华为诺亚提出VanillaNet--一种新视觉Backbone,极简且强大

VanillaNet简介
基础模型的核心是“更多不同”的哲学,计算机视觉和自然语言处理的惊人成功就是例证。 然而,优化的挑战和Transformer模型固有的复杂性要求范式向简单转变。 在本研究中,我们介绍了VanillaNet,一个在设计中包含优雅的神经网络架构。 通过避免高深度、快捷方式和复杂的操作,如自注意力,VanillaNet是令人耳目一新的简洁,但非常强大。 每一层都被精心制作成紧凑和简单的结构,非线性激活函数在训练后被剪枝,以恢复原始的架构。 VanillaNet克服了固有复杂性的挑战,使其成为资源紧张环境的理想选择。 其易于理解和高度简化的体系结构为高效部署打开了新的可能性。 大量实验表明,VanillaNet提供了与著名的深度神经网络和视觉Transformer相当的性能,展示了极简主义在深度学习中的力量。 VanillaNet的这一远见之旅具有重大的潜力,可以重新定义并挑战基础模型的现状,为优雅有效的模型设计开辟一条新的道路。
在过去的几十年里,研究人员在神经网络的基本设计上达成了一些共识。大多数最先进的图像分类网络架构应该由三部分组成:
- 主干块,用于将输入图像从3个通道转换为多个通道,并进行下采样,一个学习有用的信息主题
- 主体,通常有四个阶段,每个阶段都是通过堆叠相同的块来派生的。在每个阶段之后,特征的通道将扩展,而高度和宽度将减小。不同的网络利用和堆叠不同种类的块来构建深度模型。
- 全连接层分类输出。
尽管现有的深度网络取得了成功,但它们利用大量复杂层来为以下任务提取高级特征。例如,著名的ResNet需要34或50个带shortcat的层才能在ImageNet上实现超过70%的top-1精度。Vit的基础版本由62层组成,因为自注意力中的K、Q、V需要多层来计算。随着AI芯片雨来越大,神经网络推理速度的瓶颈不再是FLOPs或参数,因为现代GPU可以很容易地进行并行计算。相比之下,它们复杂的设计和较大的深度阻碍了它们的速度。为此我们提出了Vanilla网络,即VanillaNet,其框架图如图1所示。我们遵循流行的神经网络设计,包括主干、主体和全连接层。与现有的深度网络不同,我们在每个阶段只使用一层,以建立一个尽可能少的层的极其简单的网络。该网络的特点是不采用shortcut(shortcut会增加访存时间),同时没有复杂的模块如自注意力等。
在深度学习中,通过在训练阶段引入更强的容量来增强模型的性能是很常见的。为此,我们建议利用深度训练技术来提高所提出的VanillaNet在训练期间的能力。
优化策略1: 深度训练,浅层推理 为了提升VanillaNet这个架构的非线性,我们提出首先提出了深度训练(Deep training)策略,在训练过程中把一个卷积层拆成两个卷积层,并在中间插入如下的非线性操作:

其中, A 是传统的非线性激活函数,最简单的还是 ReLU, λ 会随着模型的优化逐渐变为1,两个卷积层就可以合并成为一层,不改变VanillaNet的结构。
优化策略2:换激活函数 既然我们想提升VanillaNet的非线性,一个更直接的方案是有没有非线性更强的激活函数,并且这个激活函数好并行速度快?为了实现这个既要又要的宪法,我们提出一种基于级数启发的激活函数,把多个ReLU加权加偏置堆叠起来:
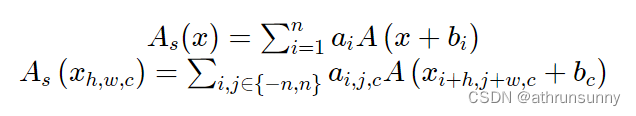
然后再进行微调,提升这个激活函数对信息的感知能力。
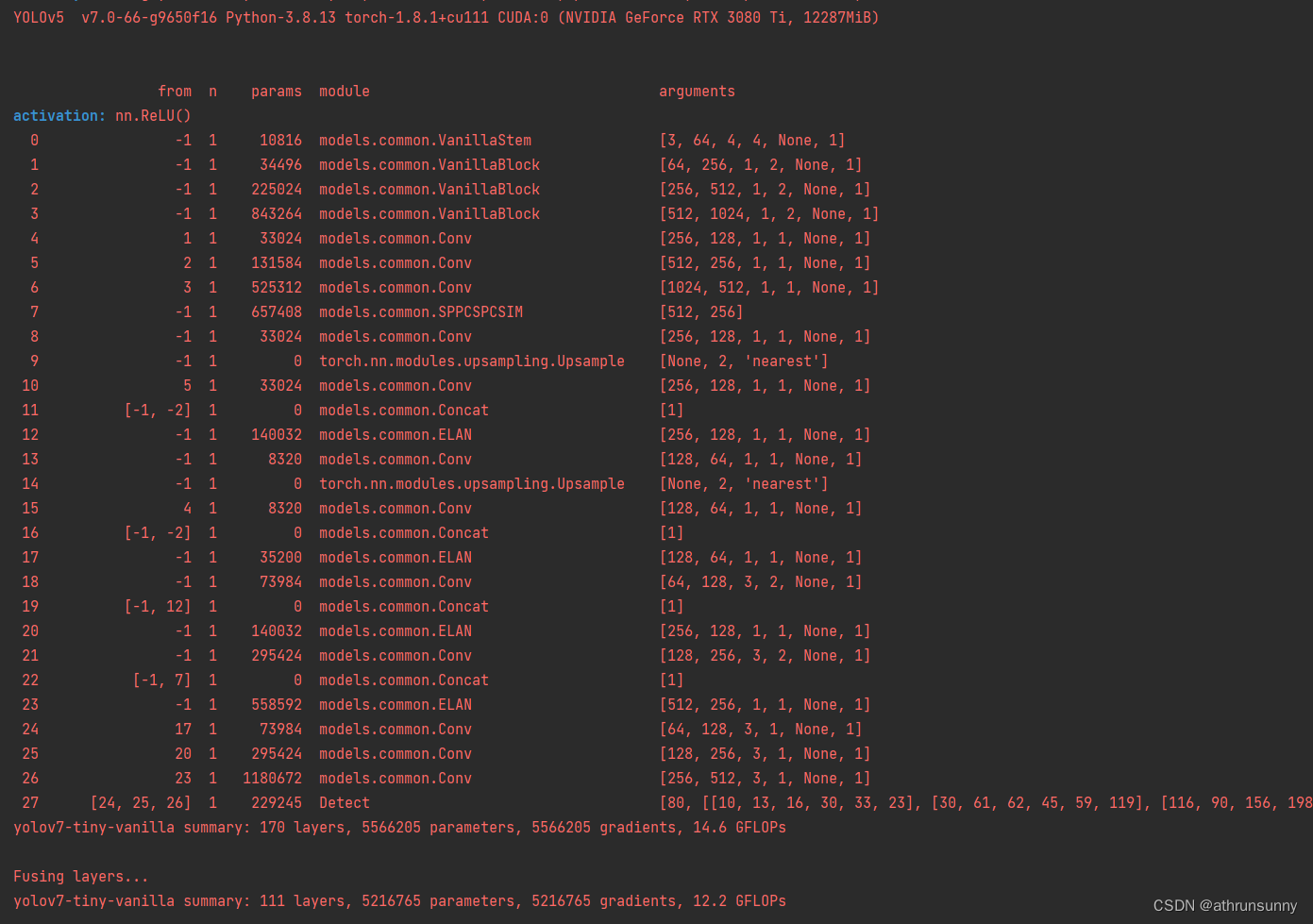
YOLO中改进
以yolov7-tiny的backbone为例,想用v5v8的可以把backbone复制到v5v8的配置中就行
首先配置文件yolov7-tiny-vanilla.yaml:
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
activation: nn.ReLU()
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov7-tiny backbone
backbone:
# [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True
[[-1, 1, VanillaStem, [64, 4, 4, None, 1]], # 0-P1/4
[-1, 1, VanillaBlock, [256, 1, 2, None, 1]], # 1-P2/8
[-1, 1, VanillaBlock, [512, 1, 2, None, 1]], # 2-P3/16
[-1, 1, VanillaBlock, [1024, 1, 2, None, 1]], # 3-P4/32
]
# yolov7-tiny head
head:
[[1, 1, Conv, [128, 1, 1, None, 1]], # 4
[2, 1, Conv, [256, 1, 1, None, 1]], # 5
[3, 1, Conv, [512, 1, 1, None, 1]], # 6
[-1, 1, SPPCSPCSIM, [256]], # 7
[-1, 1, Conv, [128, 1, 1, None, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[5, 1, Conv, [128, 1, 1, None, 1]], # route backbone P3
[[-1, -2], 1, Concat, [1]], # 11
[-1, 1, ELAN, [128, 1, 1, None, 1]], # 12
[-1, 1, Conv, [64, 1, 1, None, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[4, 1, Conv, [64, 1, 1, None, 1]], # route backbone P2
[[-1, -2], 1, Concat, [1]], # 16
[-1, 1, ELAN, [64, 1, 1, None, 1]], # 17
[-1, 1, Conv, [128, 3, 2, None, 1]],
[[-1, 12], 1, Concat, [1]],
[-1, 1, ELAN, [128, 1, 1, None, 1]], # 20
[-1, 1, Conv, [256, 3, 2, None, 1]],
[[-1, 7], 1, Concat, [1]],
[-1, 1, ELAN, [256, 1, 1, None, 1]], # 23
[17, 1, Conv, [128, 3, 1, None, 1]],
[20, 1, Conv, [256, 3, 1, None, 1]],
[23, 1, Conv, [512, 3, 1, None, 1]],
[[24,25,26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]其中ELAN模块为对原配置文件中相应的模块进行过简化处理
为了保证模型整体参数量和v5s以及v7tiny相差太多, VanillaBlock的channel数设置的比原文中要小
在common.py中添加
class activation(nn.ReLU):
def __init__(self, dim, act_num=3, deploy=False):
super(activation, self).__init__()
self.act_num = act_num
self.deploy = deploy
self.dim = dim
self.weight = torch.nn.Parameter(torch.randn(dim, 1, act_num * 2 + 1, act_num * 2 + 1))
if deploy:
self.bias = torch.nn.Parameter(torch.zeros(dim))
else:
self.bias = None
self.bn = nn.BatchNorm2d(dim, eps=1e-6)
nn.init.trunc_normal_(self.weight, std=.02)
def forward(self, x):
if self.deploy:
return torch.nn.functional.conv2d(
super(activation, self).forward(x),
self.weight, self.bias, padding=self.act_num, groups=self.dim)
else:
return self.bn(torch.nn.functional.conv2d(
super(activation, self).forward(x),
self.weight, padding=self.act_num, groups=self.dim))
def _fuse_bn_tensor(self, weight, bn):
kernel = weight
running_mean = bn.running_mean
running_var = bn.running_var
gamma = bn.weight
beta = bn.bias
eps = bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta + (0 - running_mean) * gamma / std
def switch_to_deploy(self):
kernel, bias = self._fuse_bn_tensor(self.weight, self.bn)
self.weight.data = kernel
self.bias = torch.nn.Parameter(torch.zeros(self.dim))
self.bias.data = bias
self.__delattr__('bn')
self.deploy = True
class VanillaStem(nn.Module):
def __init__(self, in_chans=3, dims=96,
k=0, s=0, p=None,g=0, act_num=3, deploy=False, ada_pool=None, **kwargs):
super().__init__()
self.deploy = deploy
stride, padding = (4, 0) if not ada_pool else (3, 1)
if self.deploy:
self.stem = nn.Sequential(
nn.Conv2d(in_chans, dims, kernel_size=k, stride=stride, padding=padding),
activation(dims, act_num, deploy=self.deploy)
)
else:
self.stem1 = nn.Sequential(
nn.Conv2d(in_chans, dims, kernel_size=k, stride=stride, padding=padding),
nn.BatchNorm2d(dims, eps=1e-6),
)
self.stem2 = nn.Sequential(
nn.Conv2d(dims, dims, kernel_size=1, stride=1),
nn.BatchNorm2d(dims, eps=1e-6),
activation(dims, act_num)
)
self.act_learn = 1
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
nn.init.trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward(self, x):
if self.deploy:
x = self.stem(x)
else:
x = self.stem1(x)
x = torch.nn.functional.leaky_relu(x, self.act_learn)
x = self.stem2(x)
return x
def _fuse_bn_tensor(self, conv, bn):
kernel = conv.weight
bias = conv.bias
running_mean = bn.running_mean
running_var = bn.running_var
gamma = bn.weight
beta = bn.bias
eps = bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta + (bias - running_mean) * gamma / std
def switch_to_deploy(self):
self.stem2[2].switch_to_deploy()
kernel, bias = self._fuse_bn_tensor(self.stem1[0], self.stem1[1])
self.stem1[0].weight.data = kernel
self.stem1[0].bias.data = bias
kernel, bias = self._fuse_bn_tensor(self.stem2[0], self.stem2[1])
self.stem1[0].weight.data = torch.einsum('oi,icjk->ocjk', kernel.squeeze(3).squeeze(2),
self.stem1[0].weight.data)
self.stem1[0].bias.data = bias + (self.stem1[0].bias.data.view(1, -1, 1, 1) * kernel).sum(3).sum(2).sum(1)
self.stem = torch.nn.Sequential(*[self.stem1[0], self.stem2[2]])
self.__delattr__('stem1')
self.__delattr__('stem2')
self.deploy = True
class VanillaBlock(nn.Module):
def __init__(self, dim, dim_out,k=0 , stride=2,p=None,g=0, ada_pool=None,act_num=3 ,deploy=False):
super().__init__()
self.act_learn = 1
self.deploy = deploy
if self.deploy:
self.conv = nn.Conv2d(dim, dim_out, kernel_size=1)
else:
self.conv1 = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=1),
nn.BatchNorm2d(dim, eps=1e-6),
)
self.conv2 = nn.Sequential(
nn.Conv2d(dim, dim_out, kernel_size=1),
nn.BatchNorm2d(dim_out, eps=1e-6)
)
if not ada_pool:
self.pool = nn.Identity() if stride == 1 else nn.MaxPool2d(stride)
else:
self.pool = nn.Identity() if stride == 1 else nn.AdaptiveMaxPool2d((ada_pool, ada_pool))
self.act = activation(dim_out, act_num, deploy=self.deploy)
def forward(self, x):
if self.deploy:
x = self.conv(x)
else:
x = self.conv1(x)
# We use leakyrelu to implement the deep training technique.
x = torch.nn.functional.leaky_relu(x, self.act_learn)
x = self.conv2(x)
x = self.pool(x)
x = self.act(x)
return x
def _fuse_bn_tensor(self, conv, bn):
kernel = conv.weight
bias = conv.bias
running_mean = bn.running_mean
running_var = bn.running_var
gamma = bn.weight
beta = bn.bias
eps = bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta + (bias - running_mean) * gamma / std
def switch_to_deploy(self):
kernel, bias = self._fuse_bn_tensor(self.conv1[0], self.conv1[1])
self.conv1[0].weight.data = kernel
self.conv1[0].bias.data = bias
# kernel, bias = self.conv2[0].weight.data, self.conv2[0].bias.data
kernel, bias = self._fuse_bn_tensor(self.conv2[0], self.conv2[1])
self.conv = self.conv2[0]
self.conv.weight.data = torch.matmul(kernel.transpose(1, 3),
self.conv1[0].weight.data.squeeze(3).squeeze(2)).transpose(1, 3)
self.conv.bias.data = bias + (self.conv1[0].bias.data.view(1, -1, 1, 1) * kernel).sum(3).sum(2).sum(1)
self.__delattr__('conv1')
self.__delattr__('conv2')
self.act.switch_to_deploy()
self.deploy = True同时在yolo.py中做如下修改
1、parse_model函数中
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, SPPCSPC, RepConv,
RFEM, ELAN, SPPCSPCSIM,VanillaBlock,VanillaStem):
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x]:
args.insert(2, n) # number of repeats
n = 12、BaseModel的fuse函数
if isinstance(m, (VanillaStem, VanillaBlock)):
# print(m)
m.deploy = True
m.switch_to_deploy()在yolo.py中测试yolov7-tiny-vanilla.yaml