1、查询数据
基本知识
单表查询
单表查询数据(当查询的数据字段,从单张表即可获取时,使用)
具体的mysql语句总结如下
SELECT (DISTINCT)字段1,字段2,...
FROM 表名
WHERE 条件
GROUP BY 字段
HAVING
ORDER BY 字段 DESC
LIMIT START,COUNT
WHERE条件可以是=!=< > <= >= BETWEEN IS NULL AND OR IN等条件- 可以使用
通配符模糊匹配 like- GROUP 根据所给字段建立分组,
是在WHERE过滤完整张表的数据之后进行分组- Having在数据分组后进行过滤
ORDER BY字段默认升序排序,可以显示的加asc;若为降序则必须加DESClimit中START为检索数据行开始的位置(默认为0开始),COUNT为从START位置开始的检索数据的数量
limit 5;默认为从第一行(0)数据开始检索,检索5行
*limit 3,4则检索从4-8行的数据
多张表联结查询
当查询的字段分散在多张表时,需要联结多张表进行查询;联结查询有
两种方式,必须指明联结条件,否则利用的是全连接;
下面为
内连接(基本的链表查询,只有当匹配到数据的时候,才会进行数据的显示)
//方式1:使用 from 表1,表2 where。。。。。这种方式
SELECT 字段 from 表1,表2 ,。。。。
where 条件
group by 字段
order by 字段
limit
//方式2:使用 表1 inner join 表2 on 条件1 and 条件2
SELECT 字段
FROM 表1
JOIN 表2
ON
条件1
AND
条件2
在join 表2之后,可以使用where 或者 on
where在表联立结束之后进行筛选on在表联立的时候进行筛选有时二者可以混合使用,也可以代替使用但有时不可代替
多张表可以连理
SELECT 字段
FROM 表1
JOIN 表2
ON
条件1
AND
条件2
Join 表3
ON
条件1
And
条件2
Group by
注意多张表连理,group by语句则放在sql语句的最后
========
下面为外连接(
根据条件会把表中没有匹配到数据行的数据也会显示)
- 可以用来匹配没有的数据(利用这个特性可以解决一定的问题)
SELECT 字段
FROM 表1
LEFT JOIN 表2
ON
条件1
AND
条件2
=============
1. 查找最晚入职员工的所有信息
关键字提取 :
最:
- 可以使用
max,min等函数,这里需要使用子查询或者自连接的方式- 可以进行
排序,然后根据limit进行限制
所有信息:
- 可以使用
*
//方式1:
select * from employees
order by hire_date desc
limit 1;
//方式2:使用函数max(子查询)
select * from employees
WHERE
hire_date =
(select max(hire_date) from employees);
2、查找入职员工时间排名倒数第三的员工所有信息
关键字:
倒数第三同第一题一样,先排序,然后限制排序的结果
select * from employees
order by hire_date
desc limit 2,1;
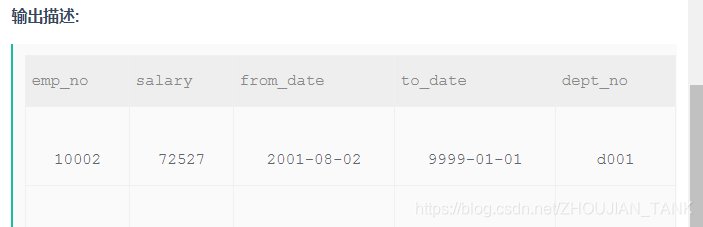
3、查找各个部门当前(to_date=‘9999-01-01’)领导当前薪水详情以及其对应部门编号dept_no
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
分析:
- 根据查询出来的字段信息,
显然需要连理两张表进行查询- 查询的字段主要分布在
Slary表中,- `既然有连理的表了,那么就需要思考连理的条件
- to_date=‘9999-01-01’;两张表中都有
to_date字段- 两个表中的
emp_no要等值
//连理方式1
select s.*,m.dept_no
from salaries as s
join dept_manager as m
on s.emp_no=m.emp_no
and m.to_date='9999-01-01'
and s.to_date='9999-01-01';
//联立方式2:
select s.*,m.dept_no
from salaries as s
,dept_manager as m
where s.emp_no=m.emp_no
and m.to_date='9999-01-01'
and s.to_date='9999-01-01';
4、查找所有已经分配部门的员工的last_name和first_name以及dept_no
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
分析:
- 查询的字段分散在两张表中,因此需要
联结查询- 联结查询的条件为
*表dept_emp的emp_no字段与表employees中的emp_no字段相等
SELECT
e.last_name,
e.first_name,
d.dept_no
FROM
dept_emp AS d
JOIN
employees AS e
ON
e.emp_no = d.emp_no;
5、查所有员工的last_name和first_name以及对应部门编号dept_no,也包括展示没有分配具体部门的员工
注意与上提的区别是
- 上提匹配分配岗位的员工(没有分配不匹配)
- 此题匹配所有员工(
无论有没有分配岗位)
因此采用外连接
select e.last_name,e.first_name,d.dept_no
from employees AS e
left join dept_emp AS d
on
e.emp_no=d.emp_no;
6、查找所有员工入职时候的薪水情况,给出emp_no以及salary, 并按照emp_no进行逆序
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
分析:
- 由于测试数据中,
salaries.emp_no不唯一(因为号码为 emp_no 的员***有多次涨薪的可能,所以在 salaries 中对应的记录不止一条),employees.emp_no 唯一,即 salaries 的数据会多于 employees,因此需先找到 employees.emp_no 在 salaries 表中对应的记录salaries.emp_no,则有限制条件 e.emp_no = s.emp_no- 关键是如何确定
入职时候
- 在
employees有hire_date,表明员工的入职信息;在sakaries中有from_date表明这份薪资的开始日期,连理这两个即可确定入职日期按照emp_no逆序
select e.emp_no ,s.salary from employees as e
salaries
join s
on e.emp_no=s.emp_no
AND
e.hire_date = s.from_date
order by
e.emp_no desc;
2020/3/16
7、查找薪水涨幅超过15次的员工号emp_no以及其对应的涨幅次数t
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));```
分析:
超过15次可以利用分组
where去除行记录
having在分组之后进行过滤,往往过滤的条件都是聚合函数max,avg,min,sum等函数
select
emp_no,
count(emp_no)
from salaries
group by emp_no
having
count(emp_no)>15;
8、找出所有员工当前(to_date=‘9999-01-01’)具体的薪水salary情况,对于相同的薪水只显示一次,并按照逆序显示
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
输入描述:
分析
单表查询
条件
- 员工当前(to_date=‘9999-01-01’)
- 对于相同的薪水
只显示一次去重去重两种方式
- 使用
distinct- 使用
group by
**当数据量比价大的时候使用group by
select
DISTINCT salary
from salaries
where to_date='9999-01-01'
order by salary desc
;
/** 方式2:使用group by方式**/
select salary
from salaries
where to_date='9999-01-01'
group by salary
order by salary desc;
9、获取所有部门当前manager的当前薪水情况,给出dept_no, emp_no以及salary,当前表示to_date=‘9999-01-01’
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
分析
两表联立
在多表查询的时候,要注意条件的选取
- join on xxxx :这种是表联立之前进行过滤。
- join 表2 where :where是在表联立之后进行过滤
有时候这两种方式可以代替,但有时不可以
select
d.dept_no,
d.emp_no,
s.salary
from dept_manager d
join salaries s
on(where) d.to_date='9999-01-01'/*这里的where和on均可以*/
and s.to_date='9999-01-01'
and d.emp_no=s.emp_no
;
10、获取所有非manager的员工emp_no
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
分析:
关键字眼:非
条件:非
z在employees表中存放了所有员工的信息,在dept_manager中存放了所有管理着的信息。为了查询employees中非管理着的信息,可以先找到employees中管理者的信息,然后取反
- 可以使用
子查询的方式,先找到管理者的信息,然后从employees表中剔除- 可以使用
联立表的方式,使用左连接,然后字段中有null值的就是员工
/*方式1:使用子查询 */
select
emp_no
from
employees
where
emp_no not in
(select emp_no from dept_manager);
/*
方式2:使用连接查询
先使用LEFT JOIN连接两张表,再从表中选出dept_no为NULL值对应的emp_no
*/
/**
on比where起作用更早,
先根据on条件进行多表的连接操作,
生成一个临时表再通过where来筛选
on是在 表生成之前先进行过滤
where是在表生成之后再进行过滤
**/
SELECT employees.emp_no
FROM employees
LEFT JOIN dept_manager
ON employees.emp_no = dept_manager.emp_no
/** 这里若加and显然是错误的,and是在生成表之前先进行过滤
where是在表生成之后进行过滤
**/
where dept_no IS NULL
11、获取所有员工当前的manager
获取所有员工当前的manager,如果当前的manager是自己的话结果不显示,当前表示to_date=‘9999-01-01’。
结果第一列给出当前员工的emp_no,第二列给出其manager对应的manager_no。
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
分析
主要是条件的选取
看看题目里的条件是否都用上了
select
e.emp_no,
m.emp_no manager_no
from dept_emp e
join dept_manager m
on
e.dept_no = m.dept_no
and
e.emp_no!=m.emp_no
and
m.to_date='9999-01-01'
and
e.to_date='9999-01-01'
;
12、获取所有部门中当前员工薪水最高的相关信息
获取所有部门中当前员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
select
d.dept_no,
d.emp_no,
max(e.salary) as salary
from
dept_emp d
join salaries e
on
d.emp_no=e.emp_no
where
d.to_date='9999-01-01'
and
e.to_date='9999-01-01'
group by
d.dept_no;
2020/3/17 16:30
13、从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。
CREATE TABLE IF NOT EXISTS "titles" (
`emp_no` int(11) NOT NULL,
`title` varchar(50) NOT NULL,
`from_date` date NOT NULL,
`to_date` date DEFAULT NULL);
这涉及到
分组查询
注意having与where的区别
select
title,count(title) t
from titles
group by title
having t>=2;
14、从titles表获取按照title进行分组,注意对于重复的emp_no进行忽略
分析:
核心:忽略重复emp_no(就是去重的意思)
select title ,count(distinct emp_no)as n
from titles
group by title
having n>=2;
15、查找employees表
查找employees表所有
emp_no为奇数,且last_name不为Mary的员工信息,并按照hire_date逆序排列
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
分析:
条件
输出:逆序
主要就是条件判断
*/
select *
from employees
where emp_no%2=1
and last_name!='Mary'
order by hire_date desc;
16、统计出当前各个title类型对应的员工当前薪水对应的平均工资
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
CREATE TABLE IF NOT EXISTS "titles" (
`emp_no` int(11) NOT NULL,
`title` varchar(50) NOT NULL,
`from_date` date NOT NULL,
`to_date` date DEFAULT NULL);
分析:
各个:需要进行分组
平均:使用函数
select
title,
avg(salary)
from salaries s
join titles t
on s.emp_no=t.emp_no
and s.to_date='9999-01-01'
and t.to_date = '9999-01-01'
group by title;
17、获取当前(to_date=‘9999-01-01’)薪水第二多的员工的emp_no以及其对应的薪水salary
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
方式1:使用
order by然后进行limit即可获取最x值
select
emp_no,salary
from salaries
where to_date='9999-01-01'
order by salary desc
limit 1,1;
方式2:先排除最大的一个值,然后取次大的值,这种方式存在问题,要是取第三大的呢?
select
e.emp_no,max(salary) salary ,last_name,first_name
from employees e
inner join salaries s
on e.emp_no=s.emp_no
and to_date='9999-01-01'
and salary not in
(select max(salary) from salaries where to_date='9999-01-01');
方式3:
**对salary表进行自连接,确定在其表中 小于每行记录的记录有多少,然后可依据要求结果进行过滤,分组之后,看没组之中对应的记录数,即可确定;这种方式比较好,推荐
select e.emp_no,s3.salary,e.last_name,e.first_name
from employees e
inner join(
/*先进行自连接*/
select s1.emp_no,s1.salary
from salaries s1
inner join salaries s2
on s1.salary < s2.salary
where s1.to_date = '9999-01-01' and s2.to_date = '9999-01-01'
group by s1.emp_no
having count(*) = 1
) s3
on e.emp_no = s3.emp_no;
2020/3/18 14:40
18、查看所有员工的last_name和first_name以及对应的dept_name
CREATE TABLE `departments` (
`dept_no` char(4) NOT NULL,
`dept_name` varchar(40) NOT NULL,
PRIMARY KEY (`dept_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
设计到三张表,这时就需要联立三张表进行筛选,过滤
SELECT
e.last_name,e.first_name,d.dept_name
FROM employees e
left join
dept_emp de
on
e.emp_no=de.emp_no
left join
departments d
on
de.dept_no=d.dept_no;
19、查找员工编号emp_no为10001其自入职以来的薪水salary涨幅值growth
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
分析:
单表查询
条件
- 编号为10001
select
max(salary)-min(salary) growth
from salaries
where emp_no=10001;
20、查找所有员工自入职以来的薪水涨幅情况
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
分析:
所有员工,现在与入职工资的差异
SELECT sCurrent.emp_no, (sCurrent.salary-sStart.salary) AS growth
FROM
(SELECT s.emp_no, s.salary FROM employees e, salaries s WHERE e.emp_no = s.emp_no AND s.to_date = '9999-01-01') AS sCurrent,
(SELECT s.emp_no, s.salary FROM employees e, salaries s WHERE e.emp_no = s.emp_no AND s.from_date = e.hire_date) AS sStart
WHERE sCurrent.emp_no = sStart.emp_no
ORDER BY growth
21、统计各个部门的工资记录数,给出部门编码dept_no、部门名称dept_name以及次数sum
CREATE TABLE `departments` (
`dept_no` char(4) NOT NULL,
`dept_name` varchar(40) NOT NULL,
PRIMARY KEY (`dept_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
多表联立时,分组要在联立的最后进行
/*
分组要在最后进行分组
*/
select
de.dept_no,d.dept_name,count(s.salary) as sum
from dept_emp de
join salaries s
on de.emp_no=s.emp_no
join departments d
on d.dept_no=de.dept_no
group by de.dept_no
22、对所有员工的当前(to_date=‘9999-01-01’)薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列
难点在于如何确定排名
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
分析:
主要是在对于排名的理解上,
分成两张表,一张表中该工资的排名其实就是表中大于等于该工资的数目,
由于相同的salary排名相同,所有count中要有distinct ,
由由于每个都要输出,要用group by ,否则应该是只有一条
select
s1.emp_no,
s1.salary,
count(distinct s2.salary)
from salaries s1
join salaries s2
on s1.salary<=s2.salary
and s1.to_date='9999-01-01'
and s2.to_date='9999-01-01'
group by s1.emp_no
order by s1.salary desc,s1.emp_no asc;
