点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!


徐鹏程:
西安大略大学博士生
内容简介
当前的混合多目标领域自适应(BTDA)方法通常推断或考虑域标签信息,但未充分考虑多领域的类别特征结构,这会限制模型的性能,尤其是在标签分布变化的情况下。我们证明,如果各个域的类别分布充分对齐,模型也能达到较好的性能,即使面临域的不平衡和类别的标签分布变化,域标签对于BTDA来说并不是直接必需的。然而,我们观察到BTDA中的聚类假设并不完全成立。多领域的类别特征结构阻碍了类别分布的建模和对齐,以及可靠伪标签的生成。为了解决这些问题,我们提出了一个由不确定性引导的多分类域鉴别器,以显式建模并直接对齐类别分布P(Z|Y)。同时,我们利用低级特征来增强具有不同目标样式的单一源特征,以纠正不同目标域之间的偏差分类器P(Y|Z)。P(Z|Y)和P(Y|Z)的这种相互条件对齐形成了相互强化的机制。即使与使用域标签的方法相比,我们的方法也优于BTDA中的最新技术,尤其是在标签分布偏移下,以及在DomainNet上的单域目标DA中。
Definition and Background
这篇文章主要讲的是在混合域上的领域自适应问题,一般的领域自适应研究都是从单一的源域到单一的目标域,而我们所关注的是从一个源域到多个目标域的适应问题,我们希望模型经过领域自适应之后在每一个目标域上都可以表现得非常好。我们在每一个目标域都算一个准确率,最后的评价指标是所有准确率的平均值。这样的话就需要模型,不管目标域的目标是小还是比较大,都要求它的性能比较好。比如说如果一个目标域的数据集很少,它的性能也是要求比较好的。这样就可以避免一些问题:比如假设某些目标的数量比较大,此时就可以抛弃小的目标域了,只需重点关注大的目标域的数据集表现性能。所以只关注整体的准确率,其实是不太足够来体现这个问题的重要性的,我们希望每一个目标域的性能都非常好。
Motivation
首先我们剖析一下之前的领域自适应在BTDA方式上存在的问题,并且阐述我们所做出的贡献。
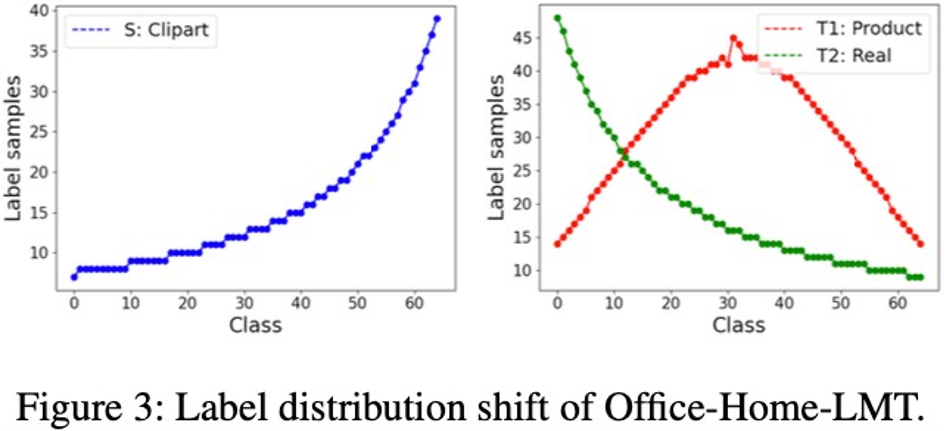
第一个问题就是之前的BTDA,即混合域的领域自适应,这些目标域的图片是混合在一起的,他们都是需要去推断并且考虑一些域标签,把每一个目标域的标签推断出来,然后再去取每一个目标域的图像和源域进行一一对应。我们在这篇文章中所做的贡献就是,第一个,我们不需要知道域标签的信息;第二个是之前的研究中没有考虑到的点,就是在做实验的过程中,我们发现在混合目标域当中每一个类别的特征空间非常复杂;第三点就是之前的领域自适应问题其实并没有考虑到标签分布迁移的信息。比如说下图所示的例子,蓝色代表的源域是Clipart,T1代表的Product域,T2代表Real域。此时会出现一个问题:假设说源域的类别标签的分布是一个长尾分布,且0这个类的图片对应的数量是非常少的,60对应类别的图片非常多。每一个目标域上标签的分布可以是都不同的,比如说绿色曲线是Real image的域,它也是个长尾分布,但是长尾分布所展现出来的分布特性是和源域中所展现的分布特性是完全相反的:0这个类在Real image域中是最多的一个类,60这个类是最少的。在Product域中,数量最多的类别在30这个类。之前的研究其实并没有考虑到每一个源域和每一个目标域之间类别标签的分布差异对性能的影响,这个在实际当中影响还是非常大的,而我们第一次将这个问题考虑到研究工作中。
Preliminary Results
在多个域中会发现一个现象:同类但不同域的特征分布非常复杂,并不形成很规则的聚类。在下面这张图上我们标记了所有的类别的信息以及对应域的信息,数字代表这个图片的类别,颜色代表了图片所属的域,可以发现从中随意挑选一个类别,如果聚类比较好的话,是比较容易分类的,但是从我们抽出来的特征可以看到,来自同一类别但不同域的图片,他们的分布不形成良好的聚类,而是一种非常不规则的和其他类别的聚类有混叠的一个状态。这样的话其实很难用一个比较好的分类器去分类,如果想要做一个分类器把类别2和类别12分开的话,其实有一部分数据根本无法分开,因为他们的特征是混叠的。我们期望来自同一个类别但是不同域图片都能够有一个比较好的聚类,他们都是完全分开的。

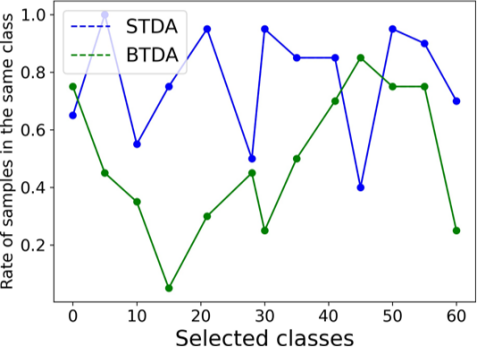
在下面的图片,我们也对这个图片做了一些更细致的分析,来佐证我们前面所阐述的那个现象。我们对每个类别都算了一个类中心,然后对每个类中心都计算了一下它的K-nearest neighbors,我们发现和传统的STDA(单个域的域适应)相比的话, BTDA的混叠现象非常严重。图中所标记的rate of samples in the same class意思是:对于每一个类中心都去寻找K-nearest neighbors,然后看这些K-nearest neighbors是否和这个类中心所代表的类别都属于同一个类。实验当中,对于不同类别我们都测了一下rate of samples in the same class,然后我们对比了传统的STDA和BTDA这两种状态的rate of samples in the same class,发现这个问题在BTDA当中是更加严重的。
前者是从实验现象上分析,后面我们将从理论上进行分析。这些现象主要来自两方面的分布差异,一部分来自类别分布差异,还有一部分来自分类器。下图较为形象地展现了前面所说的问题,可以看到有来自同一类别但是不同域的分布是混叠的。

Contributions
我们对这个问题的解决方案和贡献,主要来自两方面。第一个就是从理论方向,我们贡献了两个直觉信息:第一个是域标签在BTDA中并不需要。之前的研究中必须要关注一些域标签,但是我们从理论上说明了域标签不是必要的;第二点是我们做这件事的方法,我们发现只要把类别分布差异足够地对齐,这个模型就可以达到一个比较好的性能,即便是每一个目标域和源域的标签分布差异都有一些不同的情况下,我们只要能保证类别分布差异能够足够的减弱并对齐,那就可能保证一个比较好的性能,这是理论上的第二个贡献。基于这个理论我们设计了框架——Mutual Conditional Framework,我们想做的事情是同时去对齐这两个分布,一个就是P(Y|Z),还有一个是P(Z|Y),这里的y指的是类别标签,Z指的是对图片提取完特征之后的特征空间,P(Y|Z)是每一个特征所对应的类别,P(Z|Y)所表示的是每一个类别的类别分布。
Theoretical Insights

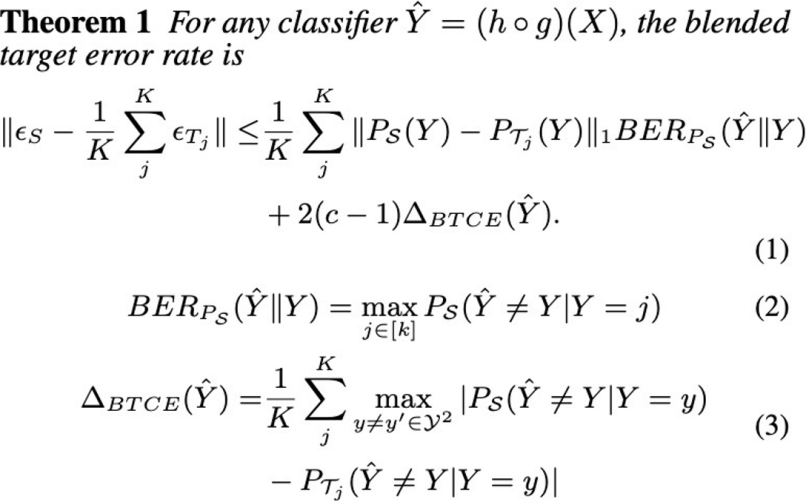
Model Design
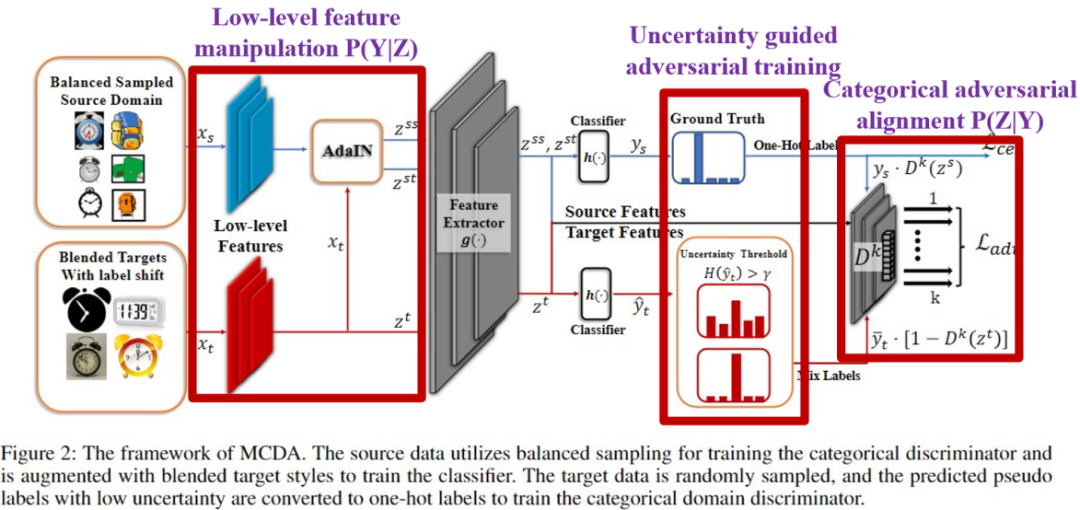
根据之前的理论所设计的框架主要包括两部分,一个部分是用来对齐我们的类别分布,另外一个部分用来对齐我们的分类器。
第一部分,之前的域判别器中的输出只有一个,只区别0或1,即给定一个数据,用判别器来辨别数据是属于源域或是目标域。我们把这个判别器的输出扩展成k,k代表类别的个数。这样的话我们训练每一个判别器 logit,使得这每一个logit都可以代表一个类别的分布,就相当于附加了一个条件。但是实验当中在训练模型的时候,是需要有一些监督信息的。对于源域,具体的做法是把源域的类别标签变成一个one hot encoding,假设这张图片来自猫,那么我们就有k个类别,就只激活对应猫的那个logit,其他logit都是全部乘上0,只有对应猫类别的logit变成1,这样的话其他的logit都是deactivate只有猫对应的logit是activate。但是会存在一个问题,目标域上是没有真实标签的,我们对这个问题提出一个解决方案:我们设计了一个根据不确定性来逐渐把目标域的标签,从软标签给变成one hot encoding这样一个形式。具体来说,就是从soft max classifier出来之后是一个概率,但是概率的概率有高有低,真实性并不可靠。所以我们会先算一个不确定性,如果不确定性比较小就可以信任这个类别标签,将它变成一个one hot encoding形式,再去激活对应的logit。我们实验发现在训练的过程当中这个判别器会从一个不能够分辨类别逐渐变得可以分辨类别,它每一个logit都可以代表一个类别分布,即P(Z|Y)。这样处理的话将可以将之前的只能分辨源域或目标域的判别器变成了一个带有类别信息的判别器,它可以去对齐类别 分布,而不是像之前的判别器只能对齐P(Z)。之前的做法其实都是在对齐边际分布,但我们的做法就是可以对齐类别分布。
第二部分,在对齐类别分布的过程中,我们同时希望提高类别标签的准确率,这就取决于分类器。这两个部分其实是相互的,P(Y|Z)效果好的话会进一步激发P(Z|Y)的性能,进而提高分类器的准确性。关于这一部分的设计,我们也有一些考虑。我们第一点考虑的事情是用一些底层特征去做数据增强,因为我们只有一个源域。源域中有监督信息,我们可以去知道他的很多信息。但是在这个过程中我们没有任何监督信息,高层语义信息在没有类别标签监督情况下,我们发现这些特征的信息都是很脏的,根本无法代表一些图片的语义信息。所以我们就想到一个方法,利用一些CNN的先验知识去抽取一些图片本身的信息.因为CNN的最开始几层的信息是可以代表一些图片的纹理、结构及其他信息的,它不需要特别强的监督信息。如果像高层的CNN的信息的话,可能是必须需要类别标签去监督这个图片的训练过程,才能带有语义信息。如果没有标签的话,语义信息基本上都是错误的,没有任何意义。所以我们只用了底层的特征,可以在无监督的情况下对多个目标域做数据增强。我们利用CNN最前几层的先验知识去抽取每一个目标域的纹理和风格信息,去跟源域进行混合,此时就相当于具备了源域语义信息和目标域风格的信息,此时再进行模型训练就提升了判别器的辨别能力,可以让他在不同的目标域中都有一些性能的提升,更好地去区分每一个目标域中的数据。这样的话Y其实就变得更加准确,每个类别的准确率可能会提升一些,就可以促进判别器的性能提升,进一步又可以促进判别器,这是一个相互促进的过程。我们的设计的初衷就是做一个mutual conditional alignment的框架,让这两个模块相互促进,这也是我们整篇论文的思想。
Experiments
1
Experiments on BTDA
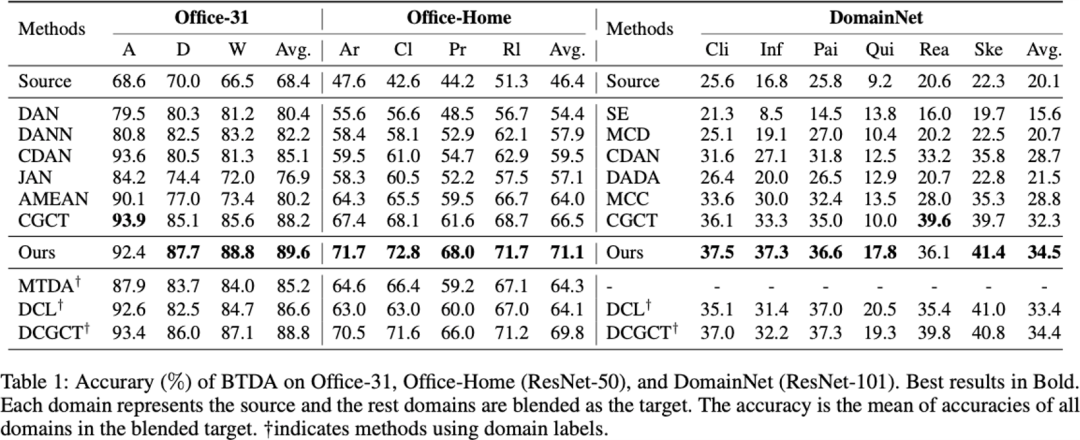
我们通过三个数据集Office-31、Office-Home和完整的DomainNet在BTDA上进行实验,我们的性能都达到了SOTA。图中的最后一行我们也跟之前的SOTA方法进行了对比,之前的SOTA中用了域标签信息,我们想证明我们不需要域标签信息也可以超过 SOTA,表格中的数据与我们的性能相比还是有所差距。这就佐证了我们理论上的贡献:域标签在这个问题当中其实并不是必要的,不使用域标签信息仍然可以达到比较好的性能。
2
Experiments on BTDA with Label Shift
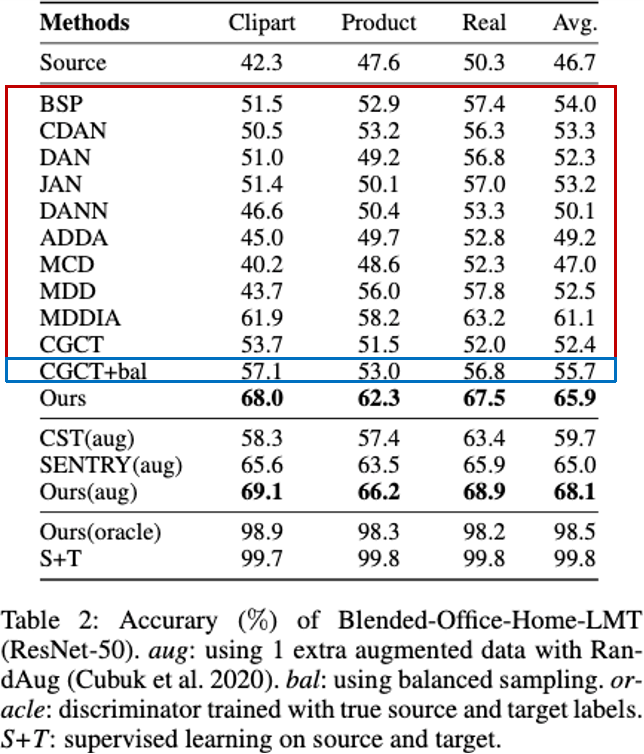
在本文中,我们是第一个去讨论在混合目标域下标签分布差异问题的。我们在Office-Home上做了这样一个数据集叫Office-Home-LMT,有标签分布差异下的多个域的预迁移信息。在源域中给出一个长尾标签分布,目标域中给两个完全不同的标签分布差异,我们希望经过我的域标签之后,在有标签分布差异的情况下,在每一个目标域上都可以得到比较好的性能,下图是具体的性能信息。因为标签分布差异在域适应上也有一些工作,我们跟之前的标签分布差异域适应的SOTA进行了比较。主要有两部分,第一部分:红色框内是跟之前的一些有标签分布差异的域适应的方法的比较,蓝色框内,我们把之前的多域域适应的SOTA和考虑标签分布差异的域适应方法做了一个组合,这个数据是之前BTDA的SOTA加上一个平衡采样,我们将这两个方法合作为一个强的基础比较模型,发现我们的方法仍然比较强的。第二部分是与一些采用数据增强的方法的比较,我们的效果仍比它们要好一些。为了公平起见,我们的数据增强都是只扩展一张图片,在这个有数据增强的方法中,我们的方法也比前人的方法要好。最后一点我们想测试我们所提方法的最好性能,于是跟监督学习的方法去进行了比较,监督学习的方法的性能得到的数据是99.8%,我们方法的性能是98.5%,这与监督学习的方法是很接近的。
Ablations
下面是我们所做的消融实验。我们对于Office-Home和DomainNet都做了消融实验,每一个模块都有比较高的提升。

我们也对这个最好的模型做了一下可视化,发现经过训练之后,从人类视觉的角度,我们的模型也可以更关注到一些比较有区分性区域的一些信息。

这张图片是t-SNE的可视化,所达到的效果也是印证了我们最初的期望:来自同一类别但不同域的特征都聚合在一起。

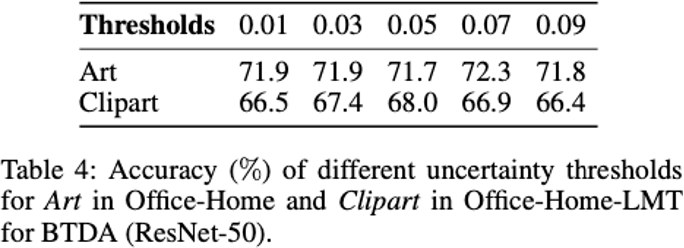
最后我们验证了不确定性机制的稳定性和有效性,在大范围内我们的这个不确定性机制都是比较有效的,模型的性能比较稳定。
Summary
最后再次总结我们这篇文章中做出的主要贡献:(1)域标签并不是很重要,类别信息是最重要的;(2)在目前的研究中,我们是第一个去讨论在混合域下标签分布差异问题的;(3)最后我们在DomainNet上对于BTDA和STDA都实现了SOTA。
提
醒
点击“阅读原文”,即可查看回放
活动推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了900多位海内外讲者,举办了逾500场活动,超500万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放