如果你水平高,可以直接看官方教程,根据github上的教程和相关链接,基本就能学会了ヾ(◍°∇°◍)ノ゙。如果你不想看英文可以接着看下去( ̄▽ ̄)~*
物体检测API的github官方教程
1 配置环境
首先确保已经配置好tensorflow2和cuda、cudnn环境,不要下载错。配置的教程已经有很多,自行查阅

2 安装API
tf2 object detection 的安装参考此博客,
TensorFlow 2 Object Detection API 物体检测教程
虽然这是linux系统下的,但是操作可以类比。简单地说只有三步
1.下载model-master并解压
其中tensorflow/models的下载可以选择镜像源,
镜像源
下载下来并解压后是这样的
2.下载Protobuf,把protoc.exe放到research/文件夹下,然后在此处运行
protoc object_detection/protos/*.proto --python_out=.
3.把object_detection/packages/tf2/setup.py文件复制到research/文件夹下,然后在此处运行
python -m pip install .
4.根据那篇博客的步骤一直做到第七步,运行测试文件没报错证明安装成功
python object_detection/builders/model_builder_tf2_test.py
之后要用的文件都在research/object_detection 文件夹里
我的选择是把整个object_detection 文件夹复制到pycharm 工程里,
如果出现找不到模块错误,就把整个object_detection 文件夹复制到对应的python环境的site-package里
3 制作数据集
设计自己的数据集,使用LabelImg,参考此博客
图片标注工具LabelImg的安装及使用方法
标注完成后应该得到包含一系列xml文件的文件夹,同时包括自己的图片文件夹,两者需要一一对应。
当然除了训练集还需要测试集,方法一样,在此省略
4 下载预训练模型
要下载模型和对应的config文件(config文件可以不用单独下载,已经包含在压缩包里),不要看了其他教程去下载tf1的模型哦,否则必定出现不支持的error
电脑不好的建议选择小模型
ssd_mobilenet_v2_320x320_coco17_tpu-8
否则必定会出现OMM错误,即GPU显存不足,因为大模型卷积核太多了,一卷就出错(╥╯^╰╥)
tf2 模型下载地址
https://codechina.csdn.net/mirrors/tensorflow/models/-/blob/master/research/object_detection/g3doc/tf2_detection_zoo.md
tf2 配置文件config下载地址
https://codechina.csdn.net/mirrors/tensorflow/models/-/tree/master/research/object_detection/configs/tf2
模型下载下来是一个tar文件,直接解压发现没用,因为这是一个tar.gz文件,是被压缩两次的,win10里我也不知道有什么办法可以把它解压(╬ ̄皿 ̄),只能把后缀名改成tar.gz,然后复制到ubuntu的虚拟机里,使用tar -zxvf xxx.tar.gz命令解压后再复制出来
很笨的方法但是有效ಠ╭╮ಠ
最后得到这样的文件,其中pipeline的config就是配置文件,这个文件很重要,关系到所有的训练参数
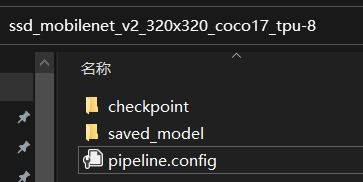
其中checkpoint里只有三个文件了,没有meta文件,与tf1不同
5 准备好tfrecord文件和config文件
可以看此篇博客前半部分,学会如何生成record文件和配置config文件,后面的训练部分就不要看了,是tf1的
然后我们得到
(1)自己创建的 label_map.pbtxt 文件
(2)生成的record文件,应该有train和test两个,record文件大小约等于你的所有图片总和
(3)修改了至少4个地方的config文件
num_classes:1 假设你只要检测1种物体
fine_tune_checkpoint_type: “detection” 类型改为detection
fine_tune_checkpoint= ‘你的路径/ckpt-0’
train_input_reader/input_path:“你的路径/train.record”
train_input_reader/label_map_path:“你的路径/label_map.pbtxt”
eval_input_reader/inputpath:“你的路径/test.record”
eval_input_reader/label_map_path: “你的路径/label_map.pbtxt”
还有batch-size、learning rate、num steps、replicas_to_aggregate等可以自己看着改,如果后面内存溢出就改小一点batch-size
想知道config文件的具体意义可以参考以下博客
https://copyfuture.com/blogs-details/20200630233052263i2qwtu5rloywtv1
6 开始训练
要用到的文件是,训练的主文件

修改此文件两个地方,改成你自己的config文件的路径和想要保存模型(检查点)的路径
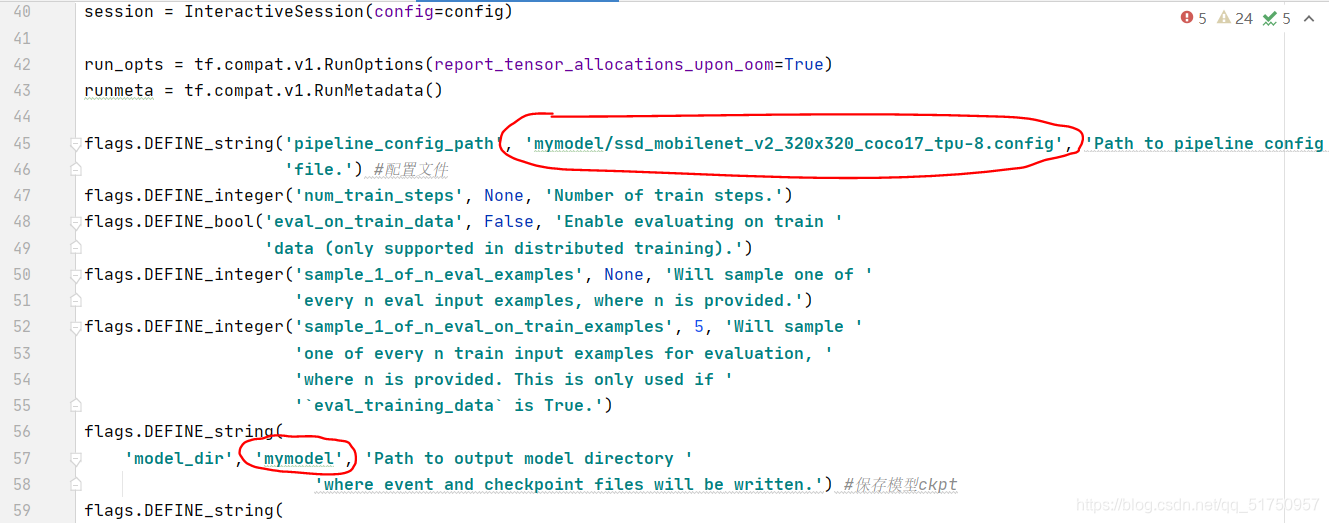
然后运行此文件就可以开始训练了,正常应该会报如下信息
在检查点保存的位置还有一个train文件夹,有events out 文件,可以用tensorboard查看
tensorboard --logdir=mymodel\train --port=8008
然后会出现一个网址,点进去就可以看到训练过程
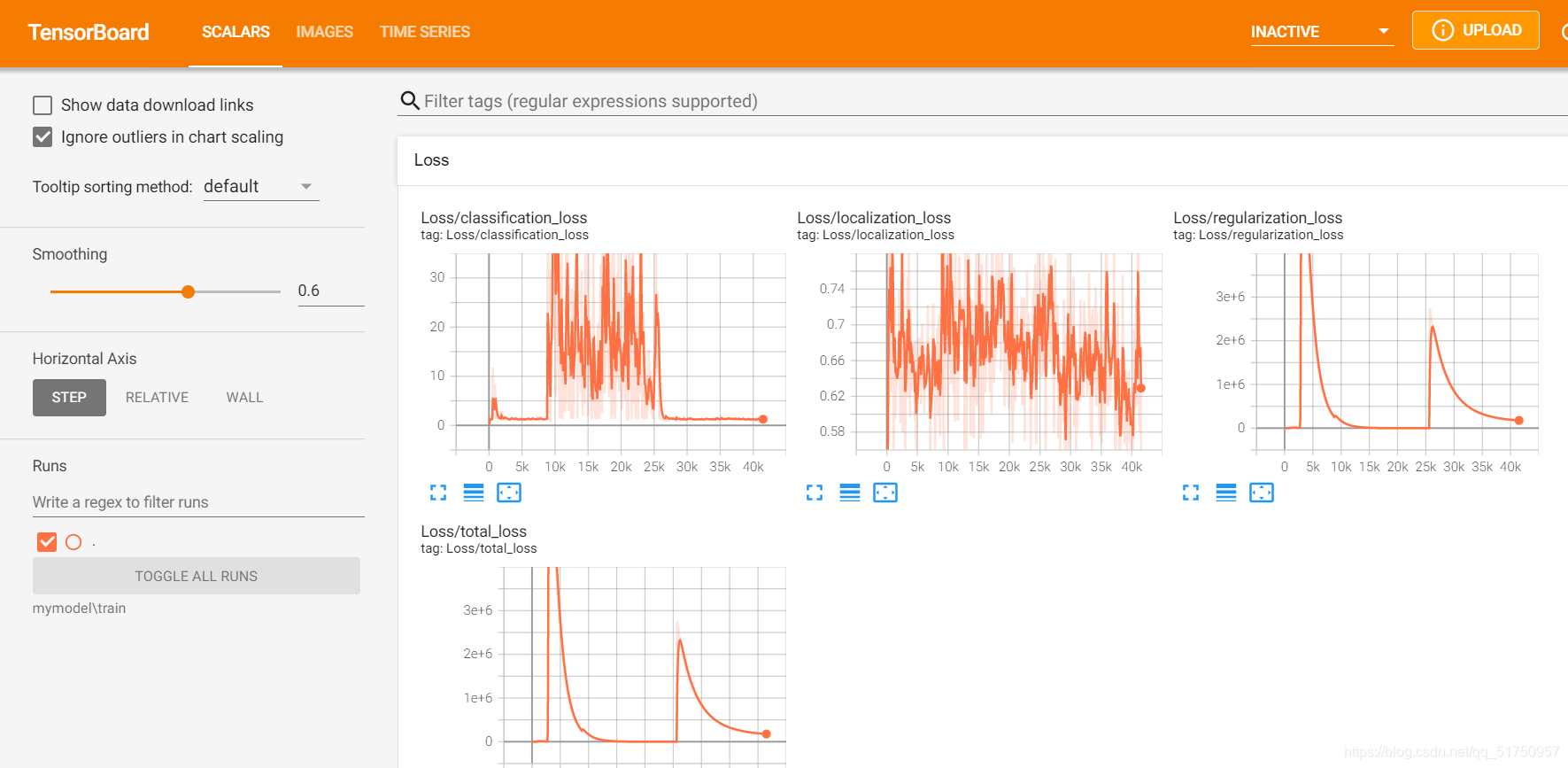
6 导出模型
训练过程中会生成检查点ckpt文件,最多存在7个(可以自己改数目)
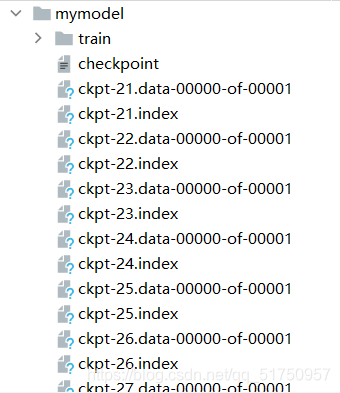
使用此文件可以把ckpt文件变成pb文件

改变此文件中这几处地方为你的路径
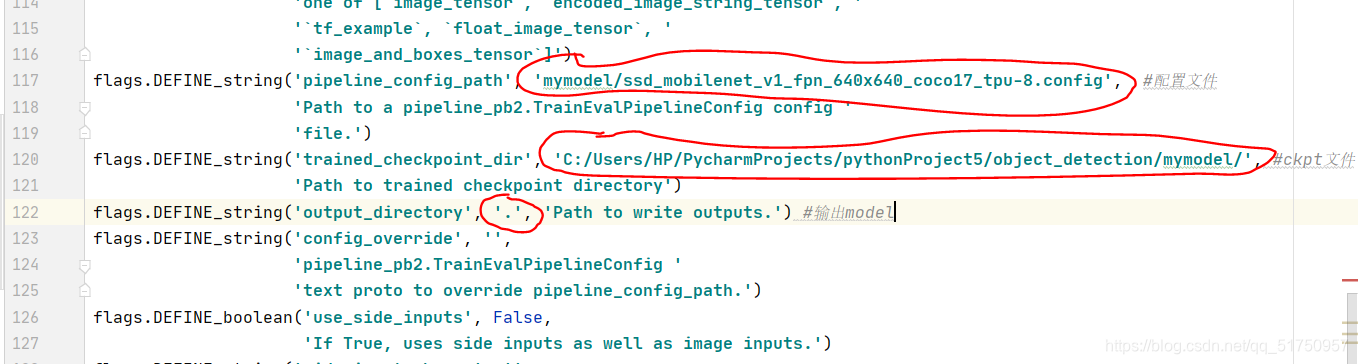
然后运行,得到saved model文件夹,之后就可以调用这个model了
7 使用模型
自己建立python程序,加载模型并测试
import tensorflow as tf
import keras
import cv2
import os
import numpy as np
from matplotlib import pyplot as plt
from object_detection.utils import label_map_util
def show_y(y,image_np):
# 提取信息
boxes = y['detection_boxes']
scores = y['detection_scores']
classes = y['detection_classes']
num_classes = y['num_detections']
# category_index={1:{'id':1,'name':'clamp'}}
#显示出来
image_np = vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=5,
min_score_thresh=.5,
line_thickness=5)
plt.switch_backend('Qt5Agg')
plt.figure(figsize=[256, 256])
plt.imshow(image_np)
plt.show()
PATH_TO_LABELS = os.path.join('data', 'label_map.pbtxt')
NUM_CLASSES = 1
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
plt.switch_backend('Qt5Agg')
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as vis_util
config = tf.compat.v1.ConfigProto(gpu_options=tf.compat.v1.GPUOptions(allow_growth=True))
sess = tf.compat.v1.Session(config=config)
model_c=tf.saved_model.load('saved_model') #加载模型
for i in range(1,8):
#导入并处理图片
img=cv2.imread('test00'+str(i)+'.jpg')
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
image_np=img
img2=tf.expand_dims(img,axis=0)
#运行model
y=model_c(img2)
show_y(y,img)
y是8元素字典,其中提取得到4个主要信息
boxes是4*100的矩阵,一行表示[ymin, xmin, ymax, xmax],是边界框的边界,共有100个框,但不是所有的都会被采用
scores、classes都有100个数据,与boxes相互对应,表示此框的得分和类型,得分不到0.5就不会被采用
vis_util.visualize_boxes_and_labels_on_image_array可以画出结果图,感兴趣可以看vis_util源码,并自己改变一些参数
如果加载label_map.pbtxt出现‘utf-8’无法解码的错误,就复制一份data里自带的pbtxt文件,重命名为label_map.pbtxt并改成自己的数据
8 测试结果
成功检测出夹子
