回溯算法框架
其实回溯算法和我们常说的 DFS 算法非常类似,本质上就是一种暴力穷举算法。回溯算法和 DFS 算法的细微差别是:回溯算法是在遍历「树枝」,DFS 算法是在遍历「节点」
回溯算法是笔试中最好用的算法,只要你没什么思路,就用回溯算法暴力求解,即便不能通过所有测试用例,多少能过一点
解决一个回溯问题,实际上就是一个决策树的遍历过程,站在回溯树的一个节点上,你只需要思考 3 个问题:
1、路径:也就是已经做出的选择。
2、选择列表:也就是你当前可以做的选择。
3、结束条件:也就是到达决策树底层,无法再做选择的条件。
伪代码框架如下:
result = []
def backtrack(路径, 选择列表):
if 满足结束条件:
result.add(路径)
return
for 选择 in 选择列表:
做选择
backtrack(路径, 选择列表)
撤销选择
其核心就是 for 循环里面的递归,在递归调用之前「做选择」,在递归调用之后「撤销选择」
写 backtrack 函数时,需要维护走过的「路径」和当前可以做的「选择列表」,当触发「结束条件」时,将「路径」记入结果集。
其实想想看,回溯算法和动态规划是不是有点像呢?我们在动态规划系列文章中多次强调,动态规划的三个需要明确的点就是「状态」「选择」和「base case」,是不是就对应着走过的「路径」,当前的「选择列表」和「结束条件」?
初步认识
全排列
我们先来看一道简单的体会一下决策的过程
比方说给三个数 [1,2,3],一般是固定第一位,再选择第二位上的数字

为啥说这是决策树呢,因为你在每个节点上其实都在做决策。
我们定义的 backtrack 函数其实就像一个指针,在这棵树上游走,同时要正确维护每个节点的属性,每当走到树的底层叶子节点,其「路径」就是一个全排列。
N 皇后
给你一个
N×N的棋盘,让你放置N个皇后,使得它们不能互相攻击。皇后可以攻击同一行、同一列、左上左下右上右下四个方向的任意单位返回所有不同的 n 皇后问题 的解决方案
这个问题本质上跟全排列问题差不多,决策树的每一层表示棋盘上的每一行;每个节点可以做出的选择是,在该行的任意一列放置一个皇后
因为皇后是一行一行从上往下放的,所以左下方,右下方和正下方不用检查(还没放皇后);因为一行只会放一个皇后,所以每行不用检查。也就是最后只用检查上面,左上,右上三个方向。
划分为k个相等的子集
给你输入一个数组
nums和一个正整数k,请你判断nums是否能够被平分为元素和相同的k个子集
回溯算法的关键是知道怎么做选择,这样才能利用递归函数进行穷举。
那么模仿排列公式的推导思路,将 n 个数字分配到 k 个桶里,我们也可以有两种视角:
视角一,如果我们切换到这 n 个数字的视角,每个数字都要选择进入到 k 个桶中的某一个。
视角二,如果我们切换到这 k 个桶的视角,对于每个桶,都要遍历 nums 中的 n 个数字,然后选择是否将当前遍历到的数字装进自己这个桶里。
用不同的视角进行穷举,虽然结果相同,但是解法代码的逻辑完全不同,进而算法的效率也会不同;对比不同的穷举视角,可以帮你更深刻地理解回溯算法,我们慢慢道来。
视角一
和二叉树一样我们可以写出遍历数组的递归函数
void traverse(int[] nums, int index) {
if (index == nums.length) {
return;
}
System.out.println(nums[index]);
traverse(nums, index + 1);
}
这种穷举的优化方式就是剪枝(比如桶内数之和大于target就跳过循环),也可以提前对数组进行排序,不过这种视角还是耗时较多
// 主函数
boolean canPartitionKSubsets(int[] nums, int k) {
// 排除一些基本情况
if (k > nums.length) return false;
int sum = 0;
for (int v : nums) sum += v;
if (sum % k != 0) return false;
// k 个桶(集合),记录每个桶装的数字之和
int[] bucket = new int[k];
// 理论上每个桶(集合)中数字的和
int target = sum / k;
// 穷举,看看 nums 是否能划分成 k 个和为 target 的子集
return backtrack(nums, 0, bucket, target);
}
// 递归穷举 nums 中的每个数字
boolean backtrack(
int[] nums, int index, int[] bucket, int target) {
if (index == nums.length) {
// 检查所有桶的数字之和是否都是 target
for (int i = 0; i < bucket.length; i++) {
if (bucket[i] != target) {
return false;
}
}
// nums 成功平分成 k 个子集
return true;
}
// 穷举 nums[index] 可能装入的桶
for (int i = 0; i < bucket.length; i++) {
// 剪枝,桶装装满了
if (bucket[i] + nums[index] > target) {
continue;
}
// 将 nums[index] 装入 bucket[i]
bucket[i] += nums[index];
// 递归穷举下一个数字的选择
if (backtrack(nums, index + 1, bucket, target)) {
return true;
}
// 撤销选择
bucket[i] -= nums[index];
}
// nums[index] 装入哪个桶都不行
return false;
}
视角二
以桶的视角进行穷举,每个桶需要遍历 nums 中的所有数字,决定是否把当前数字装进桶中;当装满一个桶之后,还要装下一个桶,直到所有桶都装满为止。
代码表示如下
// 装满所有桶为止
while (k > 0) {
// 记录当前桶中的数字之和
int bucket = 0;
for (int i = 0; i < nums.length; i++) {
// 决定是否将 nums[i] 放入当前桶中
if (canAdd(bucket, num[i])) {
bucket += nums[i];
}
if (bucket == target) {
// 装满了一个桶,装下一个桶
k--;
break;
}
}
}
那么我们也可以把这个 while 循环改写成递归函数,不过比刚才略微复杂一些,首先写一个 backtrack 递归函数出来
// 现在 k 号桶正在思考是否应该把 nums[start] 这个元素装进来;
// 目前 k 号桶里面已经装的数字之和为 bucket;
// used 标志某一个元素是否已经被装到桶中;
// target 是每个桶需要达成的目标和。
boolean backtrack(int k, int bucket,
int[] nums, int start, boolean[] used, int target) {
// base case
if (k == 0) {
// 所有桶都被装满了,而且 nums 一定全部用完了
// 因为 target == sum / k
return true;
}
if (bucket == target) {
// 装满了当前桶,递归穷举下一个桶的选择
// 让下一个桶从 nums[0] 开始选数字
return backtrack(k - 1, 0 ,nums, 0, used, target);
}
// 从 start 开始向后探查有效的 nums[i] 装入当前桶
for (int i = start; i < nums.length; i++) {
// 剪枝
if (used[i]) {
// nums[i] 已经被装入别的桶中
continue;
}
if (nums[i] + bucket > target) {
// 当前桶装不下 nums[i]
continue;
}
// 做选择,将 nums[i] 装入当前桶中
used[i] = true;
bucket += nums[i];
// 递归穷举下一个数字是否装入当前桶
if (backtrack(k, bucket, nums, i + 1, used, target)) {
return true;
}
// 撤销选择
used[i] = false;
bucket -= nums[i];
}
// 穷举了所有数字,都无法装满当前桶
return false;
}
不过这样的话,时间复杂度会有点高,我们可以利用used数组来优化
假设target是5,一号桶装1和4,二号桶装2和3;一号桶装2和3,二号桶装1和4,算法会认为这是不同的情况,但是,如果前面那种情况行不通的话第二种肯定也行不通
我们可以用一个 memo 备忘录,在装满一个桶时记录当前 used 的状态,如果当前 used 的状态是曾经出现过的,那就不用再继续穷举,从而起到剪枝避免冗余计算的作用
修改之后如下:
// 备忘录,存储 used 数组的状态
HashMap<String, Boolean> memo = new HashMap<>();
boolean backtrack(int k, int bucket, int[] nums, int start, boolean[] used, int target) {
// base case
if (k == 0) {
return true;
}
// 将 used 的状态转化成形如 [true, false, ...] 的字符串
// 便于存入 HashMap
String state = Arrays.toString(used);
if (bucket == target) {
// 装满了当前桶,递归穷举下一个桶的选择
boolean res = backtrack(k - 1, 0, nums, 0, used, target);
// 将当前状态和结果存入备忘录
memo.put(state, res);
return res;
}
if (memo.containsKey(state)) {
// 如果当前状态曾今计算过,就直接返回,不要再递归穷举了
return memo.get(state);
}
// 其他逻辑不变...
}
这样提交解法,发现执行效率依然比较低,这次不是因为算法逻辑上的冗余计算,而是代码实现上的问题。
因为每次递归都要把 used 数组转化成字符串,这对于编程语言来说也是一个不小的消耗,所以我们还可以进一步优化。
注意题目给的数据规模 nums.length <= 16,也就是说 used 数组最多也不会超过 16,那么我们完全可以用「位图」的技巧,用一个 int 类型的 used 变量来替代 used 数组。
具体来说,我们可以用整数 used 的第 i 位((used >> i) & 1)的 1/0 来表示 used[i] 的 true/false。
这样一来,不仅节约了空间,而且整数 used 也可以直接作为键存入 HashMap,省去数组转字符串的消耗。
总结
第一种解法即便经过了排序优化,也明显比第二种解法慢很多
假设 nums 中的元素个数为 n。
先说第一个解法,也就是从数字的角度进行穷举,n 个数字,每个数字有 k 个桶可供选择,所以组合出的结果个数为 k^n,时间复杂度也就是 O(k^n)。
第二个解法,每个桶要遍历 n 个数字,对每个数字有「装入」或「不装入」两种选择,所以组合的结果有 2^n 种;而我们有 k 个桶,所以总的时间复杂度为 O(k*2^n)
这是对最坏复杂度上界的粗略估算
通俗来说,我们应该尽量「少量多次」,就是说宁可多做几次选择(乘法关系),也不要给太大的选择空间(指数关系);做 n 次「k 选一」仅重复一次(O(k^n)),比 n 次「二选一」重复 k 次(O(k*2^n))效率低很多。
排列组合、子集问题
论是排列、组合还是子集问题,简单说无非就是让你从序列 nums 中以给定规则取若干元素,主要有以下几种变体:
形式一、元素无重不可复选,即 nums 中的元素都是唯一的,每个元素最多只能被使用一次,这也是最基本的形式。
以组合为例,如果输入 nums = [2,3,6,7],和为 7 的组合应该只有 [7]。
形式二、元素可重不可复选,即 nums 中的元素可以存在重复,每个元素最多只能被使用一次。
以组合为例,如果输入 nums = [2,5,2,1,2],和为 7 的组合应该有两种 [2,2,2,1] 和 [5,2]。
形式三、元素无重可复选,即 nums 中的元素都是唯一的,每个元素可以被使用若干次。
以组合为例,如果输入 nums = [2,3,6,7],和为 7 的组合应该有两种 [2,2,3] 和 [7]。
但无论形式怎么变化,其本质就是穷举所有解,而这些解呈现树形结构,所以合理使用回溯算法框架,稍改代码框架即可把这些问题一网打尽。
元素无重不可复选
题目给你输入一个无重复元素的数组
nums,其中每个元素最多使用一次,请你返回nums的所有子集
因为集合中的元素不用考虑顺序, [1,2,3] 中 2 后面只有 3,如果你向前考虑 1,那么 [2,1] 会和之前已经生成的子集 [1,2] 重复。
因此,我们通过保证元素之间的相对顺序不变来防止出现重复的子集
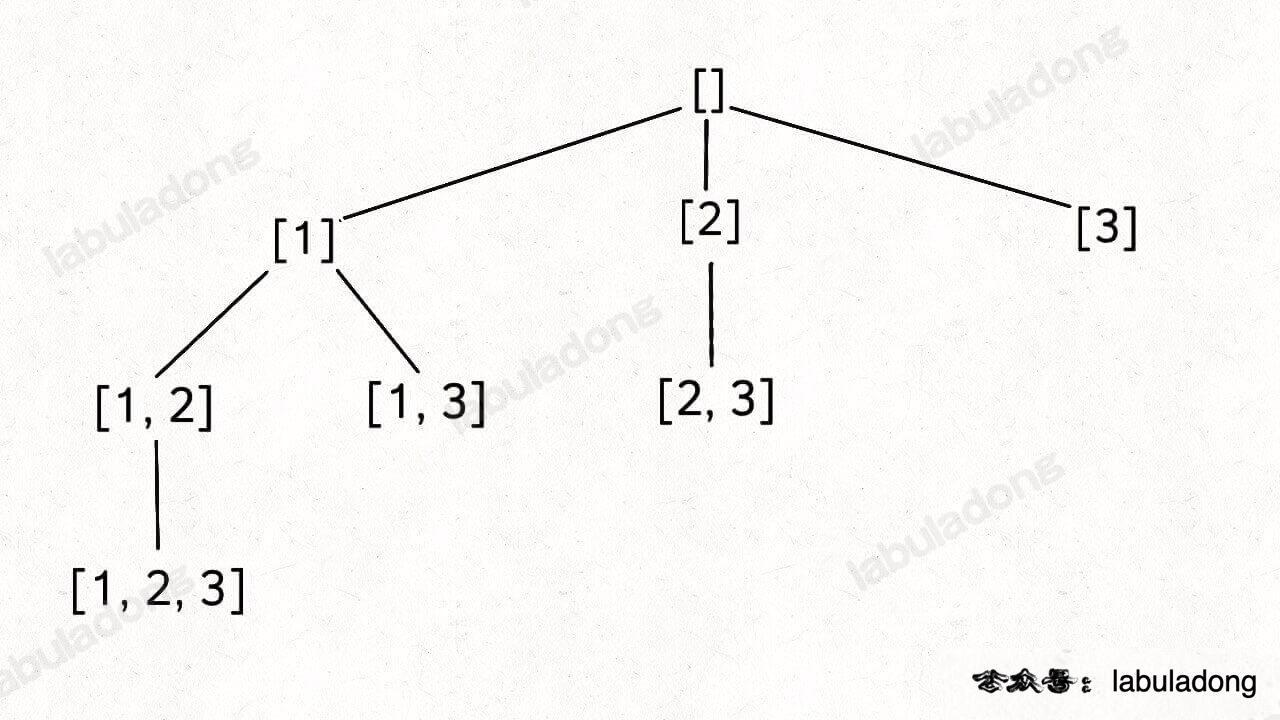
如果把根节点作为第 0 层,将每个节点和根节点之间树枝上的元素作为该节点的值,那么第 n 层的所有节点就是大小为 n 的所有子集
List<List<Integer>> res = new LinkedList<>();
// 记录回溯算法的递归路径
LinkedList<Integer> track = new LinkedList<>();
// 主函数
public List<List<Integer>> subsets(int[] nums) {
backtrack(nums, 0);
return res;
}
// 回溯算法核心函数,遍历子集问题的回溯树
void backtrack(int[] nums, int start) {
// 前序位置,每个节点的值都是一个子集
res.add(new LinkedList<>(track));
// 回溯算法标准框架
for (int i = start; i < nums.length; i++) {
// 做选择
track.addLast(nums[i]);
// 通过 start 参数控制树枝的遍历,避免产生重复的子集
backtrack(nums, i + 1);
// 撤销选择
track.removeLast();
}
}
给定两个整数
n和k,返回范围[1, n]中所有可能的k个数的组合。
在你只需要把第 k 层(根节点视为第 0 层)的节点收集起来,就是大小为 k 的所有组合
全排列前文已经提过,不再赘述
元素可重不可复选
给你一个整数数组
nums,其中可能包含重复元素,请你返回该数组所有可能的子集。
如果一个节点有多条值相同的树枝相邻,则只遍历第一条
体现在代码上,需要先进行排序,让相同的元素靠在一起,如果发现 nums[i] == nums[i-1],则跳过:

List<List<Integer>> res = new LinkedList<>();
LinkedList<Integer> track = new LinkedList<>();
boolean[] used;
public List<List<Integer>> permuteUnique(int[] nums) {
// 先排序,让相同的元素靠在一起
Arrays.sort(nums);
used = new boolean[nums.length];
backtrack(nums);
return res;
}
void backtrack(int[] nums) {
if (track.size() == nums.length) {
res.add(new LinkedList(track));
return;
}
for (int i = 0; i < nums.length; i++) {
if (used[i]) {
continue;
}
// 新添加的剪枝逻辑,固定相同的元素在排列中的相对位置
if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) {
continue;
}
track.add(nums[i]);
used[i] = true;
backtrack(nums);
track.removeLast();
used[i] = false;
}
}
对比一下之前的标准全排列解法代码,这段解法代码只有两处不同:
- 对
nums进行了排序。 - 添加了一句额外的剪枝逻辑。
这么做是为了防止出现重复结, 但是注意排列问题的剪枝逻辑,和子集/组合问题的剪枝逻辑略有不同:新增了 !used[i - 1] 的逻辑判断
排列问题的剪枝逻辑,和子集/组合问题的剪枝逻辑略有不同:新增了 !used[i - 1] 的逻辑判断,原因如下:
假设输入为 nums = [1,2,2'],标准的全排列算法会得出如下答案:
[1,2,2’],[1,2’,2],[2,1,2’],[2,2’,1],[2’,1,2],[2’,2,1]
显然,这个结果存在重复。如果保持排列中 2 一直在 2' 前面,只能挑出 3 个排列符合这个条件,也即是正确答案
进一步,如果 nums = [1,2,2',2''],我只要保证重复元素 2 的相对位置固定,比如说 2 -> 2' -> 2'',也可以得到无重复的全排列结果。标准全排列算法之所以出现重复,是因为把相同元素形成的排列序列视为不同的序列,但实际上它们应该是相同的;而如果固定相同元素形成的序列顺序,当然就避免了重复。子集中要运用到了这样的思路
我们现在再来看剪枝逻辑:
// 新添加的剪枝逻辑,固定相同的元素在排列中的相对位置
if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) {
// 如果前面的相邻相等元素没有用过,则跳过
continue;
}
// 选择 nums[i]
当出现重复元素时,比如输入 nums = [1,2,2',2''],2' 只有在 2 已经被使用的情况下才会被选择,同理,2'' 只有在 2' 已经被使用的情况下才会被选择,这就保证了相同元素在排列中的相对位置保证固定。
元素无重可复选
给你一个无重复元素的整数数组
candidates和一个目标和target,找出candidates中可以使数字和为目标数target的所有组合。candidates中的每个数字可以无限制重复被选取。
标准的子集/组合问题通过下一层回溯树就是从 start + 1 开始,从而保证 nums[start] 这个元素不会被重复使用
反过来,如果我想让每个元素被重复使用,我只要递归函数backtrack(nums, i + 1)把 i + 1 改成 i 即可,最后设置路径和大于 target 时就没必要再遍历下去了
排列情况
nums数组中的元素无重复且可复选的情况下,会有哪些排列
标准的全排列算法利用 used 数组进行剪枝,避免重复使用同一个元素。如果允许重复使用元素的话,直接放飞自我,去除所有 used 数组的剪枝逻辑就行了。
总结
由于子集问题和组合问题本质上是一样的,无非就是 base case 有一些区别,所以把这两个问题放在一起看
形式一、元素无重不可复选,即 nums 中的元素都是唯一的,每个元素最多只能被使用一次
/* 组合、子集问题回溯算法框架 */
void backtrack(int[] nums, int start) {
// 回溯算法标准框架
for (int i = start; i < nums.length; i++) {
// 做选择
track.addLast(nums[i]);
// 注意参数
backtrack(nums, i + 1);
// 撤销选择
track.removeLast();
}
}
/* 排列问题回溯算法框架 */
void backtrack(int[] nums) {
for (int i = 0; i < nums.length; i++) {
// 剪枝逻辑
if (used[i]) {
continue;
}
// 做选择
used[i] = true;
track.addLast(nums[i]);
backtrack(nums);
// 撤销选择
track.removeLast();
used[i] = false;
}
}
形式二、元素可重不可复选,即 nums 中的元素可以存在重复,每个元素最多只能被使用一次,其关键在于排序和剪枝
Arrays.sort(nums);
/* 组合/子集问题回溯算法框架 */
void backtrack(int[] nums, int start) {
// 回溯算法标准框架
for (int i = start; i < nums.length; i++) {
// 剪枝逻辑,跳过值相同的相邻树枝
if (i > start && nums[i] == nums[i - 1]) {
continue;
}
// 做选择
track.addLast(nums[i]);
// 注意参数
backtrack(nums, i + 1);
// 撤销选择
track.removeLast();
}
}
Arrays.sort(nums);
/* 排列问题回溯算法框架 */
void backtrack(int[] nums) {
for (int i = 0; i < nums.length; i++) {
// 剪枝逻辑
if (used[i]) {
continue;
}
// 剪枝逻辑,固定相同的元素在排列中的相对位置
if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) {
continue;
}
// 做选择
used[i] = true;
track.addLast(nums[i]);
backtrack(nums);
// 撤销选择
track.removeLast();
used[i] = false;
}
}
形式三、元素无重可复选,即 nums 中的元素都是唯一的,每个元素可以被使用若干次,只要删掉去重逻辑即可
/* 组合/子集问题回溯算法框架 */
void backtrack(int[] nums, int start) {
// 回溯算法标准框架
for (int i = start; i < nums.length; i++) {
// 做选择
track.addLast(nums[i]);
// 注意参数
backtrack(nums, i);
// 撤销选择
track.removeLast();
}
}
/* 排列问题回溯算法框架 */
void backtrack(int[] nums) {
for (int i = 0; i < nums.length; i++) {
// 做选择
track.addLast(nums[i]);
backtrack(nums);
// 撤销选择
track.removeLast();
}
}
岛屿问题
给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
在二维数组的遍历中,常见的事用方向数组来辅助
同时为了防止重复遍历,我们应该创建一个visited数组,不过我们可以将遇到的岛屿以及其深度遍历到的岛屿的值都设为水,这样就不用visited数组
这是两个常用的技巧
public class Solution {
public static int[][] dirs = {new int[]{-1, 0}, new int[]{1, 0}, new int[]{0, -1}, new int[]{0, 1}};
void DFS(char[][] grid, int r, int c) {
int nr = grid.Length;
int nc = grid[0].Length;
if (r < 0 || c < 0 || r >= nr || c >= nc || grid[r][c] == '0') {
return;
}
grid[r][c] = '0';
foreach (int[] dir in dirs) {
DFS(grid, row + dir[0], col + dir[1]);
}
}
public int NumIslands(char[][] grid) {
if (grid == null || grid.Length == 0) {
return 0;
}
int nr = grid.Length;
int nc = grid[0].Length;
int num_islands = 0;
for (int r = 0; r < nr; ++r) {
for (int c = 0; c < nc; ++c) {
if (grid[r][c] == '1') {
++num_islands;
DFS(grid, r, c);
}
}
}
return num_islands;
}
}
明白了这个基本问题,很多进阶问题都可以转换成这个问题
比如1020. 飞地的数量 - 力扣(LeetCode)支持需要先DFS一遍边界上的陆地,将他们全部设为海洋,剩下认为陆地的就是飞地
695. 岛屿的最大面积 - 力扣(LeetCode)只不过 dfs 函数淹没岛屿的同时,还应该想办法记录这个岛屿的面积。我们可以给 dfs 函数设置返回值,记录每次淹没的陆地的个
1905. 统计子岛屿 - 力扣(LeetCode)先将grid2陆地中不是子岛屿的全部淹没掉,再次遍历得到的岛屿数量就是子岛屿
形状相同的岛屿视为同一种
这样的话需要在DFS函数中添加记录路径逻辑,分别用 1, 2, 3, 4 代表上下左右,用 -1, -2, -3, -4 代表上下左右的撤销,那么可以这样表示它们的遍历顺序
// 前序遍历位置:进入 (i, j)
grid[i][j] = 0;
sb.append(dir).append(',');
dfs(grid, i - 1, j, sb, 1); // 上
dfs(grid, i + 1, j, sb, 2); // 下
dfs(grid, i, j - 1, sb, 3); // 左
dfs(grid, i, j + 1, sb, 4); // 右
// 后序遍历位置:离开 (i, j)
sb.append(-dir).append(',');
BFS算法
BFS 相对 DFS 的最主要的区别是:BFS 找到的路径一定是最短的,但代价就是空间复杂度可能比 DFS 大很多
BFS 出现的常见场景就是让你在一幅「图」中找到从起点 start 到终点 target 的最近距离,变种就是替换字符,连连看游戏,走迷宫等
框架代码
// 计算从起点 start 到终点 target 的最近距离
int BFS(Node start, Node target) {
Queue<Node> q; // 核心数据结构
Set<Node> visited; // 避免走回头路
q.offer(start); // 将起点加入队列
visited.add(start);
int step = 0; // 记录扩散的步数
while (q not empty) {
int sz = q.size();
/* 将当前队列中的所有节点向四周扩散 */
for (int i = 0; i < sz; i++) {
Node cur = q.poll();
/* 划重点:这里判断是否到达终点 */
if (cur is target)
return step;
/* 将 cur 的相邻节点加入队列 */
for (Node x : cur.adj()) {
if (x not in visited) {
q.offer(x);
visited.add(x);
}
}
}
/* 划重点:更新步数在这里 */
step++;
}
}
visited 的主要作用是防止走回头路,大部分时候都是必须的,但是像一般的二叉树结构,没有子节点到父节点的指针,不会走回头路就不需要 visited
while 循环控制一层一层往下走,for 循环利用 sz 变量控制从左到右遍历每一层节点
二叉树的最小深度
这道简单的题只需要在模板上略加修改即可,但是通过这个我们能了解BFS和DFS之间的一点点的差别
1.为什么 BFS 可以找到最短距离,DFS 不行吗
BFS 的逻辑,depth 每增加一次,队列中的所有节点都向前迈一步,这保证了第一次到达终点的时候,走的步数是最少的
DFS 实际上是靠递归的堆栈记录走过的路径,你要找到最短路径,肯定得把二叉树中所有树杈都探索完
BFS 还是有代价的,虽然可以找到最短距离,但是空间复杂度高,而 DFS 的空间复杂度较低,一般来说在找最短路径的时候使用 BFS,其他时候还是 DFS 使用得多一些(主要是递归代码好写)。
打开转盘锁
我们使用广度优先算法时,我们可以枚举当前所有能够通过一次旋转到达的状态,如果他之前没有被搜索过我们将其加入队列当中。
为了避免达到死亡组合,我们可以将死亡组合的数字提前设置为已经搜索过,那么搜索到他们的时候就会直接返回
值得注意的是:如果初始数字“0000”在死亡组合和是目标的情况
双向BFS优化
传统的 BFS 框架就是从起点开始向四周扩散,遇到终点时停止;而双向 BFS 则是从起点和终点同时开始扩散,当两边有交集的时候停止。
不过,双向 BFS 也有局限,因为你必须知道终点在哪里。比如二叉树最小高度的问题,一开始不知道终点在哪里,也就无法使用双向 BFS;但是第二个密码锁的问题,是可以使用双向 BFS 算法来提高效率的
双向 BFS 还是遵循 BFS 算法框架的,只是不再使用队列,而是使用 HashSet 方便快速判断两个集合是否有交集
不过最坏时间复杂度都是O(n),最好还是掌握BFS框架