前言
NER标注的中文名为命名实体识别,与词性标注一样是自然
语言处理的技术基础之一。
NER标注是指对现实世界中某个对象的名称的识别,例如法
国、Donald Trump或者微信。在这些词汇中法国是一个国家,标识
为GPE(地缘整治实体), Donald Trump标识为PER(人名),微
信是一家公司,因此被标识为ORG(组织)。
项目要求:
i. 模拟实际项目的数据处理和训练整个过程;
ii. 文本数据的标注工作;
iii. 标注数据作为输入的保存形式;
iv.spaCy训练新的实体抽取模型。
导入所需要模块
from __future__ import unicode_literals, print_function
import pandas as pd
import numpy as np
import os
import plac
import random
from pathlib import Path
import spacy
from spacy.training import Example
import re
一、数据预处理
对每笔数据抽取三种实体即:中标方(bidder)、招标方(buyer)、中标金额(money);

由于文本是由人工分组来标注,因此数据会比较杂乱无章,同时会有一些空格的错误导致原数据和标签数据不对应,影响后面模型训练。
因此,先将不规范的数据改为规范数据,实在整理不了的数据就进行删除处理,处理后的文件有32个文件数据,1个文件10条文本数据。
path = "C:\\Users\\11752\\Desktop\\大三下\\自然语言处理\\作业6--数据标注及其应用\\train_data\\" #文件夹目录
files= os.listdir(path) #得到文件夹下的所有文件名称
position = []
for file in files: #遍历文件夹
position_ = path+'\\'+ file #构造绝对路径,"\\",其中一个'\'为转义符
position.append(position_)
print (position)

将训练集:测试集=7:3划分数据。
data_train = position[:int(len(position)*0.7)] #从数据中选取70%作为训练集,26条数据
data_test = position[-int(len(position)*0.3):]
for j in data_train:
with open(j, "r",encoding='utf-8') as f: #打开文件
for i in f.readlines():
train_data.append(i)
for j in data_test:
with open(j, "r",encoding='utf-8') as f: #打开文件
for i in f.readlines():
test_data.append(i)
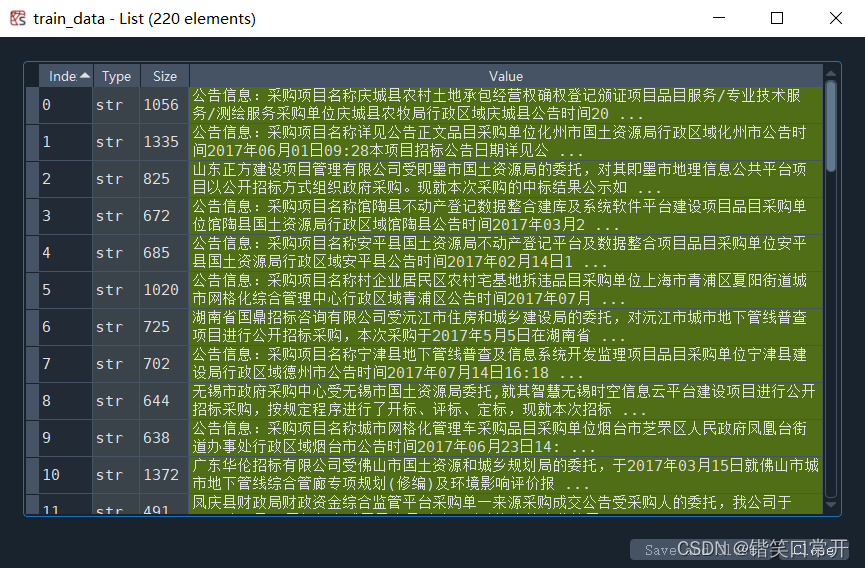
划分后训练集数据220条。注意训练集和标签数据要一一对应,因为不一一对应的话会存在一个中标方在多个数据文件中出现,导致索引错误。
将数据处理成模型所需要的格式。
import re
TRAIN_DATA = []
test = []
test1 = []
for i in range(len(train_data)):
for j in range(len(train_label)):
if i==j:
try:
out = re.finditer(train_label.iloc[j][0],train_data[i])
for k in out:
test.append(tuple(list(k.span())+["BIDDER"]))
except:
pass
try:
out1 = re.finditer(train_label.iloc[j][1],train_data[i])
for k in out1:
test.append(tuple(list(k.span())+["BUYER"]))
except:
pass
try:
out2 = re.finditer(train_label.iloc[j][2],train_data[i])
for k in out2:
test.append(tuple(list(k.span())+["MONEY"]))
except:
pass
if test != []:
test1.append(test)
element = (train_data[i],{
'entities':test1[0]})
TRAIN_DATA.append(element)
test = []
test1 = []
类似这种格式:

真实数据处理后: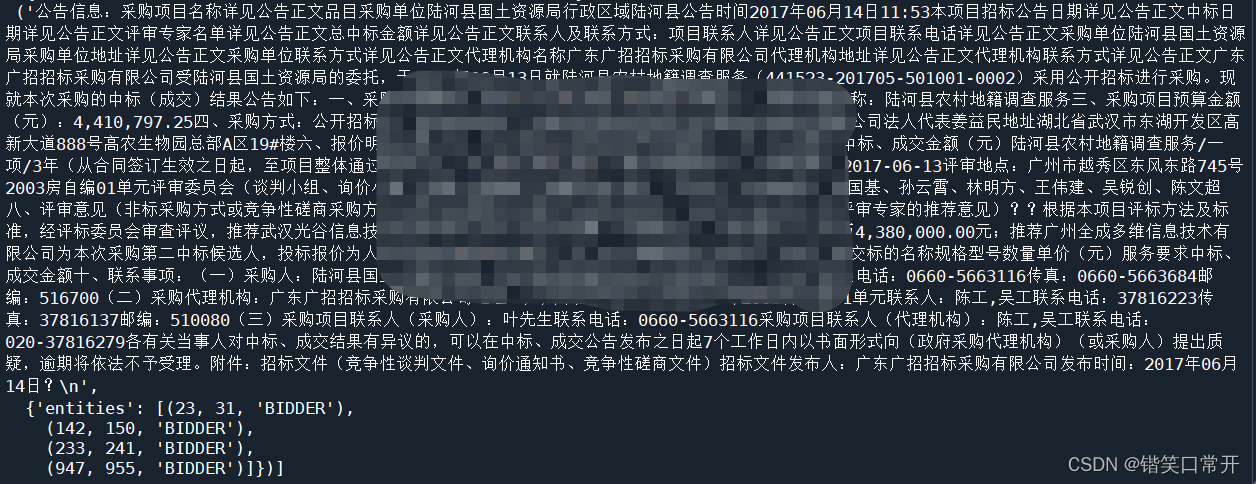
二.spaCy模型训练
对于处理好的训练集,输入到spaCy模型中进行训练,并对训练后的模型进行保存,之后调用保存的模型对测试集测试,代码如下:
def main(model=None, output_dir = None, n_iter=200):
aa = 0
"""Load the model, set up the pipeline and train the entity recognizer."""
if model is not None:
nlp = spacy.load(model) # load existing spaCy model
print("Loaded model '%s'" % model)
else:
nlp = spacy.blank('zh') # create blank Language class
print("Created blank 'zh' model")
# create the built-in pipeline components and add them to the pipeline
# nlp.create_pipe works for built-ins that are registered with spaCy
if 'ner' not in nlp.pipe_names:
ner = nlp.create_pipe('ner')
nlp.add_pipe('ner', last=True)
# otherwise, get it so we can add labels
else:
ner = nlp.get_pipe('ner')
# add labels
for _, annotations in TRAIN_DATA:
for ent in annotations.get('entities'):
ner.add_label(ent[2])
# get names of other pipes to disable them during training
other_pipes = [pipe for pipe in nlp.pipe_names if pipe != 'ner']
with nlp.disable_pipes(*other_pipes): # only train NER
optimizer = nlp.begin_training()
for itn in range(n_iter):
random.shuffle(TRAIN_DATA)
losses = {
}
for text, annotations in TRAIN_DATA:
try:
# print('第%s条数据'%aa)
# aa += 1
example = Example.from_dict(nlp.make_doc(text), annotations)##对数据进行整理成新模型需要的数据
# print("example:",example)
nlp.update(
[example], # batch of annotations
drop=0.5, # dropout - make it harder to memorise data
sgd=optimizer, # callable to update weights
losses=losses)
except:
pass
print(losses)
# save model to output directory
if output_dir is not None:
output_dir = Path(output_dir)
if not output_dir.exists():
output_dir.mkdir()
nlp.to_disk(output_dir)
print("Saved model to", output_dir)
if __name__ == '__main__':
main( output_dir = "./model——ner/") ###模型保存路径
由于数据较多,迭代300次共耗费4个小时左右,误差1500左右。
三.测试集测试模型
代码如下:
import spacy
###导入训练好的模型,测试新的数据
def load_model_test(path,text):
nlp = spacy.load(path)
print("Loading from", path)
doc = nlp(text)
for i in doc.ents:
print(i.text,i.label_)
if __name__ == "__main__":
path = "./model——ner/"
for i in test_data:
load_model_test(path,i)
结果如下:
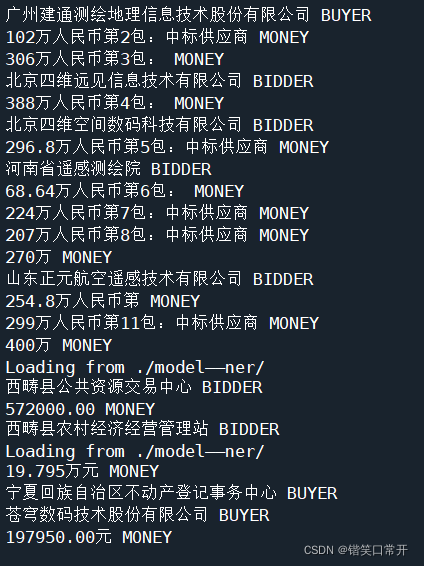
根据上图测试结果来看,总体预测结果良好,能准确找出中标公司名称。
训练集模型代码
# -*- coding: utf-8 -*-
"""
Created on Mon Apr 11 21:19:12 2022
@author: He Zekai
"""
from __future__ import unicode_literals, print_function
#读取所有文档--data
import pandas as pd
import numpy as np
import os
import plac
import random
from pathlib import Path
import spacy
from spacy.training import Example
import re
path = "C:\\train_data\\" #文件夹目录
files= os.listdir(path) #得到文件夹下的所有文件名称
train_data = []
test_data = []
data_train = []
data_test = []
position = []
for file in files: #遍历文件夹
position_ = path+'\\'+ file #构造绝对路径,"\\",其中一个'\'为转义符
position.append(position_)
print (position)
data_train = position[:int(len(position)*0.7)] #从数据中选取70%作为训练集,26条数据
data_test = position[-int(len(position)*0.3):]
for j in data_train:
with open(j, "r",encoding='utf-8') as f: #打开文件
for i in f.readlines():
train_data.append(i)
for j in data_test:
with open(j, "r",encoding='utf-8') as f: #打开文件
for i in f.readlines():
test_data.append(i)
#%%读取处理后标签文档--txt
path = "C:\\data_new\\" #文件夹目录
files= os.listdir(path) #得到文件夹下的所有文件名称
txt = pd.DataFrame()
train_label = pd.DataFrame()
test_label = pd.DataFrame()
position = []
position_train = []
position_test = []
for file in files: #遍历文件夹
position_ = path+'\\'+ file #构造绝对路径,"\\",其中一个'\'为转义符
position.append(position_)
print(position)
# 划分训练集,测试集
position_train = position[:int(len(position)*0.7)] #从数据中选取70%作为训练集,26条数据
position_test = position[-int(len(position)*0.3):]
for file in position_train:
print(file)
datai = pd.read_csv(file,encoding='utf8',sep=' ',error_bad_lines=False, header=None)
datai_len = len(datai)
train_label = train_label.append(datai) # 添加到总的数据中
import re
TRAIN_DATA = []
test = []
test1 = []
for i in range(len(train_data)):
for j in range(len(train_label)):
if i==j:
try:
out = re.finditer(train_label.iloc[j][0],train_data[i])
for k in out:
test.append(tuple(list(k.span())+["BIDDER"]))
except:
pass
try:
out1 = re.finditer(train_label.iloc[j][1],train_data[i])
for k in out1:
test.append(tuple(list(k.span())+["BUYER"]))
except:
pass
try:
out2 = re.finditer(train_label.iloc[j][2],train_data[i])
for k in out2:
test.append(tuple(list(k.span())+["MONEY"]))
except:
pass
if test != []:
test1.append(test)
element = (train_data[i],{
'entities':test1[0]})
TRAIN_DATA.append(element)
test = []
test1 = []
def main(model=None, output_dir = None, n_iter=200):
aa = 0
"""Load the model, set up the pipeline and train the entity recognizer."""
if model is not None:
nlp = spacy.load(model) # load existing spaCy model
print("Loaded model '%s'" % model)
else:
nlp = spacy.blank('zh') # create blank Language class
print("Created blank 'zh' model")
# create the built-in pipeline components and add them to the pipeline
# nlp.create_pipe works for built-ins that are registered with spaCy
if 'ner' not in nlp.pipe_names:
ner = nlp.create_pipe('ner')
nlp.add_pipe('ner', last=True)
# otherwise, get it so we can add labels
else:
ner = nlp.get_pipe('ner')
# add labels
for _, annotations in TRAIN_DATA:
for ent in annotations.get('entities'):
ner.add_label(ent[2])
# get names of other pipes to disable them during training
other_pipes = [pipe for pipe in nlp.pipe_names if pipe != 'ner']
with nlp.disable_pipes(*other_pipes): # only train NER
optimizer = nlp.begin_training()
for itn in range(n_iter):
random.shuffle(TRAIN_DATA)
losses = {
}
for text, annotations in TRAIN_DATA:
try:
# print('第%s条数据'%aa)
# aa += 1
example = Example.from_dict(nlp.make_doc(text), annotations)##对数据进行整理成新模型需要的数据
# print("example:",example)
nlp.update(
[example], # batch of annotations
drop=0.5, # dropout - make it harder to memorise data
sgd=optimizer, # callable to update weights
losses=losses)
except:
pass
print(losses)
# save model to output directory
if output_dir is not None:
output_dir = Path(output_dir)
if not output_dir.exists():
output_dir.mkdir()
nlp.to_disk(output_dir)
print("Saved model to", output_dir)
if __name__ == '__main__':
main( output_dir = "./model——ner/") ###模型保存路径