一、基本概念
1.二叉排序树
二叉排序树(Binary sort tree,BST),又称为二叉查找树,或者是一棵空树;或者是具有下列性质的二叉树:
(1)若它的左子树不为空,则左子树上所有节点的值均小于它的根节点的值;
(2)若它的右子树不为空,则右子树上所有节点的值均大于它的根节点的值;
(3)它的左、右子树也分别为二叉排序树。
二、二叉排序树操作
二叉排序树是一种动态树表。它的特点是树的结构不是一次生成的,而是在查找过程中,当树中不存在关键字等于给定值的节点时再进行插入。新插入的节点一定是一个新添加的叶子结点,并且是查找不成功时查找路径上访问的最后一个节点的左孩子或右孩子节点,
二叉排序树的操作有插入、删除、查询和遍历等。
注意:二叉排序树中没有值相同的节点
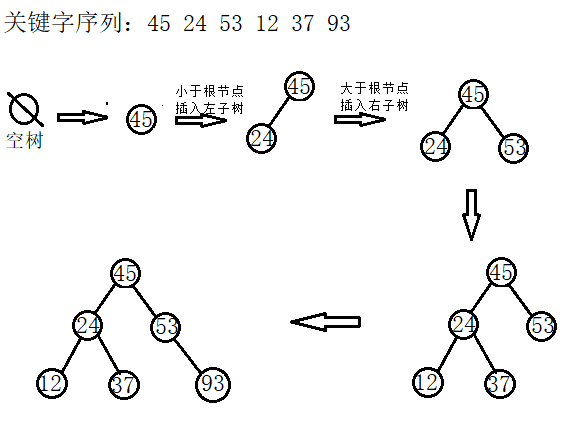
(1)插入
a.插入过程比较简单,首先判断当前要插入的值是否已经存在二叉排序树中,如果已经存在,则直接返回;如果不存在,则转b;
b.当前要插入的值不存在,则应找到适当的位置,将其插入。注意插入的新节点一定是叶子节点;
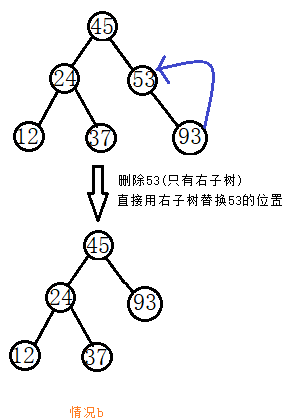
(2)删除
a.和插入一样,要删除一个给定值的节点,首先要判断这样节点是否存在,如果已经不存在,则直接返回;如果已经存在,则获取给定值节点的位置,根据不同情况进行删除、调整,转b;
b.如果待删节点只有左子树(只有右子树),则直接将待删节点的左子树(右子树)放在待删节点的位置,并释放待删节点的内存,否则转c;
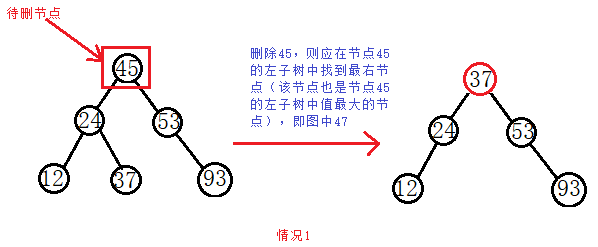
c.如果待删节点既有左子树又有右子树,此时的删除可能有点复杂,但是也比较好理解。就是在待删节点的左子树中找到值最大的那个节点,将其放到待删节点的位置。

(3)查询
查询过程比较简单,首先将关键字和根节点的关键字比较,如果相等则返回节点的位置(指针);否则,如果小于根节点的关键字,则去左子树中继续查找;如果大于根节点的关键字,则去右子树中查找;如果找到叶子节点也没找到,则返回NULL。
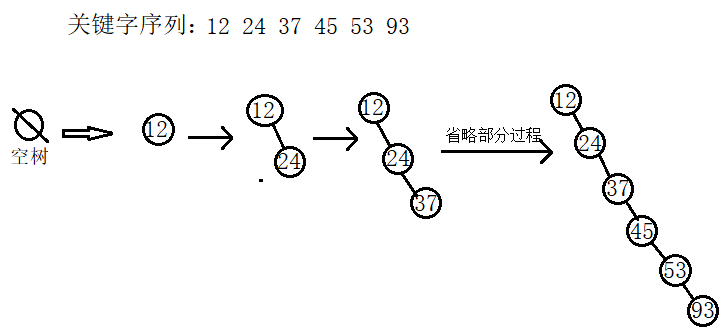
查询过程的最好情况就是上面的图中那样,节点在左右子树中分布比较均匀,此时查找的时间复杂度为O(logn);最坏的情况就是在建立二叉排序树时,输入的关键字序列正好是有序的,此时形成的二叉排序树是一棵单支二叉树,此时查找退化成了单链表的查找,时间的复杂度为O(n).如下图:
(4)遍历
由上面二排序树的定义可知,左子树的所有值均小于根节点,右子树的所有值均大于根节点,而这个特点正好和二叉树的中序遍历中--左子树->根节点->右子树不谋而合,所以对二叉排序树进行中序遍历得到的正好是一个有序的
三、源码实现(C语言代码)
#include <stdio.h>
#include <stdlib.h>
//二叉排序树
typedef struct BSTNode
{
int data;
BSTNode *lchild; //左孩子
BSTNode *rchild; //右孩子
}BSTNode,*BSTree;
bool Search(BSTree bst, int key, BSTree f, BSTree *p);
void InOderTraverse(BSTree bst) //中序递归遍历二叉树
{
if (NULL != bst)
{
InOderTraverse(bst->lchild);
printf("%d ", bst->data);
InOderTraverse(bst->rchild);
}
}
static BSTNode* BuyNode(int data) //生成一个节点并进行初始化
{
BSTNode *pTmp = (BSTNode*)malloc(sizeof(BSTNode));
if (NULL == pTmp)
{
exit(0);
}
pTmp->data = data;
pTmp->lchild = NULL;
pTmp->rchild = NULL;
return pTmp;
}
bool Insert(BSTree *bst, int key)
{
if (NULL == *bst) //空树
{
*bst = BuyNode(key); //插入根节点
return true;
}
BSTNode *p;
//先在二叉排序树中查找要插入的值是否已经存在
if (!Search(*bst, key, NULL, &p)) //如果查找失败,则插入;此时p指向遍历的最后一个节点
{
BSTNode *pNew = BuyNode(key);
if (key < p->data) //将s作为p的左孩子
{
p->lchild = pNew;
}
else if (key > p->data) //将s作为p的右孩子
{
p->rchild = pNew;
}
return true; //插入成功
}
else
{
printf("\nThe node(%d) already exists.\n", key);
}
return false;
}
/*
删除分三种情况:
(1)被删除的节点无孩子,说明该节点是叶子节点,直接删
(2)被删除的节点只有左孩子或者右孩子,直接删,并将其左孩子或者右孩子放在被删节点的位置
(3)被删除的节点既有右孩子又有右孩子
*/
void Delete(BSTree bst, int key)
{
if (NULL == bst)
{
exit(1); //空树直接报错
}
BSTNode *p;
BSTNode *f = NULL;
BSTNode *q, *s;
if (Search(bst, key, NULL, &p)) //确实存在值为key的节点,则p指向该节点
{
if (NULL == p->lchild && NULL != p->rchild) //无左孩子,有右孩子
{
q = p->rchild; //注意这里我删除节点的方式,类似于在单链表中在不知道前驱节点的情况下删除当前节点
p->data = q->data; //因为两个节点之间本质的不同在于数据域的不同,而与放在哪个地址没有关系
p->rchild = q->rchild;
p->lchild = q->lchild;
free(q);
}
else if (NULL == p->rchild && NULL != p->lchild) //无右孩子,有左孩子
{
q = p->lchild;
p->data = q->data;
p->rchild = q->rchild;
p->lchild = q->lchild;
free(q);
}
else //既有左孩子,又有右孩子
{
q = p;
s = p->lchild; //找左孩子的最右孩子
while (s->rchild)
{
q = s;
s = s->rchild;
}
p->data = s->data;
if (q != p)
{
q->rchild = p->lchild;
}
else
{
q->lchild = s->lchild;
}
free(s);
}
}
}
bool Search(BSTree bst, int key, BSTree f, BSTree *p) //查找成功时,p指向值为key的节点。如果查找失败,则p指向遍历的最后一个节点
{
if (!bst)
{
*p = f;
return false;
}
if (bst->data == key) //查找成功,直接返回
{
*p = bst;
return true;
}
else if (bst->data < key)
{
return Search(bst->rchild, key, bst, p);
}
return Search(bst->lchild, key, bst, p);
}
int main(void)
{
BSTNode *root = NULL;
Insert(&root, 45);
Insert(&root, 24);
Insert(&root, 53);
Insert(&root, 12);
Insert(&root, 90);
InOderTraverse(root);
printf("\n%d ", Insert(&root, 45)); //输出0表示插入失败,输出1表示插入成功
printf("%d\n", Insert(&root, 4));
InOderTraverse(root);
printf("\n");
Delete(root, 45); //删除节点45
InOderTraverse(root);
return 0;
}
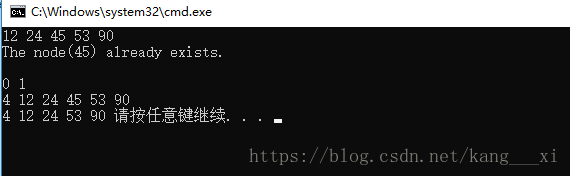
运行结果: