MySql系列整体栏目
深入理解redolog,undolog和binlog的底层原理和关系
一, 深入理解Redolog日志底层原理
再看本篇文章之前,可以结合【9】深入理解mysql执行的底层机制 这篇文章来了解mysql内部执行sql的过程。
1,innodb引擎底层事务原理
事务的四大特性主要是是acid,分别是原子性、一致性、隔离性和持久性。其原子性是 通过这个undolog 来保证的,持久性是 通过redolog 来实现的,隔离性是通过事务的 读写锁+mvcc机制 来实现的。在这四大特性中,一致性C是最重要的,他是最终目的,只有其他三个实现了,才有可能实现这个一致性,即 一致性是最终目的,其他三个就是实现的手段 。
1.1,WAL
在事务的具体实现的机制中,mysql是通过这个WAL(Write-ahead logging),即预写日志的方式来实现的。
举个基本的例子,假设一个转钱的操作,如果A给B转钱,此时A减了100,而在B在加100的时候,突然断电了,那么在数据库重启的时候,就得恢复他断电前的状态,此时就需要一个日志来记录他事务操作前的状态了,通过这个日志中的记录来恢复之前的状态,判断其是否需要回滚操作,还是需要重做等操作。而实现这个WBL机制,主要是通过这个redolog和undolog这两种日志的方式实现。
mysql中除了使用这种主流的WAL机制之外,还会使用一些Commit Logging丶Shadow Paging等。mysql默认使用这个WAL机制。
2,redolog日志文件
2.1,为什么要redolog日志文件
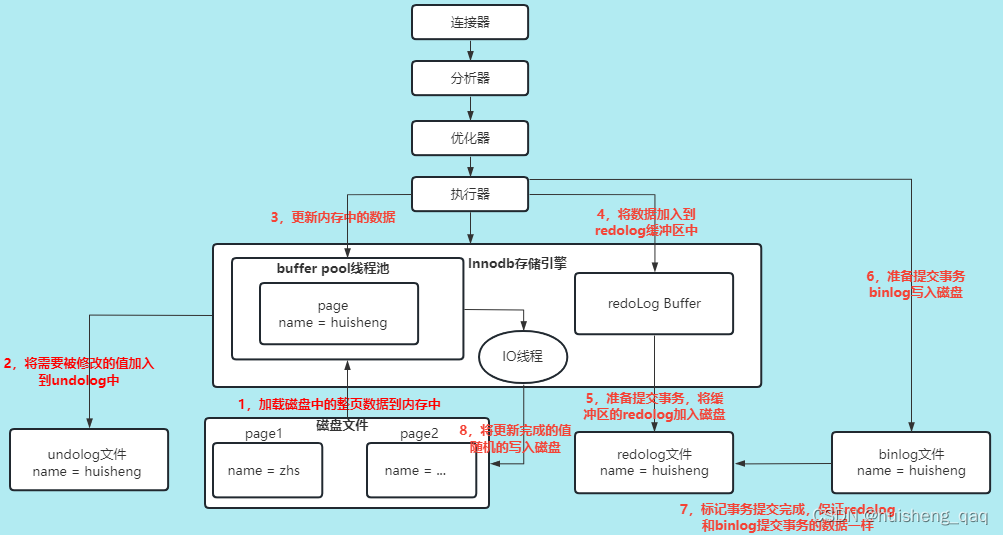
依旧拿一个更新语句举例,如下图,redolog是发生在第4步和第5步,在数据在buffer pool中进行数据更新之后,会把具体的逻辑语句,如哪一页哪一行要更新的字段以及更新的值是啥,先加入到redolog buffer中,随后再然后通过追加的方式持久化到磁盘上的redolog文件中,再不考虑server层的操作,即跳过6,7步,那么就会启动一个后台线程进行一个落盘的操作。
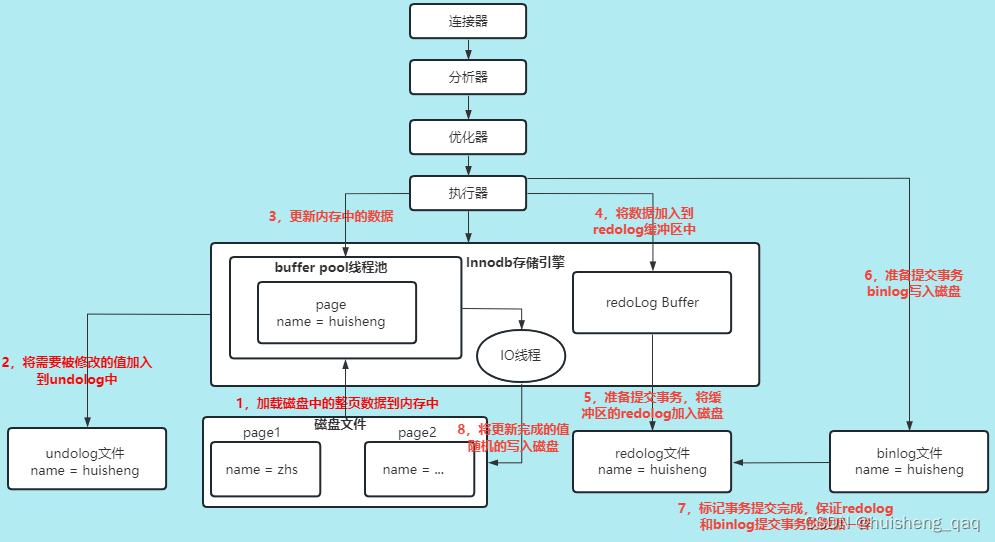
这里假设innodb内部没有这个redolog这个日志文件,就是在数据更新之后直接从buffer pool将数据给落盘,如果在落盘的时候数据页没有发生损坏,那么双写机制就触发不了,就没有换页的操作,此时发生断电,那么还没来的及落盘的数据就会直接丢失了,这就会影响数据的安全性和持久化。
除了断电这个问题,还有可能因为一个小小的更新语句,就直接将整页数据给进行落盘操作,这样就很浪费成本;或者遇到一个sql很复杂,需要涉及的表很多,并且数据量很大,那么就需要更改很多页目录的数据,如果这些页目录在磁盘上的分布是随机的,那么在刷盘写数据的时候,就会产生大量的随机io,因此也很影响内部的执行效率和浪费空间。
所以为了解决数据的安全性以及innodb的执行效率,就引入了这个redolog日志文件,就是在落盘时先写一份到redolog中,并且写数据是顺序写,在redolog写成功之后,再进行落盘操作,如果出现断电问题,就用这个redolog这个文件进行数据的重做。
2.2,redolog的内部结构
redolog主要是记录了哪些数据做了什么修改,因此这个redolog有一个通用的格式,如下图:

| key | value |
|---|---|
| type | 就是值数据的类型,类型总共有53种 |
| Space ID | 表空间id,即修改的对应表空间的id |
| page Number | 当前页的页号 |
| data | 要修改的内容 |
2.3,redolog的刷盘时机
在innodb的体系结构中,可以发现在左边的内存结构中是有一个Log Buffer的缓冲区的,该缓冲区就是对应的redolog缓冲区,在该缓冲区中,其默认大小为16M,并且内部分成了多个小块,每一块的大小空间为512kb。在数据写入这个redolog的缓冲区的时候,会从头到尾的以追加的方式将数据写入这些块中,如果后面的块快写满,那么会将前面头部的块的数据删掉,然后再从头到尾开始存储数据,磁盘上面的redolog页结构和这个一样。
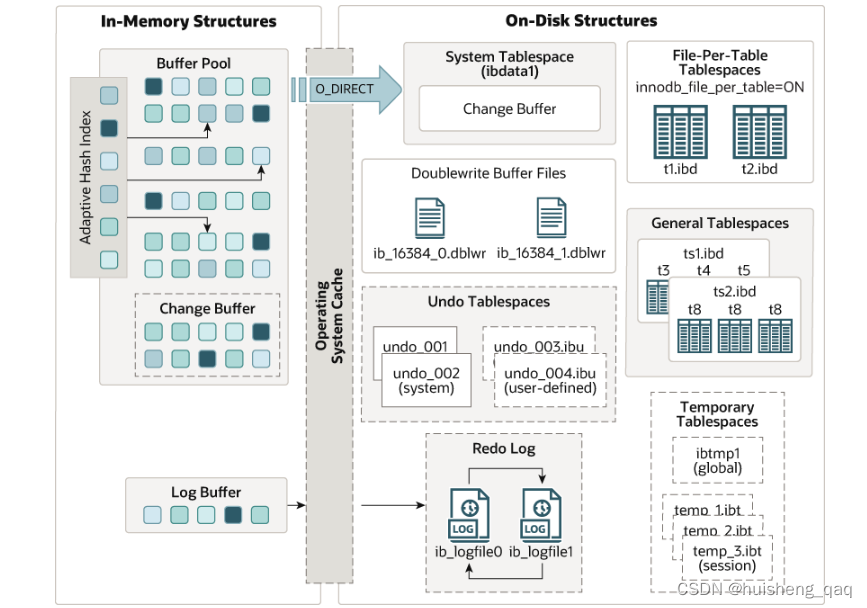
而这个缓冲区刷盘的情况有好几种,如下:
1,log buffer空间不足时,虽然说redolog缓冲区数据存满会将前面的数据删除再重新存储,但是删除之前也是要考虑数据的持久化的,innodb内部认为,当数据量达到redolog缓冲区空间的一半大小时,就需要强制的进行一次刷盘操作,从而把日志落盘到磁盘上。
2,事务提交时,在事务提交时,也是需要将缓冲区中对应的那些日志数据刷新到磁盘的
3,后台默认线程,后台也是会启动一个默认的线程进行一个刷盘操作的,如每一秒刷新一次
4,服务器手动关闭,在服务器关闭时,也是需要将未刷盘的数据全部的进行一次刷盘操作。
2.4,Log Sequence Number
简称LSN,顾名思义,这个就是一个日志序列号。和undolog一样,在执行一条更新或者插入语句的时候,就会生成一个事务id,这里的序列号和undolog的事务id的作用是一样的,主要是是保证数据的唯一性。该值是一个自增的序列号,初始大小为8704,后面每增加一条数据,其对应的序列号的值就会加1。即LSN的值越小,那么其事务产生的越早。
除了这个日志之外,innodb内部还有其他的LSN用来记录已经刷盘的事务id。可以通过具体的命令来查看系统中各种LSN的值
SHOW ENGINE INNODB STATUS\G
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nLvi11mp-1677138921851)(img/1676971333812.png)]](https://img-blog.csdnimg.cn/59052e760ad6474896a30a88dc4f0580.png)
| key | value |
|---|---|
| Log sequence number | 已经写入redolog buffer的日志量(累加值) |
| Log flushed up to | 已经写入磁盘的redo日志量 |
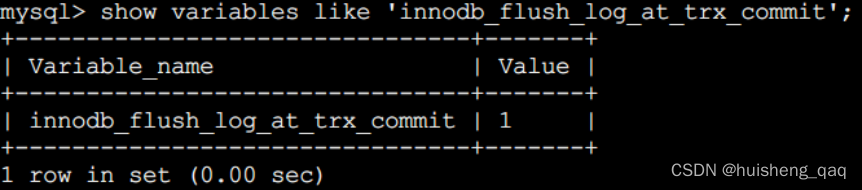
2.5,innodb_flush_log_at_trx_commit
在数据进行刷盘的时候,数据也不是直接的从redolog缓冲区将数据直接刷到磁盘内部,而是需要调用操作系统,通过操作系统进行一个落盘的操作。在操作系统中,会有一个操作系统的缓冲区,数据会先在缓冲区中存放,然后再通过操作系统的调度将数据进行一个落盘的操作。
这个系统变量的名称就是innodb_flush_log_at_trx_commit,可以提供给外部调用,如kafka,mysql都对这个变量进行了调用。这个变量总共有三个参数,分别是0、1、2,不同的参数代表着不同的含义:
该值为0时,表示在事务提交时不立即向磁盘中同步redo日志,这个任务是交给后台线程做的。
该值为1时,表示在事务提交时需要将redo日志同步到磁盘,可以保证事务的持久性,这个是mysql设置的系统默认值,当事务提交时,会进行一个强制刷盘的操作。
该值为2时,表示在事务提交时需要将redo日志写到操作系统的缓冲区中,但并不需要保证将日志真正的刷新到磁盘。如果数据还在操作系统缓存中突然断电,那么未落盘的数据也会丢失。
3,undolog日志
上面主要了解redolog日志,redolog主要是为了保证这个数据的持久性,ACID中的D就是靠这个redolog来保证的。而接下来要讨论的undolog日志,undolog日志主要是为了保证数据的原子性,在mvcc那篇https://blog.csdn.net/zhenghuishengq/article/details/127889365,中也详细的分析了这个undolog,也详细的描述了undolog日志版本链路和readview结合来保证事务的隔离性,接下来再对这个undolog分析一波。
3.1,undolog回滚的方式
undolog日志中主要是记录被修改或者新增的值的记录,当需要回滚时,则将这个存储undolog的值用来回滚。其回滚情况主要有如下几种:
1,当插入一条记录时,需要把这条记录的主键值记下来,回滚的时候只需要把这个主键值对应的记录删掉。
2,当删除了一条记录,需要要把这条记录中的内容都记下来,回滚时再把由这些内容组成的记录插入到表中。
3,当修改了一条记录,需要要把修改这条记录前的旧值都记录下来,回滚时再把这条记录更新为旧值。
3.2,undolog事务id形成机制
在mysql中,主要有只读事务和读写事务。在只读事务中,普通的表是不能进行增删改操作的,而临时的表是可以进行增删改的;而读写事务中,是都可以进行增删改操作的。同时在只读事务中,由于临时表可以进行增删改,因此只读事务的临时表中也是可以产生这个事务id的。
undolog产生的事务id和这个LSN这个序列号是一样的,也是一个自增的全局变量id,在innodb中,每一行数据都会有一个存储这个事务id的地方,在之前的行格式中也谈到过,这些隐藏聚簇索引id,事务id,回滚指针等都存储在这些行格式,中。如下图中的row_id,trx_id,roll_ptr等

3.3,插入操作
在数据进行插入的操作时,如果此时表中有着二级索引,那么此时除了向主键索引所在的B+树中存放整行数据,还要向二级索引中存放对应的列以及主键id这个字段。如果出现数据回滚的情况,那么不仅要删除主键索引中的数据,也要删除二级索引中对应的数据,但是这个id即存在一级索引中,也存在二级索引中,因此undolog在记录这个插入操作的数据的时候,直接将该行数据的主键id值存放在这个undolog的版本链路中,如果出现回滚的话,是那么直接通过id删除,就能把数据全部回滚回去了。
3.4,删除操作
在数据进行删除时, 会需要用到行格式中的一个delete_mask 字段,这个字段在记录头信息里面,如果该字段为0,则表示没有删除,该字段为1,表示已经删除。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gpDH2s9m-1677138921854)(img/1677040784631.png)]](https://img-blog.csdnimg.cn/97eda21eb8744230bcb57af2d8996b94.png)
在innodb中,为了保证mvcc的多版本并发控制机制,redolog在删除时引入了一个中间状态,即在删除时先引用逻辑删除,将delete_mask这个字段将值变为1,随后在事务提交之后,再通过后台启动一个线程,通过轮询方式去收集这个字段为1的那些行数据,然后再将值给删除。
由于所有的数据都是通过双向链表的方式串在一起,因此在删除的时候,只需要将链表的前驱和后继修改即可,并且会将这个需要删除的数据,挂载这个Page Free页的上面。Page Free页面上的数据表示该空间上面的页面可以被重复利用。
3.5,更新操作
在update方面,就会相对的比新增和删除两种方式更加的麻烦一些,主要分为更新主键和不更新主键。
3.5.1,不更新主键
在不更新主键时,又分为就地更新和物理删除再插入。如果在对某个字段做更新时,其要更新的值的长度不变,那么就会直接选择就地更新,如原来的值为"张三",现在将值改为"李四",改变的值的长度不变,那么就不会影响整页数据的结构,其选择就地更新;如果更新值的长度和原来的长度不一样,如原来是一个"张三",现在变成了"张三丰",他的值很明显不一样,那么就会选择先删除旧记录,再插入新的记录。换句话说,就是看空间大小是否发生改变,不变则就地更新,变则先删除后插入。
3.5.2,更新主键
更新主键操作和删除操作有点类似,为了保证mvcc机制,也是通过记录头信息中的delete mask字段来作为一个中间状态,即将这个字段的值改为1,然后再事务提交之后再将这条数据删除。删除之后再新增一条数据,根据新的主键值在B+树中找到新的定位,然后将数据新增到此地。就是更新主键可以看成是两步操作,先delete操作,再insert操作,因此在更新主键时,就会产生两条undo日志。
4,事务的整体执行流程
通过上面的redolog和undolog的可知,redolog是为了保证事务的持久性,他具有重做的功能,undolog是为了保证事务的原子性,他具有撤回的功能。因此在开启一个事务时,可以总结一下各个日志中的作用已经整个事务的执行流程。
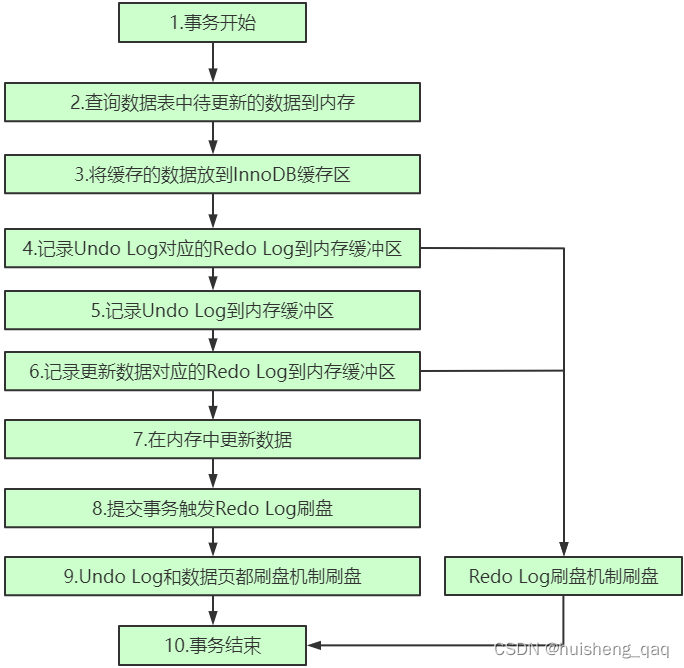
1,以一个更新语句为例,在开启事务之后,会将磁盘中要更新的数据以页的方式加载到buffer pool缓冲区中
2,在执行更新语句时,会通过undolog记录被修改的值。在innodb中,为了保证undolog日志本身的持久性,因此也会通过一个redolog日志来记录里面新增的记录,如undolog的版本控制链路新增一个结点时,redolog就会记录在这条链表的什么位置加入了哪个结点,记录完之后将记录加入到Redolog的缓冲区中,再通过一定的方式进行刷盘持久化,所以在整个事务的过程中,redolog比undolog先刷盘。随后将要改变的值加入到buffer pool中
3,在buffer pool中执行sql的更新,将要更新逻辑语句也加入到Redolog缓冲区中,此时也会有一个redolog刷盘操作。
4, 在提交事务时,也会让对应的redolog日志记录进行一个刷盘操作。
5,随后undolog会进行刷盘操作,buffer pool中的数据也会通过后台的线程进行一个数据刷盘的操作。
6,在undolog日志和redolog日志,数据页全部刷盘完成之后,事务执行完毕。
5,redolog和binlog的关系
从下图来看,redolog是属于引擎层的,即属于innodb存储引擎特有的,而binlog是属于server层的,即所有的引擎层共有,innodb有,MyIsam也有。从整个流程来看,binlog和redolog都是对一份数据进行的存储,并且在存储过程中,需要通过事务标记来保证两个日志中记录的值一样。
5.1,为什么用redolog恢复数据而不用binlog
1,binlog 会记录表中所有更改操作,包括更新删除数据,更改表结构等等,主要用于人工恢复数据,如开了binlog删库也不用跑路;而redolog主要是mysql内部使用的,在数据库突然崩溃mysql内部会自动的通过这个redolog进行一个重做的操作。
2,redolog是Innodb引擎层特有的,binlog是Server层实现的
3,redolog记录的是物理日志,如在哪一页哪一行哪个字段做了什么修改,其效率更高;binlog就是原始的逻辑,和原来的sql差不多
4,redolog默认大小为48M,其内存是有限的,因此其内部是通过循环写的方式去保存数据,并且其内部只记录为刷盘的数据,已刷盘的数据会自动的从这个redolog中删除;binlog采用的是追加写,所有的记录都会保存。而在恢复数据的时候只需要恢复这部分未刷盘的即可,不需要全部就行一个对比再操作。
5,如果再一个事务中出现两条相同的sql,如set age = age + 1 where id = 2,如果binlog一条刷盘成功一条刷盘失败,那么他是不能区分这两条是有没有全部刷盘成功或者失败的,换句话说就是由于已经有一条成功了,那么就不能保证是第一条成功了还是第二条成功了,因此不管是全部恢复还是全部不恢复,内部的数据肯定不对;而redolog就不一样了,只需要把redolog内部未刷盘的进行一个刷盘操作就好了。
5.2,binlog和redolog如何保证数据的一致性
mysql中主要使用2pc,两阶段提交来保证数据的一致性。第一阶段就是先做一个准备工作,开启一个事务提交器,让所有的资源准备好,然后会去收集所有的资源状态,当所有资源的状态都准备好了之后,再进入第二阶段,发出一个commit的命令,所有的资源进行一个commit提交。