文章目录
1. 预备知识
1.1 问题定义
图像由前景和背景组成,抠图的感兴趣区域是前景(比如人像),目的是将前景和背景分离,用公式表达如下: I i = α i F i + ( 1 − α i ) B i ( 1.1 ) I_i=\alpha_i F_i+(1-\alpha_i)B_i \qquad (1.1) Ii=αiFi+(1−αi)Bi(1.1)其中: i i i表示像素索引, F F F表示前景, B B B表示背景, α \alpha α表示像素属于前景的概率,取值范围为0~1(人像分割任务中的 α \alpha α取值为0或1)
1.2 Trimap(三元图)

(图片来源:论文 Deep Image Matting)
- 三元图是对原始图片的前景、背景和未知区域进行标记的灰度图,前景、背景和未知区域的像素取值分别为255,0,128。三元图通常作为抠图算法的先验知识。
2. 算法总结
这里只对经典或者效果好的AI抠图算法进行总结,根据是否需要先验信息可分为trimap-based,background-based和trimap-free两类,目前的主流是trimap-free算法。
2.1 Trimap-based Algorithms
2.1.1 Deep Image Matting (2017)
Paper:https://arxiv.org/pdf/1703.03872.pdf
Code:https://github.com/foamliu/Deep-Image-Matting-PyTorch
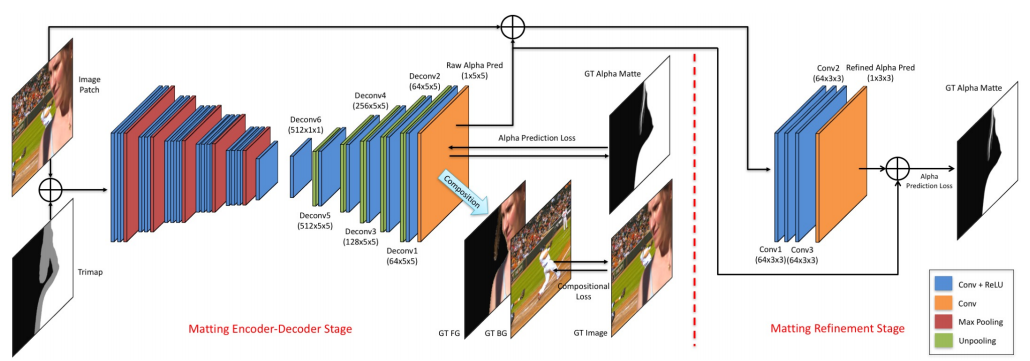
网络包括Encoder-Decoder阶段和Refinement阶段:
-
Encoder-Decoder阶段的输入为RGB图像的patch和对应trimap的concat,所以包含4通道,经过编码和解码后输出单通道的raw alpha pred。该阶段的loss由两部分组成:
第一部分是预测的alpha和真实的alpha之间的绝对误差,考虑到L1 loss在0处不可微,使用Charbonnier Loss去近似: L α i = ( α p i − α g i ) 2 + ϵ 2 ( 2.1.1.1 ) L_{\alpha}^{i}=\sqrt{(\alpha_{p}^{i}-\alpha_g^i)^2+\epsilon^2}\qquad(2.1.1.1) Lαi=(αpi−αgi)2+ϵ2(2.1.1.1)第二部分是由预测的alpha、真实的前景和真实的背景组成的RGB图像与真实的RGB图像之间的绝对误差,其作用是对网络施加式(1.1)的约束,同样使用Charbonnier Loss去近似: L c i = ( c p i − c g i ) 2 + ϵ 2 ( 2.1.1.2 ) L_{c}^{i}=\sqrt{(c_{p}^{i}-c_g^i)^2+\epsilon^2}\qquad(2.1.1.2) Lci=(cpi−cgi)2+ϵ2(2.1.1.2)最终的Loss是两部分的加权求和: L o v e r a l l = w l ⋅ L α + ( 1 − w l ) ⋅ L c ( 2.1.1.3 ) L_{overall}=w_l\cdot L_{\alpha}+(1-w_l)\cdot L_c\qquad(2.1.1.3) Loverall=wl⋅Lα+(1−wl)⋅Lc(2.1.1.3) -
Refinement阶段的输入为Encoder-Decoder阶段输出的raw alpha pred与原始RGB图像的concat,同样为4通道,原始RGB图像能够为refine提供边界细节信息。重点是使用了一个skip connection,将Encoder-Decoder阶段输出的raw alpha pred与Refinement阶段输出的refined alpha pred做一个add操作,然后输出最终的预测结果。其实Refinement阶段就是一个residual block,通过残差学习对边界信息进行建模,与去噪模型对噪声建模如出一辙。
Refinement阶段只有一个loss:refined alpha pred与GT alpha matte计算Charbonnier Loss。 -
分段训练策略:先更新Encoder-decoder部分,再更新refinement部分,最后微调整个网络。
2.2 Background-based Algorithms
2.2.1 Background Matting
Paper: https://arxiv.org/pdf/2012.07810.pdf
code: https://github.com/senguptaumd/Background-Matting
2.2.2 Background Matting v2
Paper: https://arxiv.org/pdf/2012.07810.pdf
code: https://github.com/PeterL1n/BackgroundMattingV2
2.3 Trimap-free Algorithms
2.3.1 Semantic Human Matting
Paper: https://arxiv.org/pdf/1809.01354.pdf
code: https://github.com/lizhengwei1992/Semantic_Human_Matting
2.3.2 MODNet: Trimap-Free Portrait Matting in Real Time
Paper:https://arxiv.org/pdf/2011.11961.pdf
code:https://github.com/ZHKKKe/MODNet
该论文的亮点有3个:
- 不需要辅助输入
- 结构简单,轻量,实时
- 自监督学习
网络结构由①语义估计分支、②细节预测分支和③语义-细节融合分支组成:
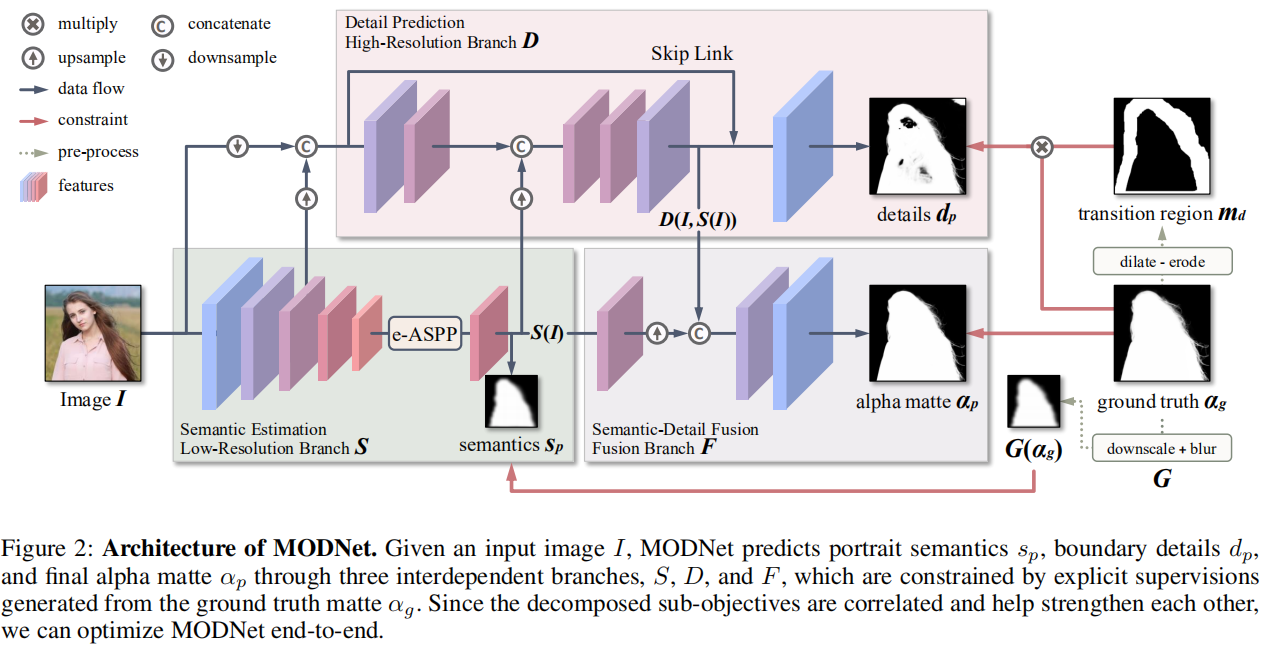
1. 语义估计分支
- 输入为原始的RGB图像,输出为经过encoder和e-ASPP处理后的低分辨率semantic feature map(e-ASPP是为了减小ASPP的计算开销而设计的)。不使用decoder的好处是:① 减小计算量,② high-level的表征 S ( I ) S(I) S(I)可用于其他两个分支,并且有助于优化网络(参与 L S L_S LS的计算)

L S L_S LS的作用是对语义信息做约束,使语义估计分支学习到一个粗略的分割。语义信息的GT是对alpha matte GT进行下采样和模糊而得,模糊的目的是抹去细节。
2. 细节预测分支
- 输入为原始RGB图像和语义估计分支中的low-level features的concat,复用low-level features的目的是减小细节分支的计算开销;另外还引入了high-level的语义信息 S ( I ) S(I) S(I)作为预测细节的先验知识;输出为细节信息;

对细节的约束只需要考虑unkonwn区域,因此 L d L_d Ld中对L1损失乘上了一个unkonwn区域值为1的mask,该mask是通过对alpha matte GT进行膨胀腐蚀生成的。
3. 融合分支
- 融合语义估计和细节预测分支的输出,经过卷积后输出最终的alpha matte。融合分支的约束为 L α : L_\alpha: Lα:

Sub-objectives Consistency (SOC,子目标一致性):三个分支的输出在语义和细节上存在一定的一致性,对此一致性做约束,以自监督的方式进一步优化网络。
- 令 M M M表示MODNet,语义估计分支的输出为 s ~ p \tilde s_p s~p,细节预测分支的输出为 d ~ p \tilde d_p d~p,融合分支的输出为 α ~ p \tilde \alpha_p α~p
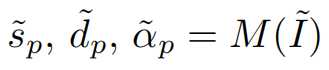
s ~ p \tilde s_p s~p应该与 G ( α ~ p ) G(\tilde \alpha_p) G(α~p)在语义上具有一致性, α ~ p \tilde \alpha_p α~p应该在细节上与 d ~ p \tilde d_p d~p具有一致性,因此可构建如下loss:
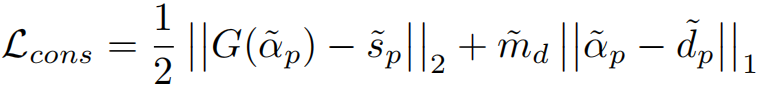
只使用 L s L_s Ls会存在一个问题: s ~ p \tilde s_p s~p与 G ( α ~ p ) G(\tilde \alpha_p) G(α~p)的L2损失会平滑 α ~ p \tilde \alpha_p α~p中的细节,此时 α ~ p \tilde \alpha_p α~p与 d ~ p \tilde d_p d~p的一致性约束会导致细节预测分支所预测的细节信息被移除。
解决方法:复制网络 M M M,副本记为 M ′ M^{\prime} M′,在执行SOC前固定 M ′ M^{\prime} M′的权重,因此 M ′ M^{\prime} M′中细节分支的输出 d ~ p ′ {\tilde d_p}^{\prime} d~p′保留了细节信息,然后对 M M M中的 d ~ p \tilde d_p d~p做如下约束即可:
