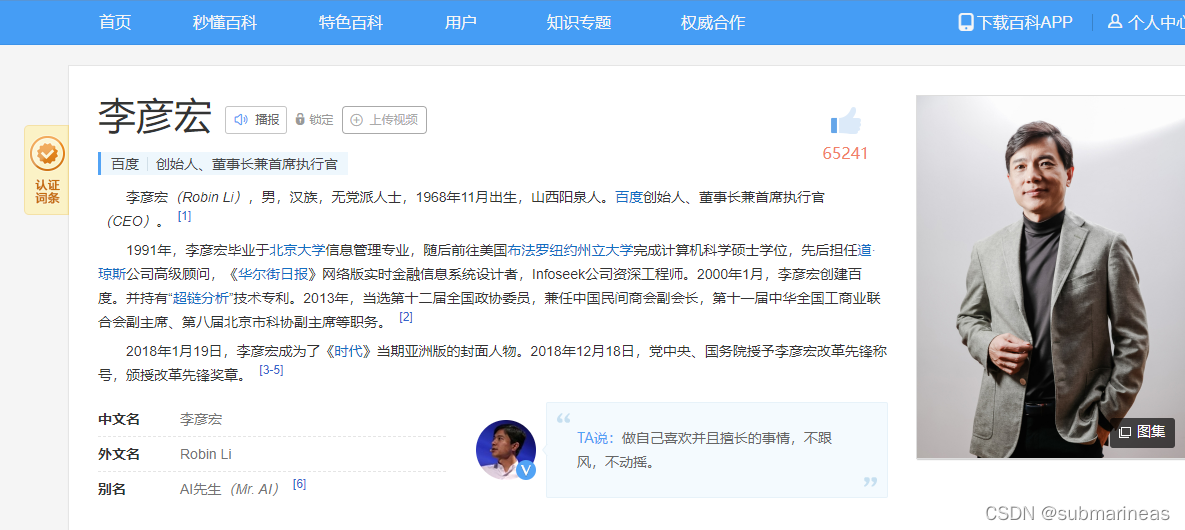
然后将训练出来的模型替换作者的Albert,虽然说Albert效果优于GRU,不过这里以体验为主,至于模型的优劣,等我下次打比赛再来研究研究,然后替换后就能启动web项目,因为训练集是用的百度的CCKS,我看demo用的李彦宏,那么我直接搜索了百度百科上关于李彦宏的介绍:
然后写进web框中:

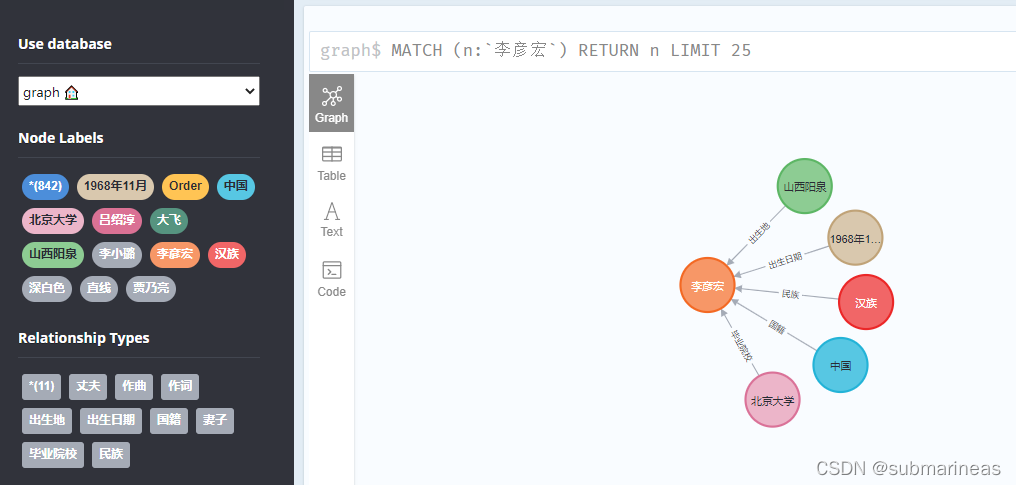
看起来效果不错,emmm,但后续我对其它明星介绍去做抽取,和一些专业术语,发现效果就很差了,一般只有一两个词有相对应上,看来还是数据集和epoch不够。然后这时候,看neo4j上的数据库,就会发现关于李彦宏的信息已经上传上去了:
参考与推荐
-
https://github.com/liuhuanyong/QASystemOnMedicalKG
-
https://github.com/buppt/ChineseNRE
-
https://github.com/wangle1218/KBQA-for-Diagnosis
-
https://github.com/baiyang2464/chatbot-base-on-Knowledge-Graph