YOLO X
主要改进:
- Anchor-Free: FCOS
- Decoupled detection head
- Advanced label assigning strategy
Network structure improvement
Decoupled detection head
对比于YOLO V5, YOLO X 在detection head上有了改进。YOLO V5中,检测头是通过卷积同时预测分类以及定位任务,即通过同一个卷积来处理。
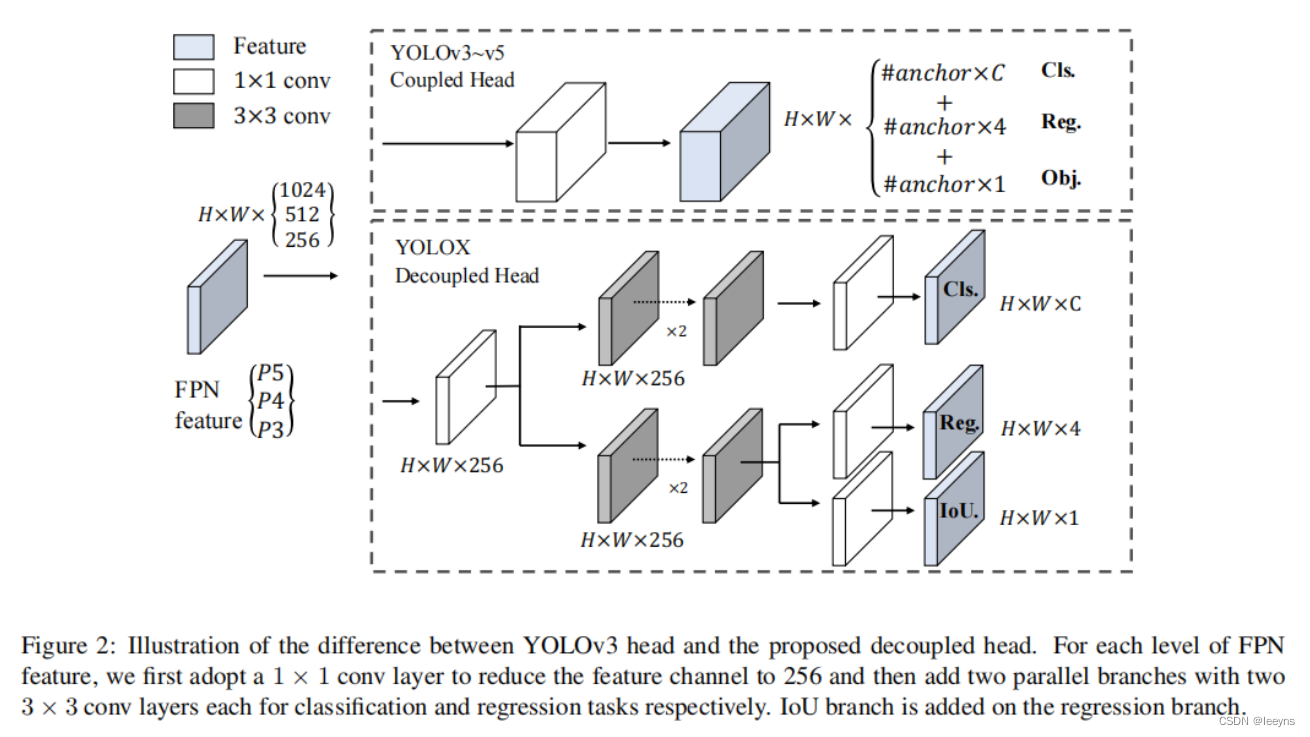
YOLO X 则使用了解耦的检测头,即,分类,定位,置信度预测由不同的卷积层来处理。同时,YOLO X 是anchor free的检测器,因此对于定位的输出仅仅只有4个参数,这个区别于YOLO V5 anchor-based 检测,每个cell 是基于3个anchor进行定位预测。YOLO X的三个检测头的权重不共享。文中实验表明,采用解耦的检测头,网络更容易收敛且准确率有了一定的提高。
Anchor-free
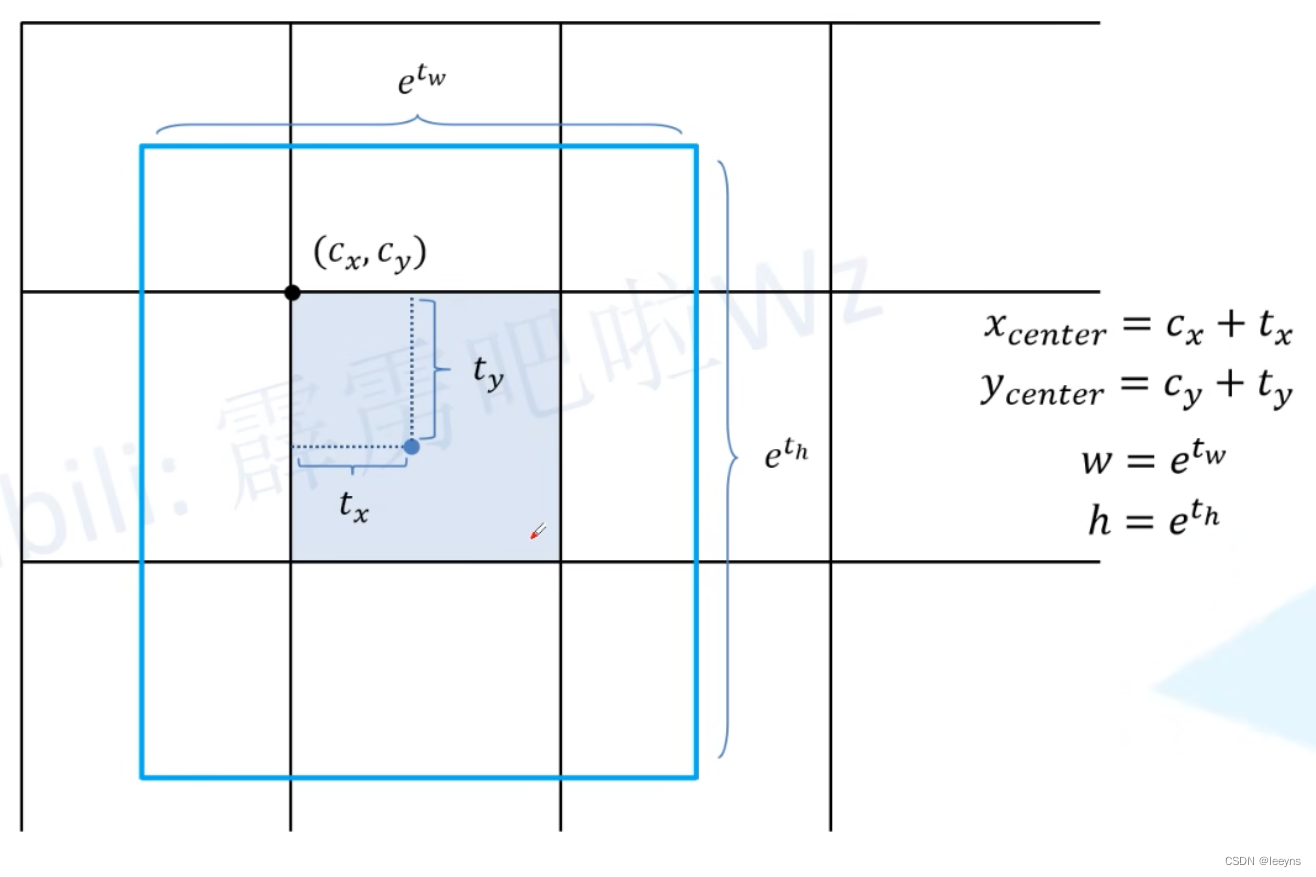
对于定位模型预测4个数 ( t x , t y , t w , t h ) (t_x, t_y, t_w, t_h) (tx,ty,tw,th). 因为是anchor-free,所以对于预测框的高度和宽度区别于YOLO V5基于anchor的缩放,在YOLO X中则是直接输出预测框的高和宽。
Loss Function
Loss function 包括三个部分,Class loss function, Region loss function, IoU loss function (置信度). 其中 class loss function 和 region class function 只计算正样本的损失。
L O S S = L c l s + λ L r e g + L o b j N p o s LOSS = \frac{L_{cls} + \lambda L_{reg} + L_{obj}}{N_{pos}} LOSS=NposLcls+λLreg+Lobj
其中 N p o s N_{pos} Npos表示这个feature map中被分为正样本的个数。 λ \lambda λ 是平衡系数,代码中给出的是5.0.
正负样本匹配 (SimOTA)
SimOTA 将匹配正负样本的过程看作最优传输的过程。通过cost function来筛选正样本。预测样本和GT之间的cost计算如下:
C i j = L i j c l s + λ L i j r e g C_{ij} = L^{cls}_{ij} + \lambda L^{reg}_{ij} Cij=Lijcls+λLijreg
- 初筛
在计算cost之前,会对样本进行一次初步的筛选,得到正样本的候选区域。正样本的候选区域是以GT中心点围成的 5×5 的区域。
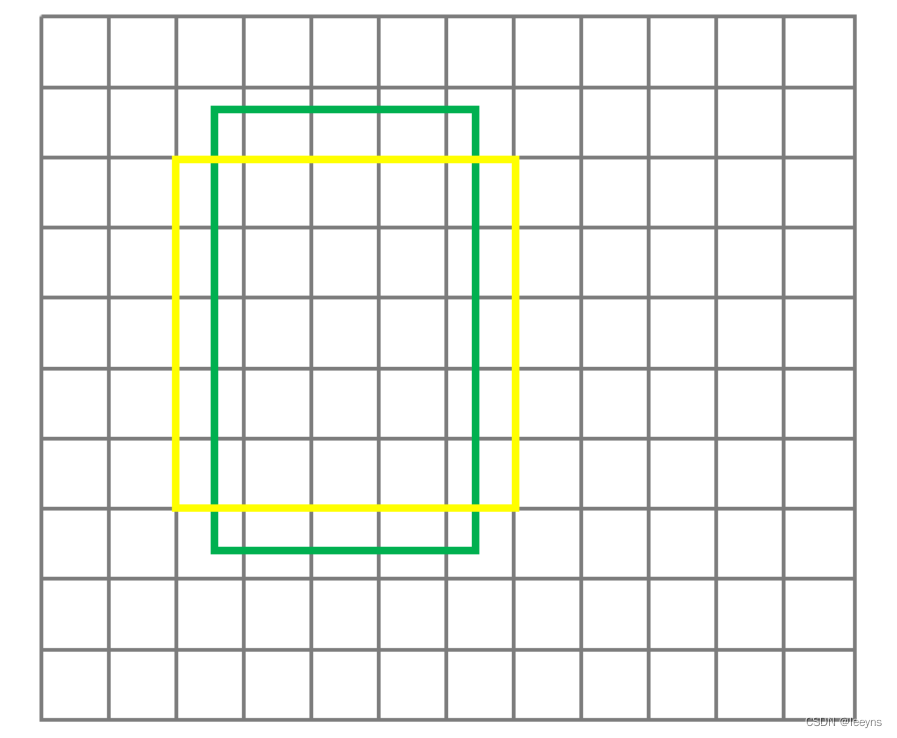
对于这个条件,在代码中也体现在cost function中,因此代码实现中的cost function如下,
C i j = L i j c l s + λ L i j r e g + γ ( n o t _ i n _ G T b o x _ a n d _ c e n t e r _ a r e a ) C_{ij} = L^{cls}_{ij} + \lambda L^{reg}_{ij} + \gamma (not\_in\_GTbox\_and\_center\_area) Cij=Lijcls+λLijreg+γ(not_in_GTbox_and_center_area)
代码中的, λ , γ \lambda, \gamma λ,γ 分别为3,100000。对于不在GT box以及候选框内的预测点给予一个很大的cost.
- 获取
n_candidate_k,这个值是在10和预选框候选数中取最小
n _ c a n d i a t e _ k = m i n ( 10 , i n _ B o x _ n u m ) n\_candiate\_k=min(10, in\_Box\_num) n_candiate_k=min(10,in_Box_num) - 计算预选的正样本与当前gtbox的IoU. 按从大到小的顺序排列选择前 n _ c a n d i a t e _ k n\_candiate\_k n_candiate_k 个预选框的IoU值作为 t o p k _ i o u s topk\_ious topk_ious。
- 通过IoU值计算
dynamic_ks,这是一个动态的预选框选择,不同的GT这个值是不一样的。
d y n a m i c _ k s = t o r c h . c l a m p ( t o p k _ i o u s . s u m ( 1 ) . i n t ( ) , m i n = 1 ) dynamic\_ks = torch.clamp(topk\_ious.sum(1).int(), min=1) dynamic_ks=torch.clamp(topk_ious.sum(1).int(),min=1) - 计算预选正样本的cost,并从小到大进行排序,选择 t o p d y n a m i c _ k s top \ dynamic\_ks top dynamic_ks 个样本作为正样本。
- 如果同一个预选正样本分配给了不同的GT,则选择最小cost的那一个,其他的忽略。