点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!


曹德福:
南加州大学(USC)Melady Lab 二年级博士生,研究方向包括因果推断和时间序列,已发表包含NeurIPS, ICLR, AAAI在内的国际顶会论文十余篇,AAAI 2023预讲论文一作学者。
研究背景
在连续时间观测情况下,当我们考虑到有存在我们没有观测到的confounders(混杂因素)的存在的条件下,我们怎么样去做这样的一个因果现象推断(Treatment effect)。

01
“什么是‘treatment effect’?
我们为什么要关注它?意义何在”
首先我们要明白何为“Treatment effect”:
因果推断主要是回答 "what-if "问题,以探索潜在的结果。在医疗保健环境中,这可以帮助医疗专业人士评估临床决定、治疗和干预的潜在后果。比如,如果癌症患者采取药物治疗而不是手术那他的生命体征会发生什么变化? 再比如,口罩禁令发布之后,COVID-19的疫情感染人数有所下降,我们会想理解如果没有口罩的禁令,新冠的感染患者的人数会如何变化?回答这些问题,需要我们理解“Treatment effect (治疗效应)”, 也就是说,我们不仅需要现在的机器学习模型能准确预测真实treatment施加后的结果(outcome),也需要模型具备理解反世界(counterfactual world)的能力。
02
Challenge ? Motivation! 挑战?动机!
首先,已有的观测数据往往存在未观测到的混杂因素 (同时对治疗和结果有影响), 比如,一个人的财富程度是会影响医生的决策的,但是医院的电子病历中是不会包含这种隐私信息的。因为混杂因素的存在,我们往往会得到有偏差(bias)的因果效应。之前的工作大多假设没有混杂因素存在从而得到无偏的因果效应。然而这种假设在现实世界中并不合理,因此,越来越多机器学习方面的工作开始尝试从观测数据中推断混杂因素。然而,这种不加约束的推断往往会带来较大的方差。考虑电子病历场景,电子病历中记录的条目是医生长期实践总结得到的对结果起决定性作用的观测变量。如果机器学习方法推断出的隐藏的混杂因素最终决定了预测的治疗结果,则将会产生较大的方差(variance)。因此,在考虑隐藏混杂因素存在的情况下,研究人员需要对偏差和方差之间进行权衡。
此外,治疗效应问题在连续时间观测的数据中十分棘手。连续时间观测的数据往往是不规则采样并且具有一定的稀疏性, 因果效应随着时间的变化也可能发生变化。比如说胃病患者吃完胃药之后,药品通过人体吸收在两个小时之后起作用,但如果医生观测的时间在用药后的第一个小时和第六个小时,那药效高峰期是被错过的,这样的连续观测可能会使得医生得到错误的结论。

图1 连续时间观测下因果关系图
03
治疗效果评估问题设定
如图1的causal structure model(SCM)所示,我们考虑连续时间序列到的数据,包括自变量(covariates X), 施加的治疗(Treatment A)和最后的结果(outcome Y)。此外我们假设存在为观测到的混杂因素(Confounders Z)。同时我们遵循之前因果推断的工作做出了相关假设。首先我们的问题设定满足consistent和positive假设, 保证个体的因果效应只跟自身相关,也就是说我们不考虑类似社交媒体或者社交网络中存在的个体之间相互影响的情况。

图2 对于未观测到的混杂因素的假设
此外,我们做了"sequential signal strong ignorability in continuous time setting"假设 (Assumption 3),假设我们观测的场景存在能同时影响多种治疗方案和结果的混杂因素。Assumption 4是对Assumption 3的补充,对于data-driven方法得到的混杂因素,我们假设这些混杂因素是可以被分解的,分解之后的成分包括高频成分和低频成分。高频成分可以被当成观测到的变量的一部分代理(proxy)而低频变量则被认为是在给定时间间隔内被约束的混杂因素,这个假设试图保证我们最后得到的混杂因素不会成为结果的主要因素。
04
Lipschitz Bounded Neural
Controlled Differential Equations
(LipCDE)
(Lipschitz 有界神经控制微分方程)
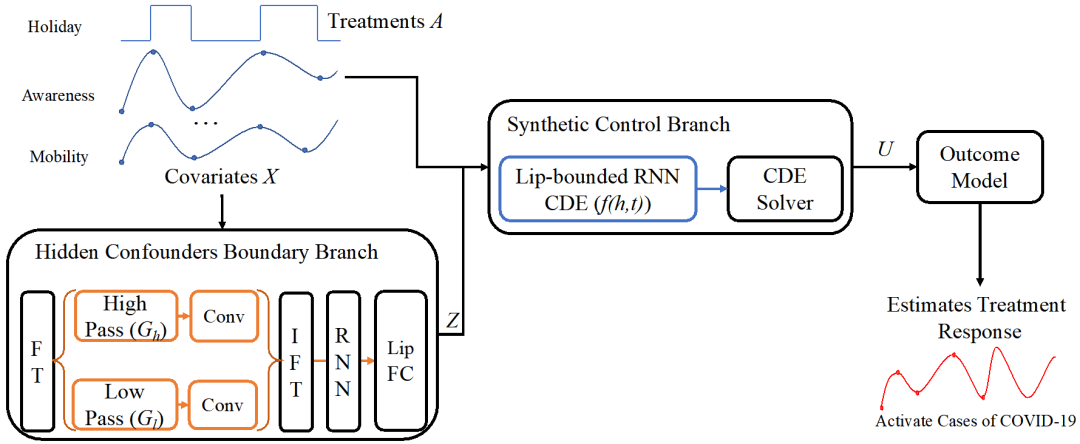
图3 LipCDE模型结构
为了解决来自不规则时间序列观察的治疗效果估计任务,我们必须避免由隐藏的混杂因素引起的推断偏差。因此,我们提出了一种叫做Lipschitz bounded neural controlled differential equations(LipCDE)的方法。如图3所示,LipCDE首先通过隐性混杂物的边界分支来推断隐性混杂物与治疗的相互关系, 这个分支使用Lipschitz约束保证学到的混杂因素在一定范围内。此后,LipCDE 将历史轨迹送入合成控制分支,该分支利用观察到的数据和隐藏的混杂因素来生成每个sample的潜在表征。此外,我们通过应用时间变化的反治疗概率加权(IPTW)策略,对所有参与的患者群体进行重新加权,并平衡表征。与LSTM层相结合,结果模型可以得到治疗效果的最终估计。具体的结构细节可以参考文章。
05
Experiment.
在本节中,我们通过对合成数据集和真实世界数据集(包括MIMIC-III数据集和COVID-19数据集)的一步超前预测来估计每个时间步骤的治疗效果。在这种真实世界的数据集中,隐藏的混杂物是作为不包括在记录中的变量存在的, 因此我们只评估事实的治疗效果。
5.1 合成数据集实验结果
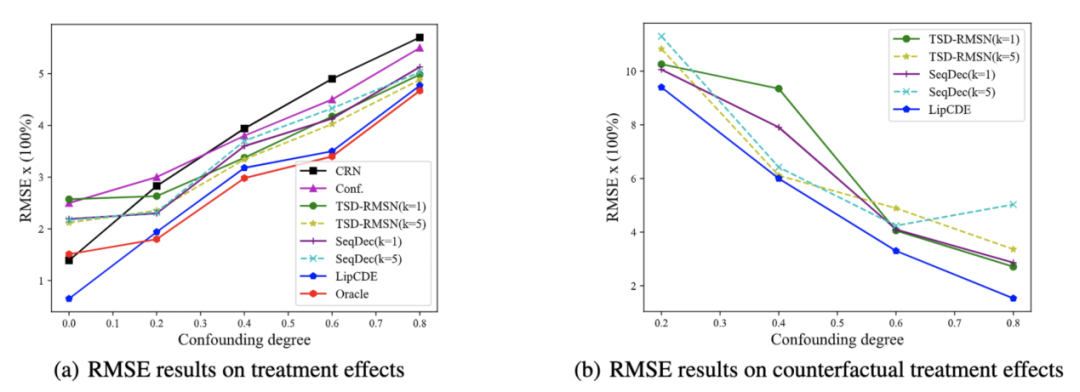
图4 合成数据集实验结果
对于合成数据集,我们能够控制隐藏混杂因素,并决定治疗方案。因此除了估计事实的治疗反应外,我们还将对治疗进行扰动,以量化LipCDE对反事实关系的准确把握程度。对于事实治疗效果的结果,考虑隐性混杂因素的方法(TSD, SeqDec, LipCDE)一般比没有隐性混杂因素的模型好(CRN, Conf.) 请注意,LipCDE在所有不同层次的混杂物上都取得了较好的结果,其结果最接近于使用模拟(Orcale)混杂物得到的估计值,这意味着LipCDE与其他基线相比可以产生较少的偏倚估计值。此外,当我们增加混杂因素的影响程度时,LipCDE保持稳定,并变得更接近模拟(Orcale)混杂因素基线,这表明我们的模型可以有效地约束基于观察数据的隐藏混杂因素的影响边界。对于反事实路径的结果,我们有趣地观察到,RMSE随着混杂物程度的增加而减少了。原因是当系统混杂程度增加时, 混杂因素要比自变量更容易处理(取决于合成数据生成方式)。此外,LipCDE在反事实世界中的表现仍然优于目前的基线,表明LipCDE对隐藏混杂物的推理的稳定性和估计的有效性。
5.2 真实世界数据集结果
真实世界的数据使我们能够证明LipCDE在真实世界的应用中具有强大的可扩展性和可解释性。其中,MIMIC-III数据集包了5000条病人记录,有3种治疗方法,20个病人的协变量和2个结果,包括血压(Blo. pre.)和氧饱和度(Oxy. sat.)。COVID-19数据集包含401个德国地区,时间段为2020年2月15日至7月8日。我们的实验结果显示,LipCDE在所有情况下都优于现有基线。通过对每个病人的分配治疗的依赖性进行建模,LipCDE能够推断出潜伏变量,并有序地利用潜伏变量和观察数据之间的因果关系。这一结果与我们在模拟数据集中看到的情况一致。此外,氧饱和度的小幅增加被认为是由于氧饱和度本身不依赖于当前的协变量,受治疗的影响较小。尽管这些在真实数据上的结果需要医生的进一步验证,但它们证明了该方法在真实医疗场景中的应用潜力。
06
总结
因果分析是时间序列分析中最基本的问题之一,在金融、零售、医疗、运输、制造等领域很容易找到许多应用。其中,估计时间序列数据的处理效果是许多行业和研究场景中的一项关键任务,由于存在隐藏的混杂因素和不规则样本或缺失观测值的动态因果关系,因此具有极大的挑战性。
在本文中,我们利用Lipschitz正则化和神经控制微分方程(CDE)的最新进展来解决上述挑战,从而为时间序列的现实应用提供有效和可扩展的因果分析解决方案。LipCDE可以通过考虑Lipschitz约束神经网络给出的隐藏混杂物的边界,直接建立历史数据和不规则样本的动态因果关系。
尽管目前包括LipCDE在内的模型离利用因果关系来弄清反事实世界和绝对正确地估计治疗效果还有很大的距离,但我们确实相信,这个差距正在迅速缩小。我们想强调的是,研究人员能够理解并减轻估计治疗效果的潜在风险。特别是在医疗卫生领域,不符合逻辑或不合理的治疗方法对个人或人类来说将是一场灾难。此外,我们建议研究人员采取以人为本的方法,建立具有公平性、可解释性、隐私性、安全性和问责制等特点的负责任的人工智能系统。
提
醒
点击“阅读原文”,跳转至 2:03:42 可以查看回放哦!
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1000多位海内外讲者,举办了逾500场活动,超500万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!