想在leetcode上刷sql来着,结果发现绝大部分需要会员。。不能白嫖实在不能忍,所以找了一会发现牛客也有sql题目可以用来练手。话不多说直接上题。
目录
1.获取所有部门中当前员工薪水最高的相关信息(对应SQL12)
有一个员工表dept_emp简况如下:
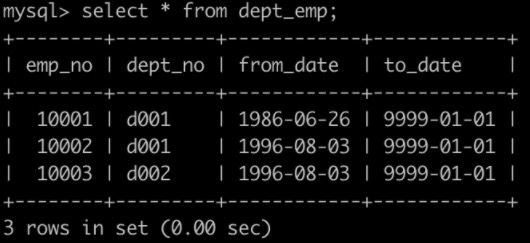
有一个薪水表salaries简况如下:
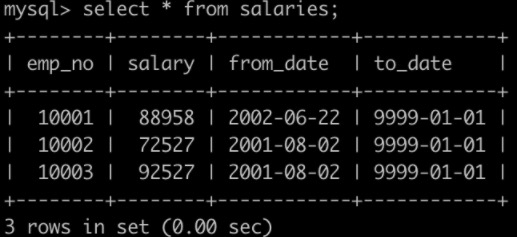
要求:
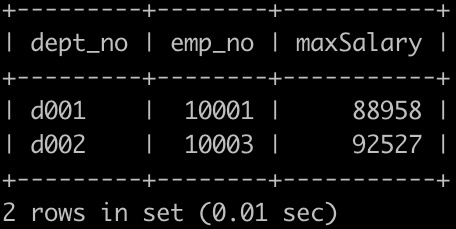
获取所有部门中员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary,按照部门编号升序排列,以上例子输出如下:
解答:
# 首先看需求 1.所有部门员工:两表join
# 2.薪水最高:窗口函数(这里题目中没明确说两个最高薪水一样的情况怎么办,我们先默认都取出来用dense_rank提交结果看看)然后sql如下
select
dept_no, emp_no,salary maxSalary
from
# 先各部门分组,部门内员工薪水降序排序
(select a.dept_no,a.emp_no,salary,
dense_rank() over(partition by dept_no order by salary desc) rn
from dept_emp a join salaries b
on a.emp_no = b.emp_no) c
where rn = 1
order by dept_no
2. 查找所有员工自入职以来的薪水涨幅情况(对应sql21)
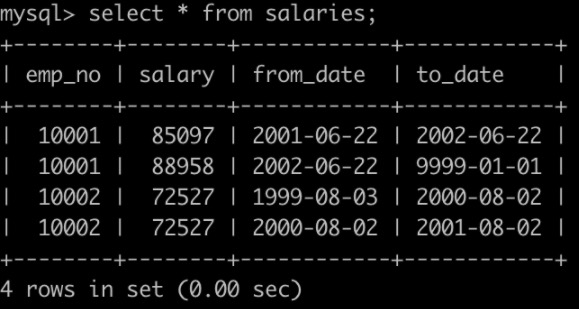
有一个员工表employees简况如下:
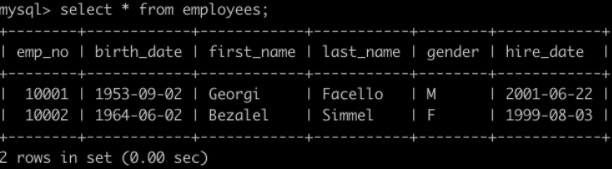
有一个薪水表salaries简况如下:
要求:
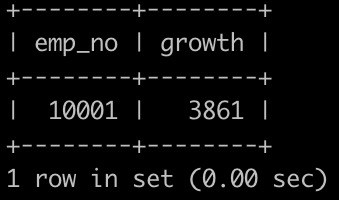
请你查找所有员工自入职以来的薪水涨幅情况,给出员工编号emp_no以及其对应的薪水涨幅growth,并按照growth进行升序,以上例子输出为
(注:可能有employees表和salaries表里存在记录的员工,有对应的员工编号和涨薪记录,但是已经离职了,离职的员工salaries表的最新的to_date!=‘9999-01-01’,这样的数据不显示在查找结果里面,以上emp_no为2的就是这样的)
解答:
1.先将员工入职日期整合到薪资表中,查询对应入职薪资,这里做了一个flag标记,flag=1表明这条记录的薪资是入职薪资
select a.* ,b.hire_date ,
case when a.from_date = b.hire_date
then 1 else 0 end flag
from salaries a join employees b on a.emp_no = b.emp_no

2.去除离职员工,整合当前薪资
select a.* ,b.hire_date ,c.salary,
case when a.from_date = b.hire_date
then 1 else 0 end flag
from salaries a
join employees b on a.emp_no = b.emp_no
join (select emp_no,salary from salaries where to_date = '9999-01-01') c
on a.emp_no = c.emp_no
得到如下结果:

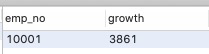
3.取flag=1的当前薪资salary(2) -入职薪资salary 取名growth 然后growth升序,得到最终结果
# 最终sql如下:
select emp_no, growth from
(select a.emp_no,b.hire_date,c.salary-a.salary growth,
case when a.from_date = b.hire_date then 1 else 0 end flag
from salaries a join employees b
on a.emp_no = b.emp_no
join (select emp_no,salary from salaries where to_date = '9999-01-01') c
on a.emp_no = c.emp_no) d
where d.flag=1
order by growth
3.获取员工其当前的薪水比其manager当前薪水还高的相关信息(对应sql25)
有一个,部门关系表dept_emp简况如下:
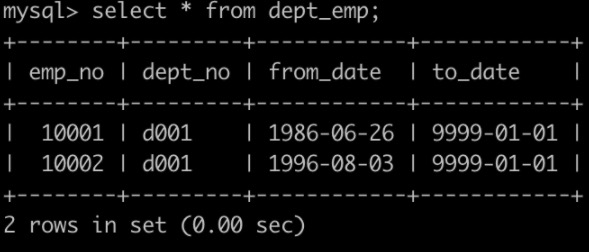
有一个部门经理表dept_manager简况如下:
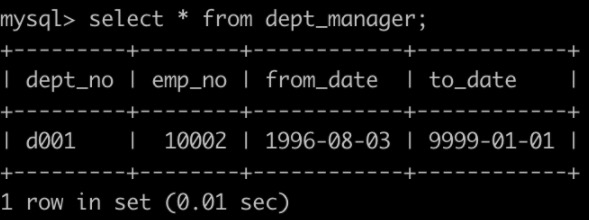
有一个薪水表salaries简况如下:
要求:
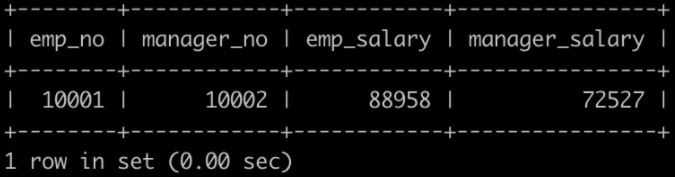
获取员工其当前的薪水比其manager当前薪水还高的相关信息,
第一列给出员工的emp_no,
第二列给出其manager的manager_no,
第三列给出该员工当前的薪水emp_salary,
第四列给该员工对应的manager当前的薪水manager_salary
以上例子输出如下:
解答:
select d.emp_no,d.manager_no,d.salary emp_salary,e.salary manager_salary
from
(select a.emp_no,a.salary,b.dept_no,c.emp_no manager_no
from salaries a
join dept_emp b on a.emp_no = b.emp_no
join dept_manager c on b.dept_no = c.dept_no) d
join salaries e on d.manager_no = e.emp_no
where e.salary<d.salary
4. 汇总各个部门当前员工的title类型的分配数目(对应sql26)
有一个部门表departments简况如下:
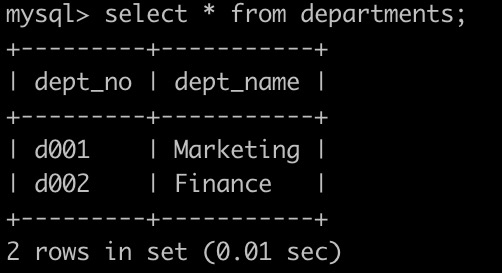
有一个,部门员工关系表dept_emp简况如下:
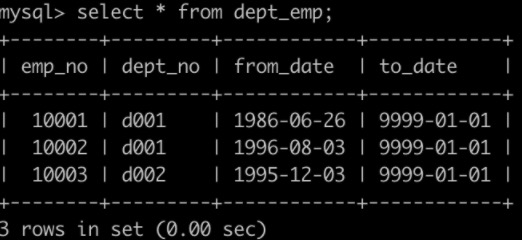
有一个职称表titles简况如下:

要求:
汇总各个部门当前员工的title类型的分配数目,即结果给出部门编号dept_no、dept_name、其部门下所有的员工的title以及该类型title对应的数目count,结果按照dept_no升序排序
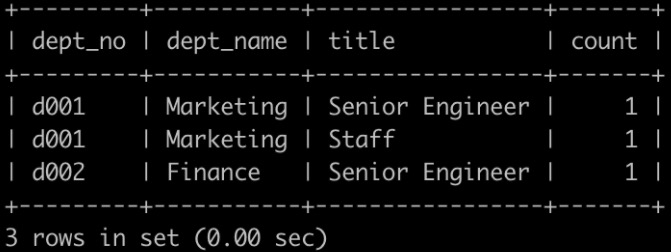
解答:
select dept_no,dept_name,title,count(emp_no) count from
(select a.emp_no,a.dept_no,b.dept_name,c.title
from dept_emp a
join departments b on a.dept_no = b.dept_no
join titles c on a.emp_no = c.emp_no) d
group by dept_no,dept_name,title
order by dept_no
5.牛客每个人最近的登录日期(五)(对应sql70)
牛客每天有很多人登录,请你统计一下牛客每个日期新用户的次日留存率。有一个登录(login)记录表,简况如下:
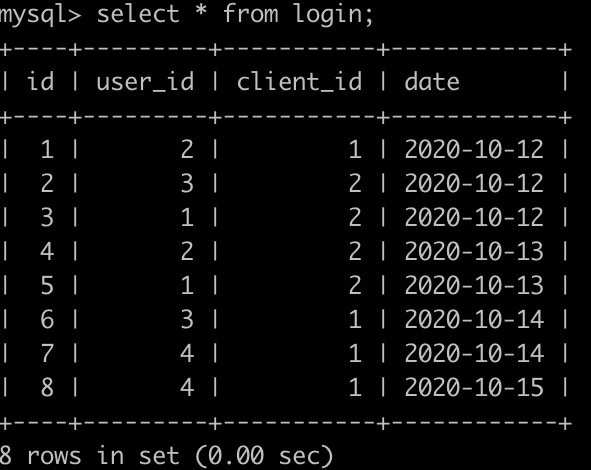
第1行表示user_id为2的用户在2020-10-12使用了客户端id为1的设备登录了牛客网,因为是第1次登录,所以是新用户。。。
第4行表示user_id为2的用户在2020-10-13使用了客户端id为2的设备登录了牛客网,因为是第2次登录,所以是老用户。。
最后1行表示user_id为4的用户在2020-10-15使用了客户端id为1的设备登录了牛客网,因为是第2次登录,所以是老用户
要求:
请你写出一个sql语句查询每个日期新用户的次日留存率,结果保留小数点后面3位数(3位之后的四舍五入),并且查询结果按照日期升序排序,上面的例子查询结果如下:
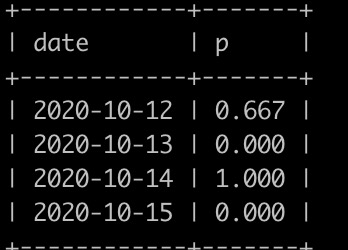
查询结果表明:
2020-10-12登录了3个(user_id为2,3,1)新用户,2020-10-13,只有2个(id为2,1)登录,故2020-10-12新用户次日留存率为2/3=0.667;
2020-10-13没有新用户登录,输出0.000;
2020-10-14登录了1个(user_id为4)新用户,2020-10-15,user_id为4的用户登录,故2020-10-14新用户次日留存率为1/1=1.000;
2020-10-15没有新用户登录,输出0.000;
(注意:sqlite里查找某一天的后一天的用法是:date(yyyy-mm-dd, ‘+1 day’),sqlite里1/2得到的不是0.5,得到的是0,只有1*1.0/2才会得到0.5)
解答:
# 经典次日留存问题可以说数据分析岗必问
# 1.先查询首次登陆用户
select user_id,min(date) date from login group by user_id
# 2.查询第二天登陆的新用户
select
a.user_id, b.user_id, a.date
from
(select user_id, min(date) as date from login group by user_id) a
left join
login b
on
a.user_id = b.user_id and b.date = date_add(a.date, interval 1 day)
# 3.并上当天没有新用户登录的日期
select distinct(date) , '0.000' from login
where date not in (select min(date) from login group by user_id;
所以最终sql如下:
select a.date,round(count(b.user_id)/count(a.user_id),3) p
from
(select user_id,min(date) date from login group by user_id) a
left join login b
on a.user_id = b.user_id
and date_add(a.date,interval 1 day) = b.date
group by a.date
union all
select distinct date,'0.000' p
from
login
where
date not in (select min(date) from login group by user_id)
order by date
6.考试分数(五)(对应sql76)
牛客每次考试完,都会有一个成绩表(grade),如下:

第1行表示用户id为1的用户选择了C++岗位并且考了11001分。。。
第8行表示用户id为8的用户选择了B语言岗位并且考了9999分
要求:
请你写一个sql语句查询各个岗位分数的中位数位置上的所有grade信息,并且按id升序排序,结果如下:
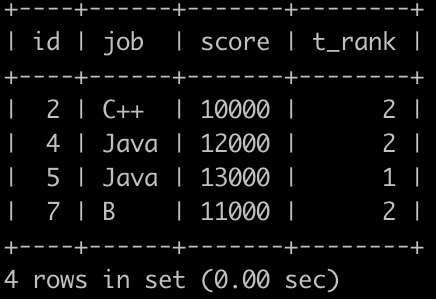
解释:
第1行表示C++岗位的中位数位置上的为用户id为2,分数为10000,在C++岗位里面排名是第2
第2,3行表示Java岗位的中位数位置上的为用户id为4,5,分数为12000,13000,在Java岗位里面排名是第2,1
第4行表示B语言岗位的中位数位置上的为用户id为7,分数为11000,在前端岗位里面排名是第2
解答:
# 分析:此题需求是取中位数的信息,如果总数是偶数则中间两条都取,如果总数是奇数,则取中位数那一条,所以不难想到两种情况下中位数跟总数的关系:
# 序号 总数(总数+1)/2 序号 总数(总数+1)/2
# 1 | 4 | 2.5 1 | 3 | 2
# 2 | 4 | 2.5 2 | 3 | 2
# 3 | 4 | 2.5 3 | 3 | 2
# 4 | 4 | 2.5
# 所以只需判断(总数+1)/2与序号相减的绝对值是否小于1就好了,sql如下:
select id,job,score,t_rank from
(select id,job,score,
row_number() over(partition by job order by score desc) t_rank,
count(score) over(partition by job) cn
from grade) a
where abs((cn+1)/2-t_rank) < 1
order by id
7.牛客的课程订单分析(对应sql81)
有很多同学在牛客购买课程来学习,购买会产生订单存到数据库里。有一个订单信息表(order_info),简况如下:
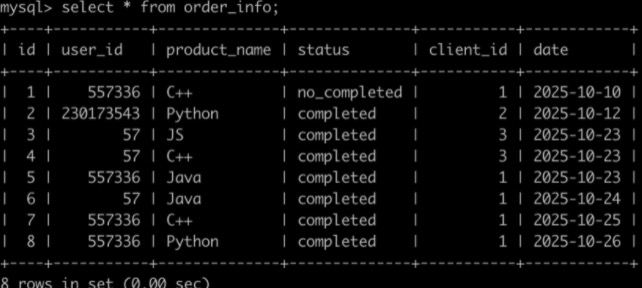
第1行表示user_id为557336的用户在2025-10-10的时候使用了client_id为1的客户端下了C++课程的订单,但是状态为没有购买成功。
要求:
查询在2025-10-15以后,如果有一个用户下单2个及以上状态为购买成功的C++或Java或Python课程,那么输出这个用户的user_id,以及满足前面条件的第一次购买成功的C++或Java或Python课程的日期first_buy_date,以及满足前面条件的第二次购买成功的C++或Java或Python课程的日期second_buy_date,以及购买成功的C++或Java或Python课程的次数cnt,并且结果按照user_id升序排序,以上例子查询结果如下:
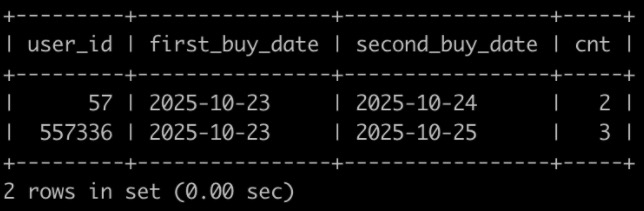
解析:
id为4,6的订单满足以上条件,输出57,id为4的订单为第一次购买成功,输出first_buy_date为2025-10-23,id为6的订单为第二次购买,输出second_buy_date为2025-10-24,总共成功购买了2次;
id为5,7,8的订单满足以上条件,输出557336,id为5的订单为第一次购买成功,输出first_buy_date为2025-10-23,id为7的订单为第二次购买,输出second_buy_date为2025-10-25,总共成功购买了3次
解答:
# 看似复杂实则简单,只需先查到第一次购买课程的日期跟总共购买课程的数量在join第二次购买日期表组合就ok了。
# 第一次购买直接求min(日期)的信息,第二次购买用窗口函数row_number() 排序取第二。
select a.user_id,first_buy_date,second_buy_date,cnt from
(select user_id,min(date) first_buy_date,count(product_name) cnt from order_info
where date>'2025-10-15' and status = 'completed' and product_name in ('C++','Java','Python')
group by user_id
having cnt>=2) a
left join
(select user_id,date second_buy_date from
(select user_id,date,row_number() over(partition by user_id order by date) rn from order_info
where date>'2025-10-15' and status = 'completed' and product_name in ('C++','Java','Python')) c
where rn = 2)b
on a.user_id = b.user_id
order by user_id
8. 实习广场投递简历分析(三)(对应sql86)
在牛客实习广场有很多公司开放职位给同学们投递,同学投递完就会把简历信息存到数据库里。现在有简历信息表(resume_info),部分信息简况如下:
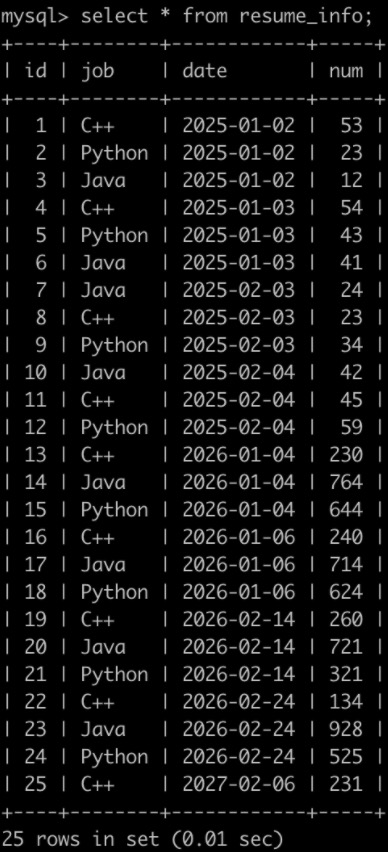
第1行表示,在2025年1月2号,C++岗位收到了53封简历。。。
最后1行表示,在2027年2月6号,C++岗位收到了231封简历
要求:
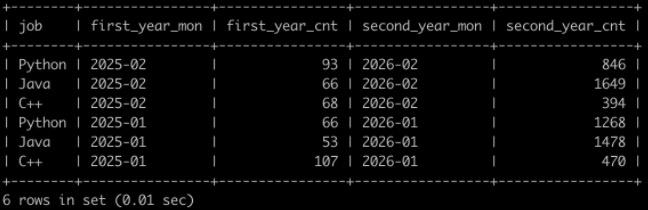
请你写出SQL语句查询在2025年投递简历的每个岗位,每一个月内收到简历的数目,和对应的2026年的同一个月同岗位,收到简历的数目,最后的结果先按first_year_mon月份降序,再按job降序排序显示,以上例子查询结果如下:
解析:
第1行表示Python岗位在2025年2月收到了93份简历,在对应的2026年2月收到了846份简历。。。
最后1行表示C++岗位在2025年1月收到了107份简历,在对应的2026年1月收到了470份简历
解答:
# 本题主要考察字符串截取函数,当然也可以用date_format函数进行日期格式化
select a.job,first_year_mon,first_year_cnt,second_year_mon,second_year_cnt from
(select job,left(date,7) first_year_mon,sum(num) first_year_cnt from resume_info
where left(date,4)='2025' group by left(date,7),job) a
left join
(select job,left(date,7) second_year_mon,sum(num) second_year_cnt from resume_info
where left(date,4)='2026' group by left(date,7),job) b
on a.job = b.job and right(a.first_year_mon,2) = right(b.second_year_mon,2)
order by first_year_mon desc ,job desc
9. 获得积分最多的人(三)(对应sql91)
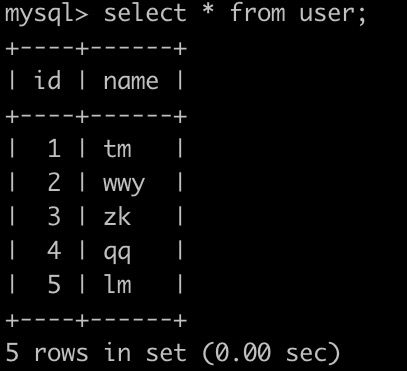
牛客每天有很多用户刷题,发帖,点赞,点踩等等,这些都会记录相应的积分。有一个用户表(user),简况如下:
还有一个积分表(grade_info),简况如下:
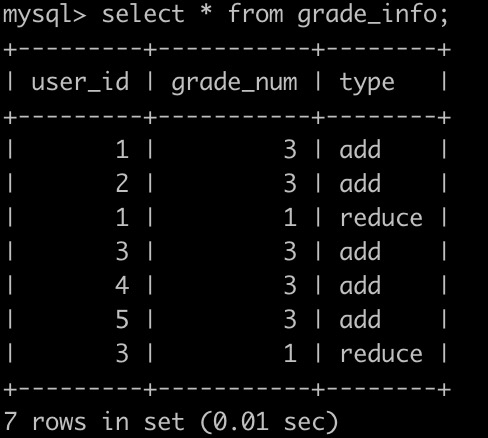
第1行表示,user_id为1的用户积分增加了3分。
第2行表示,user_id为2的用户积分增加了3分。
第3行表示,user_id为1的用户积分减少了1分。
最后1行表示,user_id为3的用户积分减少了1分。
要求:
请你写一个SQL查找积分增加最高的用户的id,名字,以及他的总积分是多少(可能有多个),查询结果按照id升序排序,以上例子查询结果如下:
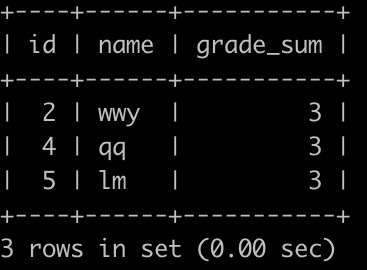
解释:user_id为1和3的先加了3分,但是后面又减了1分,他们2个是2分,其他3个都是3分,所以输出其他三个的数据
解答:
select id,name,grade_sum
from(select *,dense_rank() over(order by grade_sum desc) rn
from(select id,name, sum(case when type = 'add' then grade_num
when type = 'reduce' then -grade_num end) grade_sum
from user a join grade_info b on a.id = b.user_id
group by id,name) a
) b
where rn = 1
order by id