
在本文中,作者根据现有先进方法中各种特征尺度之间缺少的组合连接的问题,提出了一种新的边缘GPU友好模块,用于多尺度特征交互。此外,作者提出了一种新的迁移学习backbone采用的灵感是来自不同任务的转换信息流的变化,旨在补充特征交互模块,并提高准确性和推理速度的各种边缘GPU设备上的可用性。
目录
2.3 Multi-Scale Feature Fusion
1、Truncated feature extraction backbone
2、Raw feature collection and redistribution
1简介
目标检测模型的性能在模型精度和效率两个主要方面得到了快速的发展。然而,为了将基于深度神经网络(DNN)的目标检测模型部署到边缘设备,通常需要对模型进行比较大的压缩,但是与之而来的也降低了模型的准确性。
在本文中,作者根据现有先进方法中各种特征尺度之间缺少的组合连接的问题,提出了一种新的边缘GPU友好模块,用于多尺度特征交互。此外,作者提出了一种新的迁移学习backbone采用的灵感是来自不同任务的转换信息流的变化,旨在补充特征交互模块,并提高准确性和推理速度的各种边缘GPU设备上的可用性。
例如,基于MobileNetV2-0.75 Backbone的YOLO-ReT在Jetson Nano上实时运行,在Pascal VOC上实现了68.75 mAP/33.19FPS(MobileNetV2为68.67 mAP/28.16FPS),在COCO上实现了34.91 mAP/33.19FPS。
此外,在YOLOv4-tiny和YOLOv4-tiny中引入本文的多尺度特征交互模块,使其在COCO上的性能分别提高到41.5和48.1 mAP,比原始版本提高了1.3mAP和0.9mAP。
本文主要贡献
- 提出了RFCR模块,有效结合多尺度特征,兼容各种Backbone和检测头。此外,RFCR模块的特征收集与检测头的输出尺度数无关,便于更好的特征交互;
- 对个体迁移学习层的重要性进行广泛的实验分析,并采用截断方法提高模型效率。截断和RFCR模块相互补充,允许创建更快、更准确的检测模型;
- 针对边缘gpu的设备上执行延迟实验的深入消融研究,而不是其他间接指标,如MFLOPs或模型大小,从而提供各种竞争设计的准确比较。
2研究背景
2.1 单阶段目标检测
单阶段目标检测模型包括2个部分:
- 在ImageNet上预训练的特征提取器
- 负责最终输出的目标检测头
虽然CNN是特征提取模型的首选,但也有一些工作在探索其他形式的特征提取器,如极限学习机(ELM)、运动概率地图等。单阶段目标检测模型可以根据其使用的检测头进一步划分为基于Anchor的模型和Anchor-Free的模型。Heatmap-based的检测模型,如CornerNet、CenterNet等,是Anchor-Free模型的常见例子。然而,这些模型需要复杂计算的Backbone,因为它们依赖于保持输入图像的高分辨率信息的完整性。另一方面,基于Anchor的检测模型是较轻的选择。例如YOLOv3检测头是边缘设备最常用的检测头之一,可以轻松集成轻量级Backbone。
2.2 Building Blocks
对实时目标检测模型的大量研究都致力于改进CNN的基本构建模块。传统的CNN层包含大量的参数和计算,这使得大多数实时检测模型明显是浅层网络。将二维卷积解耦为深度可分离卷积和(1×1)卷积是一种使网络更轻的常用技术。在应用卷积之前,使用1×1卷积进一步减少通道数量,产生了fire 模块的想法,并已被应用于各种轻量级检测模型。
然而,使用多个连续pointwise卷积来降低信息流的计算成本,违反了设计快速深度学习模型的一个基本规则,即网络碎片化。网络碎片化是一种现象,在这种现象中,一个较重的操作被碎片化为多个轻量级操作,并严重影响模型的执行速度,因为它干扰了模型内部的并行度。例如,mobiledet发现分组的point-wise卷积在GPU设备上执行得不好,而ShuffleNetV2发现当输入和输出通道数量相同时,point-wise卷积速度最快。
最后的特征提取Backbone是通过组合上述的一个或多个构建块而形成的。许多研究甚至利用神经结构搜索(NAS)来建立他们自己的Backbone和检测模型。然而,这些模型忽略了存在于其他预训练Backbone中的迁移学习信息。另一方面,在现有数据集上预训练的Backbone可能包含分类任务特定的特征,这可能会增加不必要的特征计算负担。因此,从分类到目标检测的预训练Backbone的有效适应也对模型的最终性能起着重要作用。
2.3 Multi-Scale Feature Fusion
无论是在单阶段还是两阶段目标检测模型中,多尺度特征交互都是目标检测头的重要组成部分。现有的特征交互方法采用自顶向下或自底向上的方法相结合的方法来处理跨多尺度特征的信息流。特征金字塔网络(FPN)是第一个创建从高级特征尺度到低级特征尺度的自上而下路径,目的是使用处理良好的深层特征,以帮助提高使用较浅特征的检测层的准确性。PANet更进一步,表明额外的自底向上路径有助于进一步提高High-Level特征的检测精度。
在FPN和PANet成功的基础上,NAS-FPN试图寻找各种多尺度特征之间的最优信息流路径。由于这种基于架构搜索的模型是专门为某些数据集和Backbone网络设计的,因此很难将它们推广到更广泛的应用中。然而,这些搜索揭示了有趣的趋势,可以帮助更多地了解此类模型的内在需求。NAS-FPN设计揭示了不同特征尺度之间不相邻的直接联系,表明仅通过相邻尺度的信息流动可能会变得复杂,因此需要这种ShortCut。同样,NAS-FPN也揭示了反复遵循自上而下和自下而上路径的重要性,BiFPN后来采用了这一路径来进一步提高模型精度。
不仅是将多尺度特征组合在一起的路径,而且还对各种特征如何组合做了大量工作。虽然大多数现有工作只是简单地将多个尺度的特征图连接在一起,但也有人提出了加权或基于注意力的特征融合,以更好地突出更重要的特征尺度。融合特征的另一个方面是使它们达到共同的规模。更简单的解决方案包括对一个特征尺度进行上采样或下采样以匹配另一个特征尺度。然而,这可能导致不同尺度之间的局部位置不匹配,因此也探索了多种方法来处理融合前后的特征,以促进不同尺度之间更好的信息流动。
3本文方法
3.1 原始特征收集和再分配——RFCR
作者希望使用改进的特征交互网络来加强Backbone提取特征的能力进而提高检测精度,同时也不对推理速度造成任何重大影响。虽然本文中重点关注检测,但RFCR模块可以推广为类似任务提供交互特征。
现有的多尺度特征交互方法可以分解为自顶向下和自底向上方法的组合,这种方法一次只关注两个相邻的特征尺度。这使得大量可能的组合对被遗漏,使得信息在远处特征尺度之间的传播效率低下。此外,当重复使用自顶向下和自底向上的路径(例如从BiFPNx2到BiFPNx3)时模型的检测精度开始饱和。
在这里,受到NAS-FPN中非相邻特征尺度连接的启发,本文提出了一个轻量级的特征收集和再分配模块,该模块将来自Backbone的原始多尺度特征融合在一起,然后将其重新分配到每个特征尺度。因此,每个比例的特征图包含了所有其他比例尺度的特征。这种层不涉及任何沉重的计算或参数,但允许每对特征尺度之间的直接联系,如图1所示。
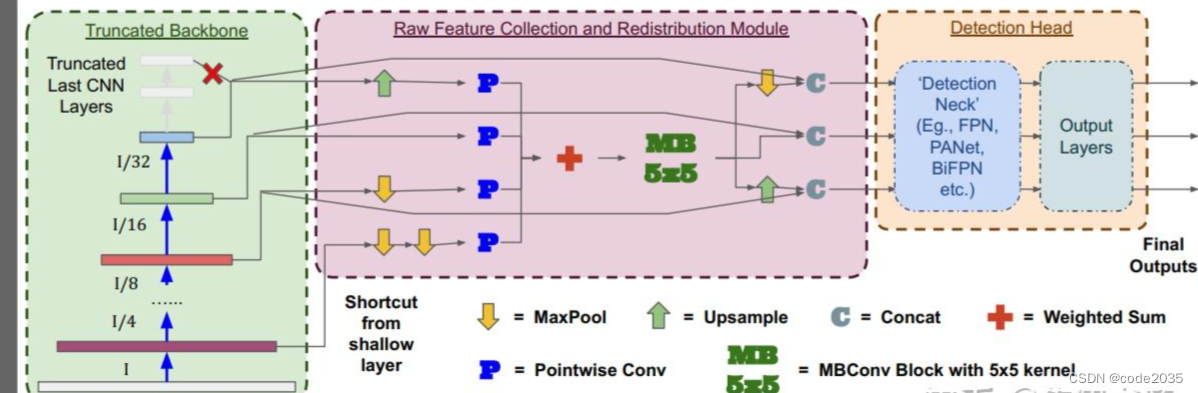
需要注意的是,RFCR模块无法取代其他特征聚合方法提供的细致性,相反,目标是在将其传递给其他多尺度特征融合方法之前,提供一个极其轻量级的特征处理,在精度上提供正交改进。
此外,RFCR模块设计允许有独立于检测头的输出尺度数量,因为RFCR模块的输入和输出特性之间没有限制。例如,尽管YOLOv3检测头有3个输出尺度,但在特征采集阶段可以使用4个不同的Backbone特征(3个与输出尺度相同的特征,第4个较浅的特征),这样就可以利用更细粒度的low-level特征来提高模型性能。同样的,即使对于只有2个输出刻度的检测头,如YOLOv4-tiny,通过采用RFCR模块,检测功能也被多个low-level特征丰富了。
正如在第2.3节中讨论的,特征融合的方式与聚合路径同样重要。为了将额外的延迟开销保持在最小,在收集过程中通过单个1x1卷积传递原始特征,并使用简单的加权和将特征融合在一起。作者将融合后的特征图通过MobileNet的卷积块(MBConv),然后将其重新分配回不同的尺度。
这样的设计允许保持网络碎片到最小,因为RFCR模块可以只有4层:
- 1x1卷积
- Weighted sum
- MBConv
- 上采样和下采样层。
特性的并行收集和重新分配也可以很容易地进行优化,进而可以提高执行速度。
在融合不同尺度的特征时,单纯的上采样和下采样会导致语义不一致和局部位置失配。因此,提出使用5x5卷积核来增加特征融合层的感受野,而不是传统的3x3或1x1卷积核,以帮助提高模型的检测精度,同时对其推理延迟的影响可以忽略不计。作者还发现将kernel size增加到7x7时并不能进一步提高性能。
def RFCR_Module(inp_arr):
b1c = inp_arr[0]
b2c = inp_arr[1]
b3c = inp_arr[2]
b4c = inp_arr[3]
b1c = tf.keras.layers.Conv2D(48, kernel_size=1, padding='same', use_bias=False)(b1c)
b2c = tf.keras.layers.Conv2D(48, kernel_size=1, padding='same', use_bias=False)(b2c)
b3c = tf.keras.layers.Conv2D(48, kernel_size=1, padding='same', use_bias=False)(b3c)
b4c = tf.keras.layers.Conv2D(48, kernel_size=1, padding='same', use_bias=False)(b4c)
bc = WeightedSum()([tf.keras.layers.UpSampling2D()(b1c), b2c, downsample_layer(b3c), b4c])
bc = MobilenetSeparableConv2D(96,
kernel_size=(5, 5),
use_bias=False,
padding='same')(bc)
b1 = tf.keras.layers.Concatenate()([inp_arr[0], downsample_layer(bc)])
b2 = tf.keras.layers.Concatenate()([inp_arr[1], bc])
b3 = tf.keras.layers.Concatenate()([inp_arr[2], tf.keras.layers.UpSampling2D()(bc)])
return b1, b2, b3
3.2 Backbone Truncation
大多数最先进的轻量级图像分类模型试图通过在每几个卷积块之后逐渐增加通道的数量来将通道的数量保持在最小。然而,到了最后,即使是这些模型也开始在每个块之后迅速扩展通道的数量,试图在最终 FC 层之前更清楚地表示特征。

从分类模型迁移学习的重要性以前就受到过质疑,一些论文甚至设计了专门的检测Backbone。这是基于直觉,而在任务中是不同的。例如,分类模型不保留空间信息,可能累积成空间粗特征。
另一方面,检测模型试图保持空间信息的完整性,这是细粒度检测输出所需要的。作者发现,Backbone的初始层的迁移学习能力是非常重要的,而最后一层并不会为检测/识别提供关键信息。
作者测试了单个Backbone卷积层的重要性,详细分析了各个Backbone的迁移学习能力,完成了PANet特征聚合路径和YOLOv3检测头。
作者用3个常用的Backbone进行实验,分别是:MobilenetV2-0.75、MobilenetV2-1.4和EfficientNet-B3,并将Backbone分成不同的块,在本例中是Mobilenet V2 的MBConv块和EfficientNet的MBConvSE块。接下来,逐渐增加使用ImageNet数据集预训练的权值初始化的块的数量,从浅到深,而其余的块则像检测头一样随机初始化,并训练每个单独的模型收敛。收集的结果如图2所示。
从图中可以看出,当增加使用预训练过的权值初始化的特征提取Backbone的比例时,模型的性能得到了提高,这也强调了迁移学习的重要性。然而,在60%左右,表现开始恶化和波动。这表明,与随机初始化相比,使用来自ImageNet的迁移学习权值初始化最后一层特征提取器实际上会损害性能,这可能是因为这些层的特定任务性质导致它们陷入局部极小值。
由于最后的这些层没有迁移学习的需要,所以可以纯粹从架构的角度来分析它们。如图2所示,由于与目标检测无关的通道数量的极端扩展,最后2或3层包含了超过40%的权重。因此,作者提出使用截断版本的各种Backbone作为最终目标检测模型。作者使用图2的结果来找到截断点,即截断来自MobileNetV2版本的最后两个块,以及EfficientNet的最后三个块。
4实验
4.1 消融实验
1、Truncated feature extraction backbone
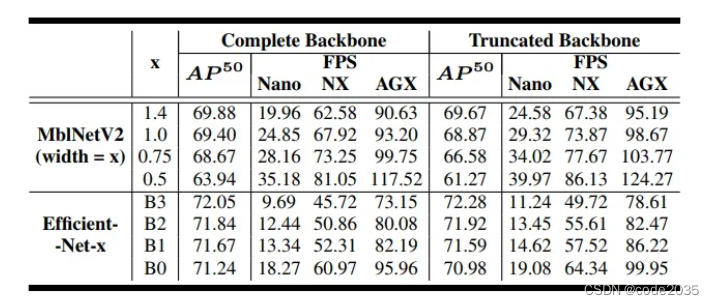
作者比较了2种压缩MobileNetV2和EfficientNet主干的方法,这两种方法降低了缩放因子(或MobileNetV2的宽度倍增器)并截断了最后的参数层,并得到了表2中的结果。值得注意的是,删节版的EfficientNet在准确性和FPS方面都优于其他版本,这样强调了分类任务特定骨干特征的负面影响。
对于MobileNetV2,在比较帧数相似的模型时,主干截断的模型比缩放因子较小的模型性能更好。例如,当比较截断主干MobileNetV2x1.4和完整主干MobileNetV2x1.0时,它们都提供了相似的FPS,而前者提供了更好的0.27 mAP。这是由于减少宽度乘法器减少了所有层的通道数量,而截断主干只删除了最后一层的特征。这种差异在低功率设备上更轻的机型上表现得更明显。例如,MobileNetV2中宽度为0.75的截断主干提供了与宽度为0.5的完整主干相似的FPS(在Jetson Nano中分别为34.02和35.18),但在mAP中提供了2.64点的提升。
显然,当在边缘推理时,使用截断的主干更优。
2、Raw feature collection and redistribution
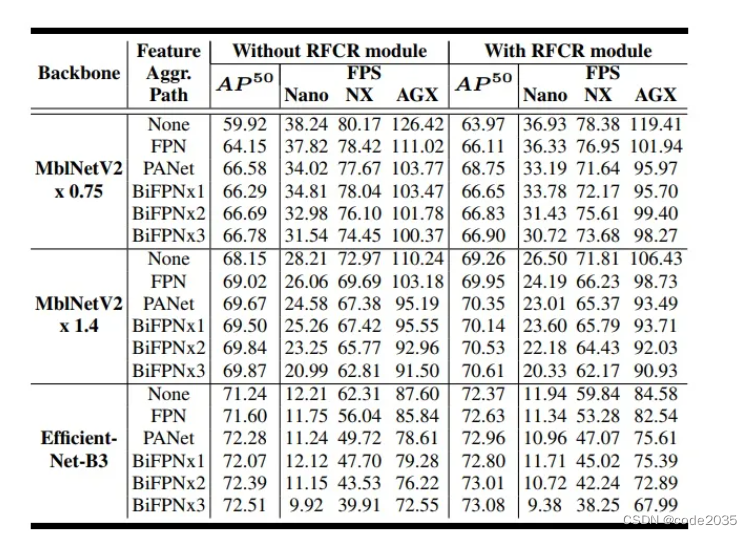
在深入研究表3时可以注意到,当没有其他的特性聚合方法时,特征再分配的效果要显著得多。这可以归因于这样一个事实,即在多尺度特征之间没有任何相互作用的情况下,除了通过主干本身,这种再分配提供了非常需要的特征相互作用。然而,即使使用BiFPNx3,本文方法在性能上仍然得到了显著的提升,这显示了非相邻层之间的shortcut 连接的重要性。
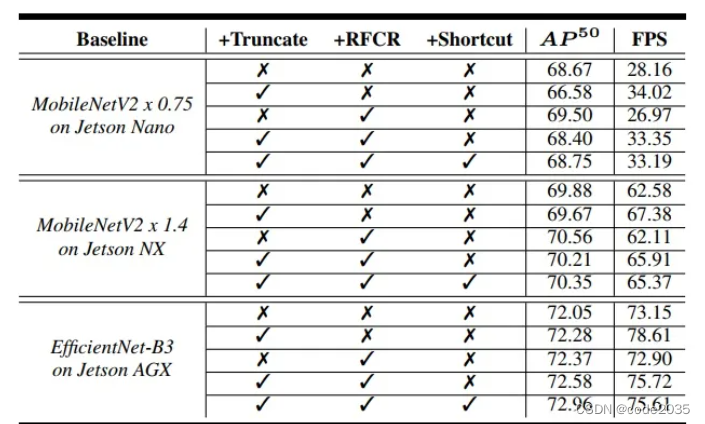
最后,将以上讨论的所有方法结合起来进行联合成分消融研究。结果收集于表4。从Jetson Nano的MobileNetV2(0.75)主干、Jetson Xavier NX的MobileNetV2(1.4)主干和Jetson AGX Xavier的EfficientNet-B3主干开始,以及基于YOLOv3对象检测头和轻量级检测层的PANet功能聚合。接下来,在不截断主干的情况下测试RFCR模块。虽然RFCR模块在这两种情况下表现都很好,但具有完整主干的模型FPS的下降要比具有截断主干的模型更多。这是因为完整的主干在末端有较重的层,这使得下面的特性聚合层也较重。
正如3.1节所讨论的,作者还引入了"shortcut"到RFCR模块中。这种来自主干较浅层的额外“shortcut”进一步提高了准确性,强调了low-level特征对检测任务的重要性,以及本文的设计在使用更多的主干输入特征而非输出尺度数量时所提供的自由度。综上所述,通过将主干截断和RFCR模块相结合,既能加快推理速度,又能提高精度。
3、SOTA对比

5参考
[1].YOLO-ReT: Towards High Accuracy Real-time Object Detection on Edge GPUs