1、IDEA安装scala插件
2、下载scala sdk

3、配置scala环境变脸

4、在IDEA中的 Project Structure 的 Global Libraries 中添加 scala sdk
5、在pom文件添加依赖(注意这里3.0.0版本,因为我hadoop是3.0.0版本,必须保持一致)
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
6、安装hadoop(我装的3.2.2的,随意,后面会把bin替换了)

7、配置hadoop环境变量
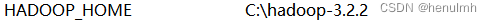
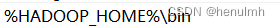
8、hadoop在windows上不能直接用,下载winutils

9、用winutils中某一版本的bin(我用的3.0.0)替换掉刚才下载的3.2.2版本的hadoop的bin
10、修改 C:\hadoop-3.2.2\etc\hadoop\hadoop-env.cmd

11、将 C:\hadoop-3.2.2\bin 中的 hadoop.dll 文件copy一份到 C:\Windows\System32中
12、可以运行了
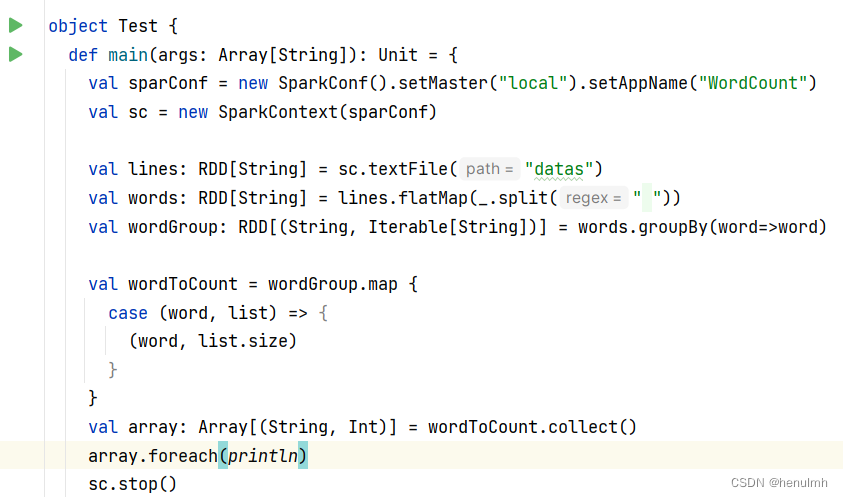
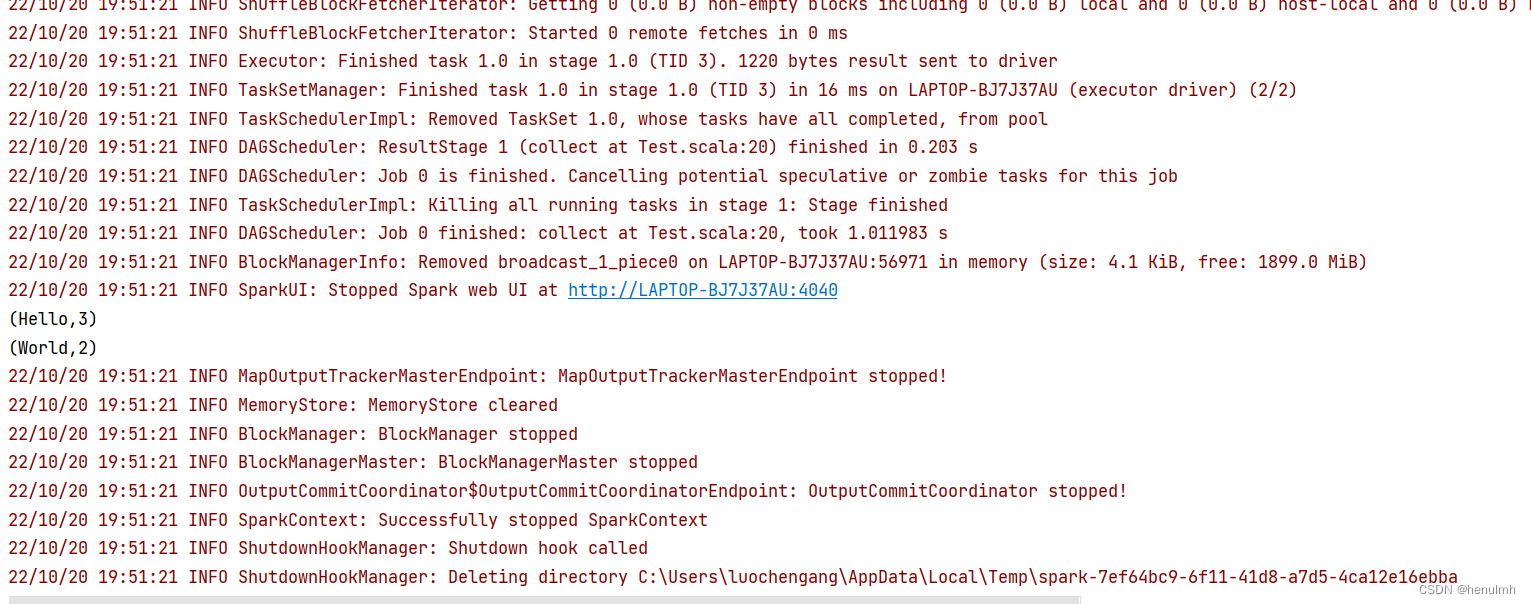
注意:spark 版本 必须与 hadoop 版本一致,也就是3.0.0