文章目录
Tensorflow中高阶API的使用
1. 构建数据管道
当数据量不大时,我们可以一次全部载入内存中训练;但是如果数据量很大,我们就要考虑将数据分批次载入内存中训练,这个时候就要利用数据管道。构建数据管道的途径有很多,下面介绍几种常见的数据格式构建数据管道的方式。
1.1 numpy的ndarray构建
data=tf.data.Dataset.from_tensor_slices((iris['data'],iris['target']))
# 从data中拿三条数据
for feature,label in data.take(3):
print(feature,label)
# 设置batch_size=x,每次取出一个batch
for feature,label in data.batch(32):
print(feature,label)
1.2 从DataFrame构建
data=pd.DataFrame(iris['data'],columns=iris.feature_names)
data=tf.data.Dataset.from_tensor_slices((data.to_dict('list'),iris['target']))
for f,l in data.take(1):
print(f,l)
1.3 生成器构建
from tensorflow.keras.preprocessing.image import ImageDataGenerator
image_generator=ImageDataGenerator().flow_from_directory("Path")
# 定义一个生成器函数
def generator():
for f,l in image_generator:
yield (f,l)
data=tf.data.Dataset.from_generator(generator,output_types=(...))
1.4 文本文件构建
# 从cvs文件构建
data=tf.data.experimental.make_csv_dataset(file_pattern="...",label_name="xxx",batch_size=xx)
# 从文本文件构建
data=tf.data.TextLineDataset(filenames="xxx")
1.5 从文件路径构建
data=tf.data.Dataset.list_files("xxx/*.jpg")
2. 构建模型
定义模型有三种方式,顺序式、函数式、自定义,最简单易用的就是顺序式,只需要像搭积木那样对model不停地添加就好;但是如果面对模型具有残差结构或者其他非顺序式结构,这个时候就需要函数式建模方式;自定义建模主要针对某些网络模块需要自己实现,这个时候就利用自定义方式搭建;下面就用iris数据集利用三种不同方式构建模型。
准备工作
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
from tensorflow.keras import models,layers,optimizers,losses
from sklearn.model_selection import train_test_split
import os
from datetime import datetime
os.environ['TF_CPP_MIN_LOG_LEVEL']='1'
plt.rcParams['font.sans-serif']='simhei'
plt.rcParams['axes.unicode_minus']=False
data,target=datasets.load_iris()['data'],datasets.load_iris()['target']
X_train,X_test,y_train,y_test=train_test_split(data,target,test_size=0.3,random_state=0)
def plot_metric(history,metric):
train_metric=history.history[metric]
val_metric=history.history['val_'+metric]
X=[i for i in range(1,len(train_metric)+1)]
plt.plot(X,train_metric,'bo--',label="train_"+metric)
plt.plot(X,val_metric,'ro-',label="val_"+metric)
plt.title("训练-测试"+metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend()
plt.show()
2.1 顺序模型
model1=models.Sequential()
model1.add(layers.Dense(10,input_shape=(4,),activation='relu'))
model1.add(layers.Dense(10,activation='relu'))
model1.add(layers.Dense(3,activation='softmax'))
model1.compile(
optimizer=optimizers.Adam(0.01),
loss=losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
model1.summary()
开始训练
logdir1='./model/model1/'+datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback1 = tf.keras.callbacks.TensorBoard(logdir1, histogram_freq=1)
history=model1.fit(
X_train,y_train,
validation_data=(X_test,y_test),epochs=20,
callbacks=[tensorboard_callback1]
)
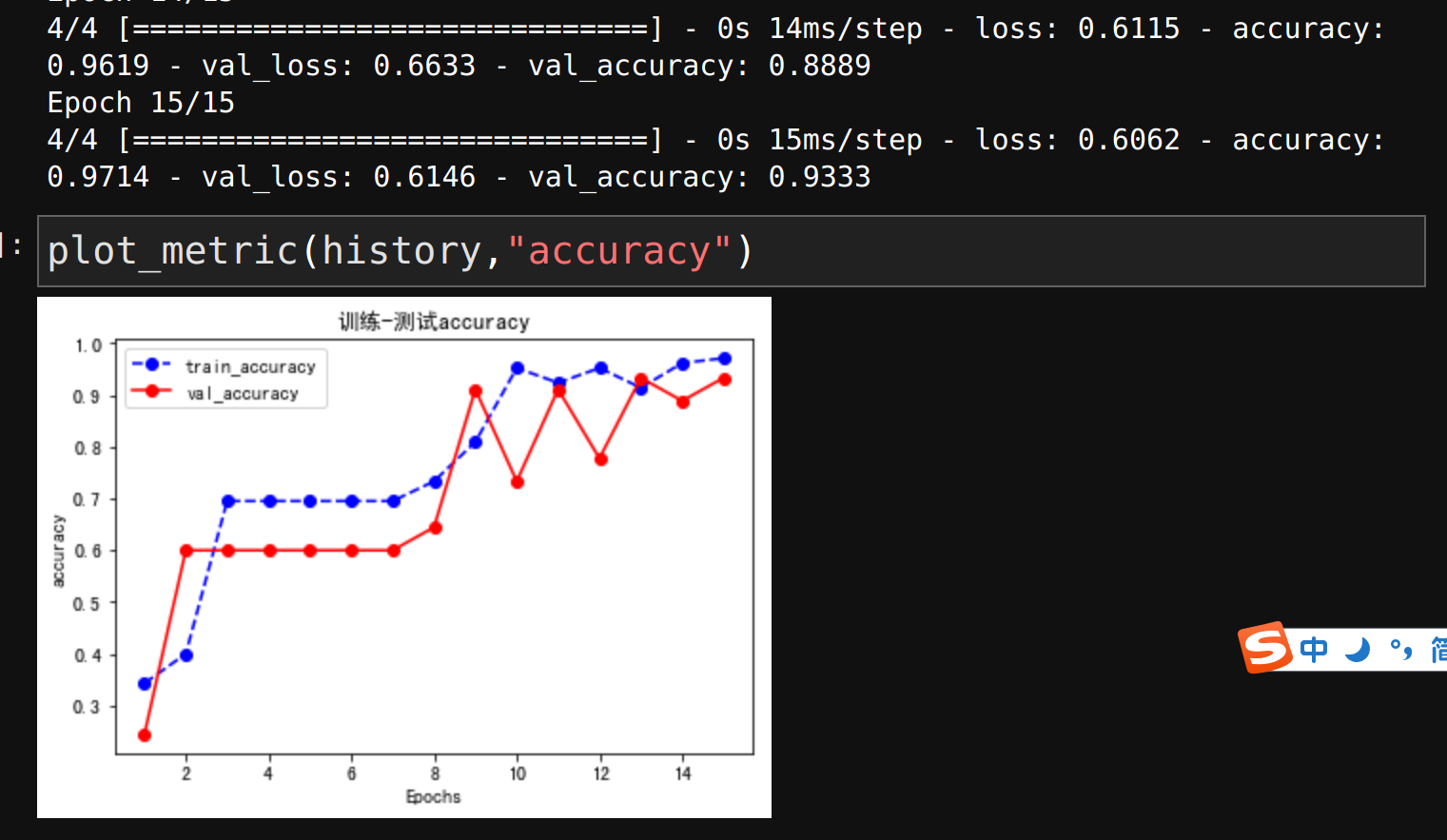
plot_metric(history,"accuracy")
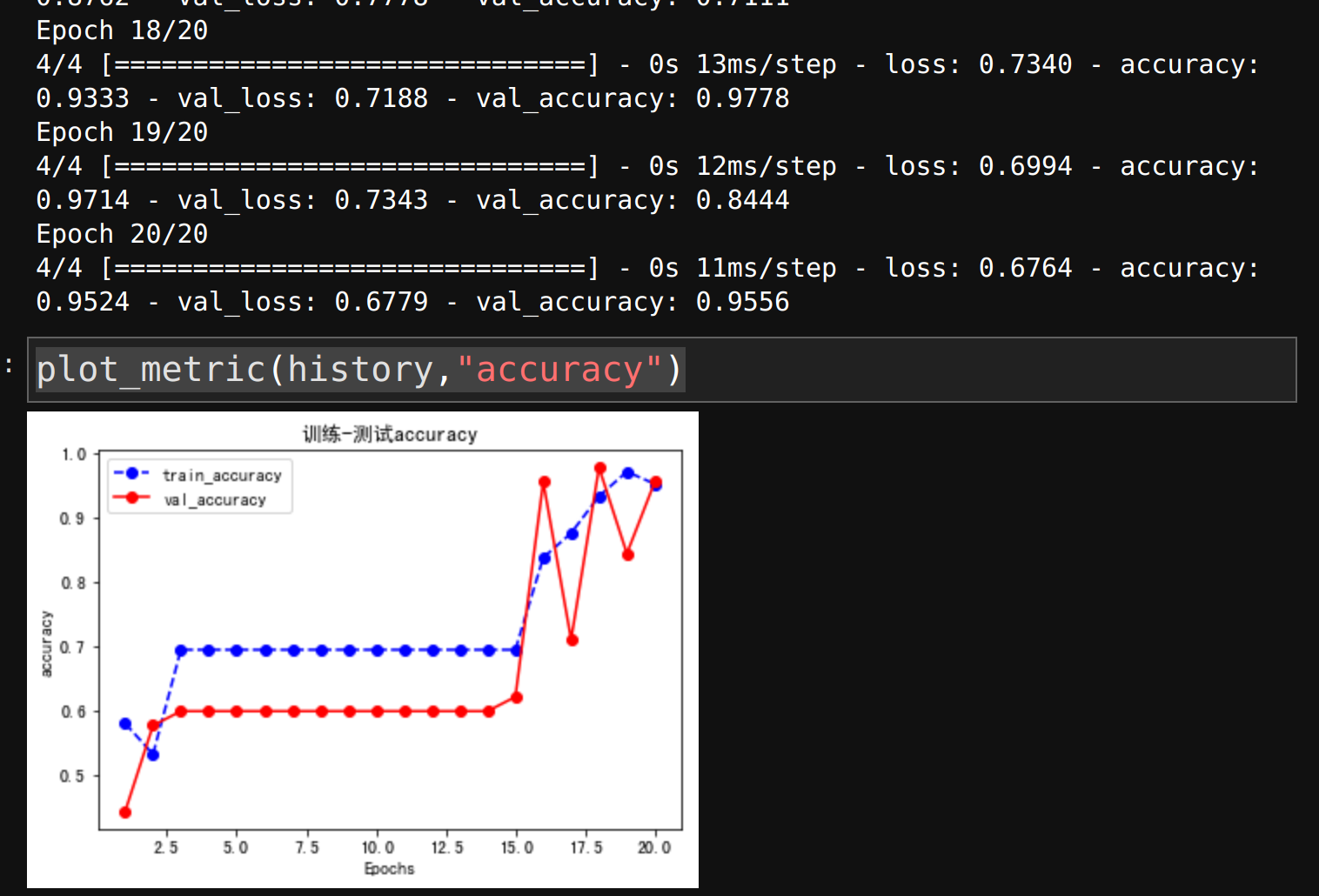
2.2 函数式模型
inputs=layers.Input(shape=(4,))
branch1=layers.Dense(10,activation='relu')(inputs)
branch1=layers.Dense(10,activation='relu')(branch1)
branch2=layers.Dense(10,activation='relu')(inputs)
branch2=layers.Dense(10,activation='relu')(branch2)
concat=layers.Concatenate()([branch1,branch2])
branch3=layers.Dense(10,activation='relu')(concat)
outputs=layers.Dense(3,activation='softmax')(branch3)
model2=models.Model(inputs=inputs,outputs=outputs)
model2.compile(
optimizer=optimizers.Adam(0.01),
loss=losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
model2.summary()
logdir2='./model/model2/'+datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback2 = tf.keras.callbacks.TensorBoard(logdir2, histogram_freq=1)
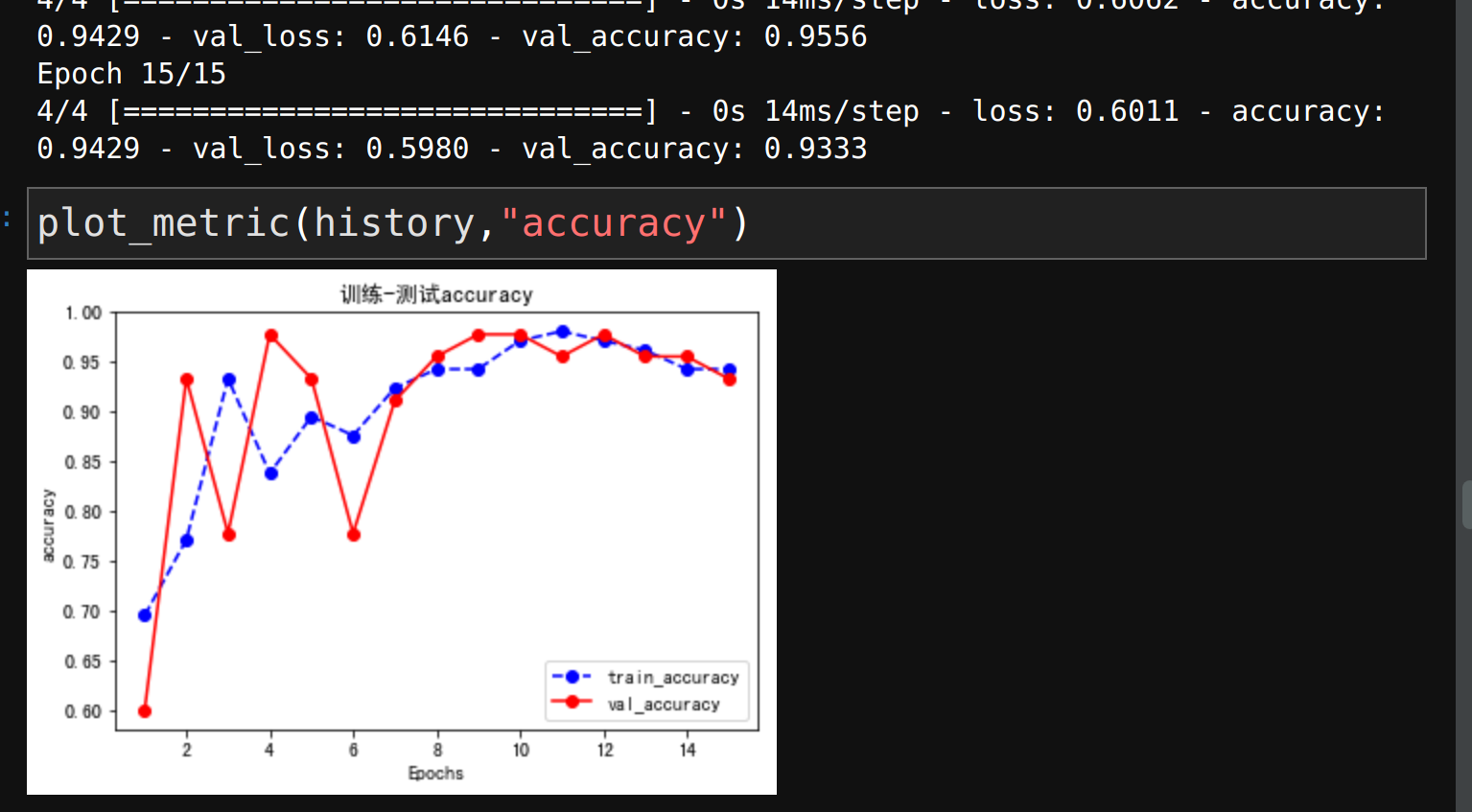
history=model2.fit(
X_train,y_train,
validation_data=(X_test,y_test),epochs=15,
callbacks=[tensorboard_callback2]
)
模型有两个分支然后合并,长这个样子
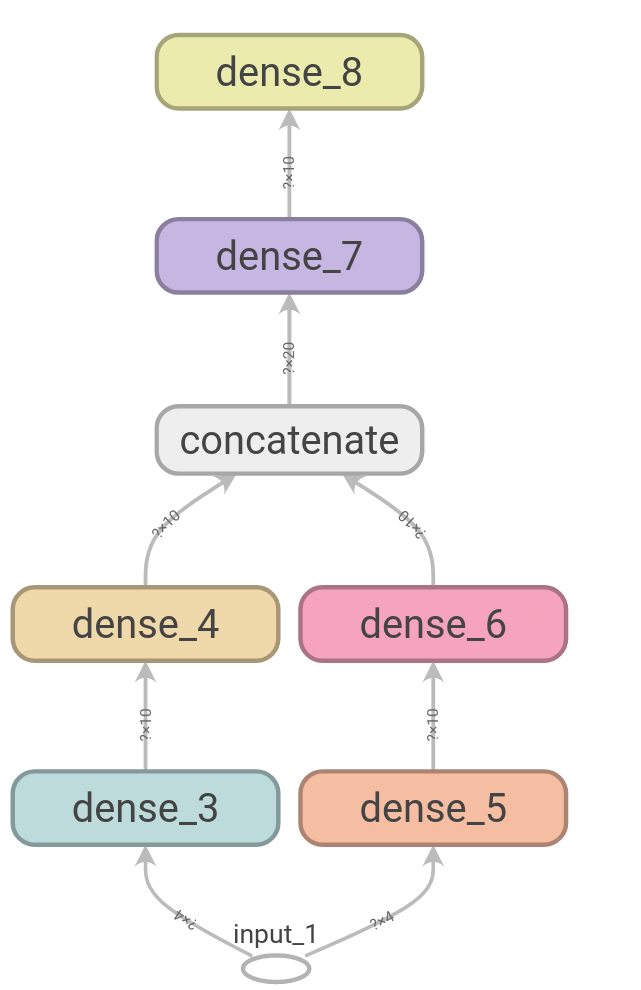
这里只是为了演示非序列式模型,其实这种结构对于这个问题是没有必要的。
2.3 自定义模型
先定义子结构
class Block(layers.Layer):
def __init__(self,**kwargs):
super(Block,self).__init__(**kwargs)
def build(self,input_shape):
self.a=layers.Dense(20,activation='relu')
self.b=layers.Dense(10,activation='relu')
super(Block,self).build(input_shape)
def call(self,inputs):
x=self.a(inputs)
x=self.b(x)
return x
def get_config(self):
config=super(Block,self).get_config()
return config
# 测试
block=Block()
block.build(input_shape=(None,4,))
block.compute_output_shape(input_shape=(None,4,))
类似于残差结构,我们可以使用自己自定义的结构来构建模型,不过这样很容易出错,后期网络搭建的时候调试也不方便。
所以我们定义好之后可以先试试输出的shape与我们预期是否一致
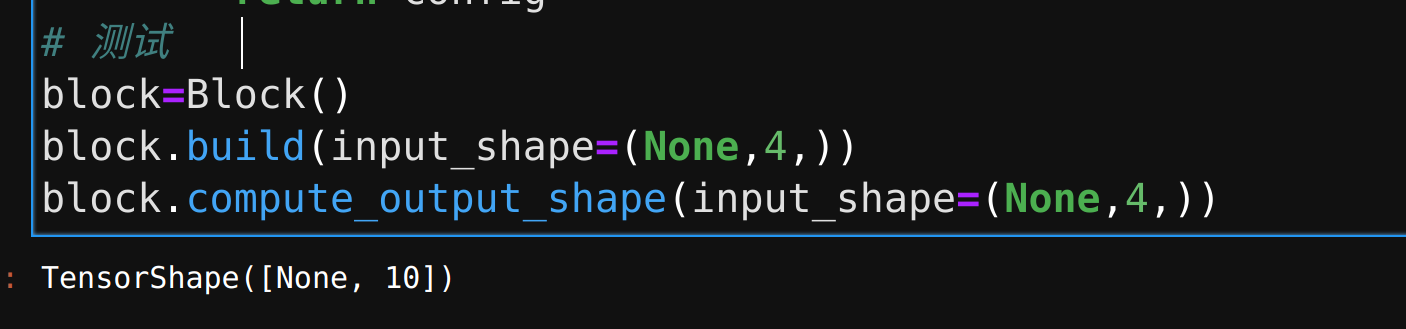
然后利用自定义的结构再构建网络
class Model3(models.Model):
def __init__(self):
super(Model3,self).__init__()
def build(self,input_shape):
self.block1=Block()
self.block2=Block()
self.dense=layers.Dense(3,activation='softmax')
super(Model3,self).build(input_shape)
def call(self,x):
x=self.block1(x)
x=self.block2(x)
x=layers.Flatten()(x)
x=self.dense(x)
return x
model3=Model3()
model3.build(input_shape=(None,4))
model3.compile(
optimizer=optimizers.Adam(0.01),
loss=losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
model3.summary()
结束
到这里,关于Tensorflow使用的部分就暂时告一段落了。这个专栏由于更多是为了留给自己复习看的,所以并没有方方面面都涉及到,比如早停、学习率动态调整、常用的卷积层、特征变换……这些很常用但是我没有讲,后期涉及到的时候会慢慢把相关的例子补上。接下来就是pytorch相关的,这个相对于Tensorflow来说还是更简单一点点的,所以尽快过一遍。