论文:https://arxiv.org/pdf/1711.07274.pdf
题目:Speech recognition for medical conversations
摘要
在本文中,我们记录了我们在开发用于医学转录的语音识别方面的经验-一种自动转录医患对话的系统。为了实现这一目标,我们沿着两种不同的方法论体系构建了一个系统-基于连接主义时间分类(CTC)音素的模型和基于听众和咒语(LAS)字素的模型。为了训练这些模型,我们使用了匿名对话的语料库,它们代表了大约14,000个小时的讲话时间。由于语料中的抄本和对齐方式比较嘈杂,因此在数据清理问题上投入了大量精力。我们描述了一种用于分段数据的两阶段策略。匹配语言模型的数据清理和开发对于基于CTC的模型的成功至关重要。但是,发现基于LAS的模型可以抵抗比对和笔录噪声,并且不需要使用语言模型。 CTC模型能够实现20.1%的单词错误率,而LAS模型能够达到18.3%。我们的分析表明,两种模型在重要的医学话语上均表现良好,因此对于转录医学对话非常实用。
1.介绍
20世纪初期,速记员开始在医学领域进行转录。 随着1990年代中期左右ASR和NLP技术的普及,医疗保健系统开始采用单扬声器ASR技术来协助医生听写。 最近,随着电子健康记录(EHR)系统的广泛采用,医生现在在EHR内的11个小时的工作时间中大约花费6个小时,而在文档上花费大约1.5个小时。 随着初级保健医生的日益短缺[1]和更高的倦怠率[2],可以加速临床访视转录的ASR技术似乎迫在眉睫。 它是一项基础技术,可以在此基础上构建信息提取和摘要技术以帮助减轻文档负担。
患者(甚至可能是护理人员)与提供者之间的医疗对话与正常命令具有几个不同的特征:(1)涉及多个说话者(医生,患者以及偶尔的护理人员),对话重叠且距麦克风的距离不同且质量不同,( 2)它涵盖了从口语到复杂的领域特定语言的一系列语音模式,重音,背景噪音和词汇。 ASR必须处理长格式的内容(从10到45分钟长),该内容将临床上的重要信息与随意的聊天声交织在一起。由于缺乏用于构建系统的大量干净的,经过整理的数据,因此开发用于医疗对话的ASR系统变得更加复杂。记录实际对话而收集的数据会产生非常嘈杂的数据,这是由于真实对话中出现的所有问题-干扰,同步语音,信噪比低等。处理这些因素需要大量的数据预处理工作,否则就很难训练传统的语音识别系统。此外,对话中的某些部分比其他部分更重要–医生和患者之间的随意对话不如描述潜在症状,治疗等的对话重要。
最近,已经使用相对较小的医学语音数据(270小时)为医学领域构建了基于神经网络的语音识别系统,并已针对医学转录专家进行了基准测试[3]。 语音识别系统已经在临床问题回答任务上进行了评估,并且已经显示,使用语言模型进行域自适应可以显着提高口译临床问题的准确性[4]。 使用众包输入数据进行语言模型自适应已显示出可提高医疗语音识别系统的准确性[5]。 已将使用语音识别辅助临床文档的效率和安全性与使用键盘和鼠标进行了比较,发现次优的语音识别准确性可能会造成临床危害[6]。
端到端语音模型的最新发展提供了有希望的替代方案。 听力和拼写(LAS)模型[7]是一种端到端模型,能够学习作为ASR模型本身一部分的语言模型。 在本文中,我们比较了我们使用LAS和使用CTC [8]初始化的基于HMM的传统模型构建语音识别系统的经验。 我们发现LAS模型对于嘈杂的成绩单非常强大,并且不需要语言模型。 另一方面,基于音素的CTC模型仅在进行大量数据清理工作并且为该领域开发了匹配的语言模型时才能很好地工作。 我们的CTC模型的WER为20.1%,而LAS模型的WER为18.3%。
我们评估了两个模型在捕获重要医学短语时的性能。 我们选择了一部分对话,要求一组专业的医疗抄写员对对话中的重要短语进行注释,这些短语对于撰写医学笔记非常有用。 在所有重要的短语上,CTC模型的双向模型的准确率达到92%,召回率达到86%,单向模型的精确度达到88%,召回率达到84%。 我们分析了LAS模型在识别对话中提到的用于治疗的药物名称方面的有效性,该模型的召回率达到98.2%。
2.系统概述
我们探索了用于建立此任务的语音识别模型的两种机制:一种使用带有连接器时间分类(CTC)的递归神经网络,另一种使用带有注意力的端到端模型(LAS)。
2.1 CTC
CTC系统由经过CTC损失训练的声学模型,与上下文相关的音素输出,n元语法模型和发音词典组成。 使用基于有限状态换能器(FST)的解码器进行解码。 我们为此任务训练了单向(用于流识别)和双向CTC模型。
2.2 LAS
注意的端到端模型由编码器,注意机制和解码器组成[7]。 编码器将语音作为输入,生成一系列隐藏状态,然后解码器使用注意力机制在每个预测步骤关注编码器输出,然后顺序生成字素输出。 在此框架中,编码器扮演声学模型的角色,该模型处理语音发声并将其转换为高级表示,然后解码器处理该输出序列以生成转录本。 解码器使用注意力结果和上一步的预测来决定当前步骤的注意力。
3. 任务定义和数据处理
此任务中使用的已取消标识的数据是从大型对话研究组织获得的。 在患者的同意下,通过将录音设备放在诊所中来收集对话的音频。 然后将录制的音频压缩为MP3,然后发送给人类注释者进行转录。 最后的成绩单包含演讲者的发言和演讲者的代码(医生,患者,护理人员等)。 在转录过程中,通过将相应的音频清零并在转录本中使用特殊标签来取消识别个人数据。 还提供了大概的扬声器转向时间戳。 我们发现这些时间戳通常相差几秒钟。 对于每个对话,我们还收到元数据,其中包括交互类型,医生的性别以及医生的唯一标识符。
3.1 分割
为了使培训和测试变得易于处理,我们将对话分为演讲者转向部分。 我们发现训练数据中说话者转弯边界的准确性在使用这些细分进行训练的模型的性能中起着重要作用。 我们尝试了以下方法来获得更好的扬声器转向段。
3.1.1 缓冲转向对齐
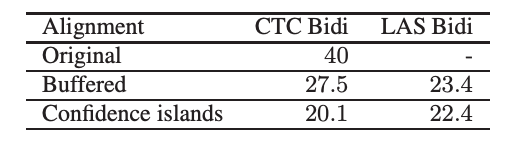
用原始段训练双向模型可以得到40%的WER。 为了解决这些扬声器转弯对齐问题,我们在每个转弯片段的开始和结尾处添加了1秒的音频缓冲区,并使用转弯笔录重新对齐了缓冲的音频。 最后,我们仅通过保持与转弯笔录对齐的音频来创建新的扬声器转弯段。 我们删除了声学模型得分最差(按时间范围标准化)的10%的尾段。 在这些细分市场上进行培训和评估后,双向CTC模型得出的WER为27.5%。
3.1.2 两遍对齐
为了获得更好的对齐数据以进行培训和测试,我们使用两遍强制对齐方法将整个会话音频与会话记录强制对齐。
第一遍:置信区间 。 我们使用[9]中描述的置信区间方法将对话与成绩单对齐。 我们使用如下构造的约束FST语法G识别音频。
1.构造一个线性FST,其中每个圆弧代表笔录中的一个单词。
2.允许start从FST中的开始状态过渡到所有状态。
3. FST中的所有状态均为最终状态。
该G仅允许路径是地面真相成绩单中单词的连续序列。 音频被分割为10秒的块,并使用域外语音邮件声学模型和上面构造的语法G进行识别。 连接识别结果,并将得到的完整识别文本与实际的人类成绩单对齐。 识别结果中与实际人类成绩单相匹配的连续部分(至少5个字)(称为置信区间)被假定为具有可信赖的字时间戳。 对于每10秒的片段识别,我们明确地从任何置信区间中排除了第一个和最后一个单词,因为它们可能已在固定的10秒边界处被部分切割。 在第二次强制对齐中固定了没有落入任何置信度中的单词的时间戳。 仅通过这种力对准,我们就能够对准≈80%的单词。
第二遍:修正剩余的单词。 对于地面真相记录的第一遍中未对齐的连续单词的任何序列,我们通过使用在地面真相中该序列之前和之后的置信区间的时间戳来计算相应的音频片段。 由于我们大多数单词在第一次通过时就已经对齐,因此这些音频片段并不大,我们能够针对未对齐单词的序列对片段音频进行完全约束的强制对齐。 使用这种第二遍方法,我们可以获得大约98%的单词的时间戳。 其余单词的时间是从经过强制对齐的相邻单词中插入的。 一旦我们获得了完整音频的字级对齐,就将其分割为单个扬声器匝。 我们发现,通过这种方法获得的转弯水平对准对于训练声学模型而言足够准确,并且不需要任何进一步的缓冲音频方法(如3.1.1节中所述)。
3.2 训练和测试分割
数据集包括临床访问期间医生与患者之间大约90,000个单通道转录对话。 数据总量约为14,000小时。 对话代表了用于不同目的的151种医疗访问,例如健康访问,II型糖尿病,类风湿性关节炎等。每次对话通常在单个医生和患者之间进行,有时还包括护士或家庭成员。 平均而言,对话时间为10分钟,其中一些特殊的对话时间长达2小时。
我们为测试集抽样了100个对话,以确保每个对话都有一名不同的医生,并且男女医生的比例相等。 包含这100名医生的所有其他对话都被排除在外,剩下的76,000条对话是在培训中没有医生与测试集重叠的。 测试对话中有64个代表8个目标疾病区域。 诸如皮肤病学之类的疾病领域包括相互作用类型,诸如湿疹,黑色素瘤和痤疮。 从非目标疾病地区抽取了36个对话。
对于培训和测试,我们使用从3.1.2节中解释的两次通过强制对准获得的扬声器转向段。 作为一般的预处理,我们从测试和训练集中删除了任何在成绩单中包含去识别标记的说话者转弯片段。 手动检查表明,大多数与细分有关的问题都是非常小的话语。 为了减少此类错误,我们从测试集中删除了所有小于5个字的扬声器转向。 对于训练数据,我们删除了单个单词转弯。
4. 模型训练
为了同时训练注意力模型和基于CTC音素的模型,使用的功能是快速傅立叶变换(FFT),具有在25 ms音频帧上计算的80个滤波器组通道,步幅为10 ms。 作为模型输入,我们堆叠了3个这样的帧,并跨度为3,即每30毫秒输入240个滤波器组。 为了计算FFT,我们忽略了3800Hz以上的频率。
为了使模型对噪声更鲁棒,并防止过度训练,我们在训练时向音频添加了人工噪声,称为多样式跟踪(MTR)[10]。 在我们的设置中,每种训练发声都与20种不同的噪声(房间混响,背景音乐,咖啡馆噪声)结合在一起,SNR范围为5dB至25dB。 我们发现,当使用CTC /交叉熵(CE)训练标准添加噪声并在进行EMBR训练时使用原始音频时,可以获得最佳结果[11]。
4.1 CTC
为此,我们训练了带有上下文相关(CD)音素输出的CTC模型。该模型体系结构是LSTM层的堆栈,可提供softmax输出,预测8K CD电话单元加1个CTC空白符号。如[12]中所述,CD电话是根据来自域外语音邮件模型的初始训练数据从训练数据中计算出来的。一旦我们在此CD手机上训练了具有CE丢失的域内模型,我们便将训练数据与CE模型重新对齐,并计算出用于训练CTC模型的新CD手机。我们为此任务训练了双向和单向模型。由于这是会话数据,因此片段通常不会以足够的静默结束,无法给模型时间输出所有帧的音素。我们发现,要获得良好的单向模型,我们必须训练具有输出延迟的模型,其中我们忽略了前T个帧的模型输出,然后重复了最后一个输入帧T次。
在解码过程中,我们使用了经过医学和语音搜索/听写数据混合训练的5-gram语言模型,并使用贝叶斯插值[13]组合了来自不同域的数据。对于发音,我们使用监督发音词典(占发音的77%)和音素-音素(G2P)模型(占发音的23%)。
4.2 LAS
我们的序列到序列注意模型由编码器,注意机制和解码器组成。 编码器体系结构是堆叠的双向LSTM。 双向LSTM结合了前向和后向信息,从而使输出隐藏状态可以访问整个话语,并且在局部话语帧达到峰值。 可以访问整个语音帮助编码器作为声学模型将语音信号与环境噪声区分开。 另一个好处是使注意力机制更易于学习。 由于每个输出隐藏状态主要包含局部话语信息,并且可以访问整个话语以区分噪声,因此关注机制可以学习将注意力主要集中在与当前预测目标相对应的帧上。
我们的模型使用多头注意力[14],将传统的注意力机制扩展为具有多个头,其中每个头可以生成不同的注意力分布。 我们使用调度采样[15]来训练解码器。 最初,我们将地面真实性作为先前的预测,随着训练的进行,我们将模型预测的采样概率线性提高到30%,然后以该采样率保持直到结束。 解码器执行字素预测。
表1:不同数据对齐方式的WER。 这里的LAS模型是基本版本,没有我们为最终模型应用的技术。
5. 结果和分析
我们使用第3.2节中定义的基于说话者回合的训练数据训练了LAS注意模型和基于CTC音素的模型。 我们从训练数据中随机抽取了约0.5%的语音,并以此作为我们的开发集。 CTC和注意力模型共享相同的训练/测试/开发数据。
5.1 ctc 结果
我们训练了单向和双向CTC模型。 对于单向模型,我们增加了10步的输出延迟。 该模型具有5个LSTM层,每层700个单位,并且在进行CTC培训后达到了28.8%的WER,通过EMBR培训提高到23.5%。 训练具有5个双向LSTM层和每层700个单位(任一方向350个单位)的模型,可以得到25.2%的WER,经过EMBR训练后,WER可以提高到20.1%。 表2显示了测试集不同子集上CTC模型的WER编号。
5.2 LAS结果
当不使用MTR进行训练时,我们尝试在编码器中的LSTM层之前添加卷积层。 所得模型的WER为22.4%。 添加计划的采样将其降低到21.6%。 在添加MTR时,卷积层没有帮助,而且往往会提供较差的质量,因此我们从编码器中删除了卷积层。 如果使用MTR而没有卷积层,则WER达到18.9%。 增加多头关注将导致18.3%的WER。 我们还尝试了EMBR培训,但并没有进一步提高WER。 编码器具有6层双向LSTM,每个方向具有768个单位,而解码器具有3层单向LSTM,具有768个单位。
表2:分析CTC结果

5.3 CTC和LAS的比较
在对CTC模型进行EMBR训练之前,注意模型和可比较大小的CTC模型提供了非常相似的WER。 更大的注意力模型胜过CTC模型。 尽管CTC和注意力模型在小说话时都表现不佳,但是注意力模型的表现要好于CTC。 我们发现在很小的声音(例如“是”)下,即使音频令人难以理解,注意力模型在大多数情况下仍能正确输出。 当语音在语音开始或结束时突然被截断时,注意力模型的性能也会更好。 通常,注意力模型对数据处理更具弹性。
5.4 误差分析
孤立的话语通常是完全无法理解的,抄写员可能会使用上下文来理解它们。 不论是否能听见,转录员都会填写很多简短的单词,例如 “有血液工作”被转录为“我有血液工作”。 人声品质使语言难以理解,例如 口音,笑声,耳语等。患者的语音通常更柔和,更远,主要是由于录音设置)。 音频也被压缩为MP3,这可能会导致质量下降。
5.4.1 CTC
大多数错误似乎都出现在发话的开头和结尾,例如:“这就是您需要的一切”变成“那就是您需要的一切”。 有趣的是,当说话者彼此交谈时,CTC模型会删除该音频区域中的单词。 错误的主要部分是由较小的扬声器转弯段(<1秒长)造成的,因为较长的发声模型错过了语音的会话部分,例如:“呃我”被转录为“嗯我的意思”。 通常,患者说话者转弯处的WER要比医生差,这可能是因为记录设备放置在离医生更近的地方,因此医生的言语比患者清晰得多。 表2显示了针对说话人,性别和疾病领域的详细分析。
为了查看该模型在重要医学短语上的性能,我们从这些谈话的地面真实成绩单中收集了医学短语的受监管列表,并对我们在音频片段中正确识别这些短语的频率进行了评估。 为了收集这些短语,请一组医疗抄写员在对话中标记对写医学笔记有用的重要短语(例如:症状,实验室检查结果,患者指导等)。 结果表明,基于CTC模型的识别在识别重要医学短语时,双向模型的准确率达到92%,召回率达到86%,单向模型的准确度达到88%,召回率达到84%。 还值得注意的是,医生经常会重复某些信息,特别是患者说明,以确保患者理解并进一步减少错误。
5.4.2 LAS
扫描成绩单错误时,大多数错误是对话性的,与医学术语无关。 在与医学术语相关的错误中,与缺乏医学术语相比,通常与声学建模更多相关。 例如,将“不要付一分钱”改写为“不要用一分钱便士”,其中模型用医学术语代替了常用词。 LAS不使用外部语言模型,并且确实有较少的休闲对话内容可供学习。
我们分析了LAS模型在识别对话中提到的用于治疗的药物名称方面的有效性,该模型的召回率达到98.2%。
6. 结论
在这项工作中,我们探索了自动语音识别模型的建立,用于转录医生与患者之间的对话。 我们收集了大规模的临床对话数据集(14、000 hr),设计了代表真实单词场景的任务,并探索了几种对齐方式来迭代地提高数据质量。 我们探索了用于构建语音识别模型的CTC和LAS系统。 LAS对嘈杂的数据更具弹性,而CTC需要清理更多的数据。 提供了详细的分析以了解临床任务的性能。 我们的分析表明,语音识别模型在重要的医学言语上表现良好,而因果对话中却出现了错误。 总的来说,我们相信最终的模型可以在实践中提供合理的质量。