线性分类器与非线性分类器的区别以及优劣
如果模型是参数的线性函数,并且存在线性分类面,那么就是线性分类器,否则不是。
常见的线性分类器有:LR,贝叶斯分类,单层感知机、线性回归
常见的非线性分类器:决策树、RF、GBDT、多层感知机
SVM两种都有(看线性核还是高斯核)
- 线性分类器速度快、编程方便,但是可能拟合效果不会很好
- 非线性分类器编程复杂,但是效果拟合能力强
数据挖掘和机器学习的区别
机器学习是数据挖掘的一个重要工具,但是数据挖掘不仅仅只有机器学习这一类方法,还有其他很多非机器学习的方法,比如图挖掘,频繁项挖掘等。感觉数据挖掘是从目的而言的,但是机器学习是从方法而言的。
什么是标准差、方差和协方差?它们反映了数据的什么内容?
方差(Variance):用来度量随机变量和其数学期望(即均值)之间的偏离程度。
标准差:方差开根号。
协方差:E[(X-E[X])(Y-E[Y])]=E[XY]-E[X]E[Y]衡量两个变量之间的变化方向关系。
标准差描述是样本集合的各个样本点到均值的距离分布,描述的是样本集的分散程度
在机器学习中的方差就是估计值与其期望值的统计方差。如果进行多次重复验证的过程,就会发现模型在训练集上的表现并不固定,会出现波动,这些波动越大,它的方差就越大
协方差主要用来度量两个随机变量关系,如果结果为正值,则说明两者是正相关的;结果为负值,说明两者是负相关的;如果为0,就是统计上的“相互独立”
标准差: 描述样本的分散程度。
方差:标准差的平方,模型预测稳定性。
协方差:
结果为正值:两者正相关;
结果为负值:两者负相关;
如果为0:“相互独立”;
生成模型和判别模型
- 生成模型:由数据学习联合概率分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型:P(Y|X)= P(X,Y)/ P(X)。(朴素贝叶斯)
生成模型可以还原联合概率分布p(X,Y),并且有较快的学习收敛速度,还可以用于隐变量的学习 - 判别模型:由数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。(k近邻、决策树)
直接面对预测,往往准确率较高,直接对数据在各种程度上的抽象,所以可以简化模型
监督和非监督的区别和各自优势?
激活函数:
Sigmoid,Tanh,ReLu, Softmax

激活函数 | 深度学习领域最常用的10个激活函数,详解数学原理及优缺点 - 云+社区 - 腾讯云 (tencent.com)
防止过拟合?
如何防止过拟合(overfitting) - 知乎 (zhihu.com)
神经网络防止过拟合的方法 - bonelee - 博客园 (cnblogs.com)
数据增强, early stopping,正则化,Dropout,权值共享,集成方法
核函数?
只要一个对称函数所对应的核矩阵半正定,它就能作为核函数使用。事实上,对于一个半正定核矩阵,总能找到一个与之对应的映射。核函数的使用,不一定能够准确的划分,只能说使用哪个核函数,能够逼近真实的划分效果。因此特征空间的好坏对支持向量机的性能至关重要。在不知道特征映射的形式时,我们并不知道什么样的核函数是合适的,而核函数也仅是隐式定义了这个特征空间。于是,核函数的选择成为了支持向量机的最大变数。若核函数选择不合适,则意味着映射到一个不合适的特征空间,很可能导致性能不佳。 (对预测精度有重要影响。) 特征数量多的时候适合线性核函数,因为运算速度快 当多项式阶数高时复杂度会很高,正交归一化后的数据,优先使用多项式核函数。 大多数情况下径向基核函数(高斯核函数)都有比较好的性能,不确定用哪种就用它。
隐马尔可夫模型
特征降维方法:
主成分分析 PCA 、线性判别分析 LDA 、AutoEncoder、矩阵奇异值分解 SVD
PCA:
通过某种线性投影,将高维度的数据映射到低维的空间中,并期望再所投影的维度上数据的方差最大,以此使用较少的维度,同时保留较多原数据的维度。
LDA:
通过将训练样本投影到低维度上,使得同类别的投影点尽可能接近,异类别样本的投影点尽可能远离,(即同类点方差尽可能小,而类之间的方差尽可能大);对新样本,将其投影到低维空间,根据投影点的位置来确定其类别;
和PCA一样都是常用的降维技术,PCA从特征的协方差角度找比较好的投影,LDA更多是考虑了标注,即希望投影后不同类别之间的数据点的距离更大,同一类别的数据点更紧凑。
L1 (LASSO)和 L2 (Ridge) 的区别?
(所有特征中只有少数特征起重要作用的情况下,选择L1更合适; 所有特征中,大部分特征都能起作用,而且起的作用很平均,选择L2更合适;L1/L2范数让模型变得稀疏,增加模型的可解析性,可用于特征选择;L2范数让模型变得更简单,防止过拟合问题; )

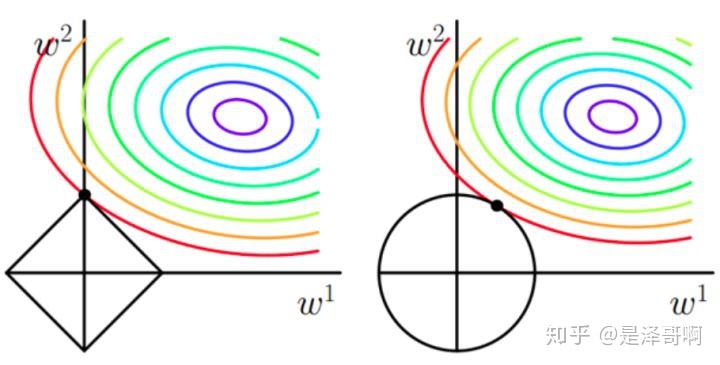
优化:
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法。
梯度下降(Gradient Descent)小结 - 刘建平Pinard - 博客园
梯度下降本身来看的话就有随机梯度下降,批梯度下降,small batch 梯度下降三种方式
分类算法常见的评估指标?
损失函数
损失函数一般有四种,平方损失函数,对数损失函数,HingeLoss0-1损失函数,绝对值损失函数。将极大似然函数取对数以后等同于对数损失函数


机器学习算法实践:
GitHub - Jack-Cherish/Machine-Learning: 机器学习实战(Python3):kNN、决策树、贝叶斯、逻辑回归、SVM、线性回归、树回归

逻辑回归:机器学习系列(1)_逻辑回归初步_寒小阳-CSDN博客_逻辑回归机器学习
(直线划分和曲线划分两个数据集,数据集存储在度盘上,所以要用自己的电脑下载)
决策树:
Python3《机器学习实战》学习笔记(二):决策树基础篇之让我们从相亲说起_Jack-Cui-CSDN博客_python 决策树实战Python3《机器学习实战》学习笔记(三):决策树实战篇之为自己配个隐形眼镜_Jack-Cui-CSDN博客
k近邻
Python3《机器学习实战》学习笔记(一):k-近邻算法(史诗级干货长文)_Jack-Cui-CSDN博客_python3 机器学习实战
朴素贝叶斯