树模型总结
1.树模型基础介绍。
-
什么是树模型? 一种基于特征空间划分的具有树形分支结构的模型。
-
树模型的特点? 方差大、对量纲没有要求、由多条规则组成、能够处理数值型和类别型数据、有较高的解释性。
-
树模型的优点? 1)需要准备的数据量不大。 2)算法时间的复杂度是用于训练决策树的数据点的对数。 3)能够处理数值型和类别型数据。 4)相对对神经网络,解释性比较强。
-
树模型的缺点? 有的规则不具备可解释性、抗干扰能力弱、最优决策划分是NP难问题、对数据不均衡类别倾向数据多的类别。
2.决策树介绍。
一切树模型的都是基于特征空间划分的条件概率分布,都具有方差大的特性,对量纲无要求,所以我们先介绍几种条件概率公式:
条件概率
定义:设A,B是两个事件,且P(A)>0,称
为在事件A发生的条件下事件B发生的概率。
全概率
定理 设随机试验E的样本空间为S,A为E的事件, , ,……, 为样本空间S的一个划分,且P(A)>0,P()>0 (i = 1,2,3,……),则有全概率公式:
贝叶斯
定理 设随机试验E的样本空间为S,A为E的事件, , ,……, 为样本空间S的一个划分,且P(A)>0,P()>0 (i = 1,2,3,……),则有贝叶斯公式:
什么是决策树?决策树是如何工作的?
决策树是一种监督学习算法(具有预定义的目标变量),它主要用于分类问题,输入和输出变量可以是离散值或连续值。在决策树中,我们根据输入变量中最具有区分性的变量,把数据集或样本分割为两个或两个以上的子集合。
决策树的类型
1、分类树:目标为离散变量决策树,具有离散型目标变量的决策树。例如在上述学生分类问题中,目标变量是学生是否玩板球,即“是”或“否”。
2、回归树:连续变量决策树,具有连续型目标变量的决策树
树如何决定在哪里分裂?
分列策略对树的准确率影响很大,回归树和分类树具有不同的决策标准。 常见的几种分裂算法: 1.基尼系数是指,如果我们从样本集中随机选择两个样本点,如果该样本集是纯的,那么这两个样本点属于相同的类的概率是1。适合于“是/否”这种二元分裂。 2.卡方,是找到子节点和父节点之间差别的统计意义。我们通过目标变量的观测值和期望值的标准化差异平方和来衡量。卡方 = ((实际值 - 期望值) / 期望值)^(1/2)。适合于“是/否”这种二元分裂。 3.信息增益, ,为信息出现的概率,易受量纲的影响,C4.5中采用信息增益比。根据信息熵进行分裂的步骤:1)计算父节点的信息熵。2)计算根据每个节点进行分裂的信息熵,计算所有子节点可能分裂的加权平均。
树模型的关键参数是什么?决策树中如何避免过拟合?
1)剪枝。
2)特征尽量避免使用连续型变量,
3)减小树的深度。
4)节点分裂的最小样本数,太高的值会导致欠拟合,因此需要使用CV(交叉验证)进行调参。
5) 叶节点中的最小样本数 .
6)叶节点的最大数目。
7)考虑分裂的最大特征个数。
树模型比线性模型更好么?决策树的优缺点?
不一定,线性回归可以解决回归问题,逻辑回归可以解决分类问题,为什么还要使用树模型呢:
1、如果因变量和自变量的关系能用线性模型很好地近似表达,线性回归会优于树模型。
2、如果因变量和自变量的关系是高度非线性和非常复杂关系,树模型会优于经典回归方法。
3、如果你需要构建一个易于解释的模型,决策树模型总会比线性模型更好。决策树模型甚至比线性回归模型更容易解释。
优点
1、易于理解:决策树的输出是非常容易理解的,即使是对于没有数据分析背景的人。它不需要任何统计知识去阅读和解释。它的图形标识非常直观,用户可以很容易地和他们的假设联系在一起。
2、在数据探索中非常有用:决策树是发现最相关的两个或多个变量关系的最快速的方式之一。在决策树的帮助下,我们可以创建新的具有更强预测能力的变量/特征,可以参考这篇文章(提升回归模型的技巧)。它还可以用于数据探索阶段。例如,我们正在研究一个具有数百个变量信息的问题,决策树可以帮助我们确定最重要的哪些变量。
3、需要更少的数据清洗:相对于其他建模技术,决策树需要较少的数据清洗。它不会收到离群点和缺失值的特别大的影响。
4、数据类型不受约束:决策树可以处理数值型和离散型数据变量。
5、非参数方法:决策树是一个非参数方法。这意味着它不对数据的空间分布和分类结构做任何假设。
缺点
1、过拟合:过拟合是决策树最难处理的困难之一,这个问题通过设置模型参数和剪枝(下面讨论)来解决。
2、不适合于连续型变量:当处理连续数值型变量时,当决策树把连续变量划分成一系列离散值的时候会导致信息丢失
3.集成学习Bagging之RF介绍。
基于树模型的集成方法有哪些?
集成学习(Ensemble Methods)使用一组预测相同目标的模型通过投票、加权平均、梯度提升等组合方法,多多个弱学习模型进行组合。
偏差和方差的问题?
几乎所有的模型都有偏差和方差问题,偏差表示预测值与目标值之间偏离程度,方差表示是指同一个数据集在模型预测结果的差异程度。(通常是样本目标异常导致的)
通常,当你增加模型复杂度,你会看到由于模型的偏差降低,预测错误率会降低。当你持续提升模型复杂度,会导致模型过拟合,你的模型会产生高偏差。
常用的集成方法
Bagging、Boosting和Stacking
Bagging的工作原理
1)有放回抽样多个数据集建模形成多个分类器。 2)对多个分类器结果进行投票处理。 典型代表RF随机森林。
Boosting的工作原理?
1)初始化每个训练样本相同的权重。
2)每次训练更新一次权重,对分类错误的样本重采样时加大权重。
典型代表:AdaBoost、GBDT。
stacking的工作原理?
对多个学习器的预测结果作为新模型的输入重新训练。
Random Forest
RF的工作原理?
1)随机放回抽样训练样本。(列采样,行采样) 2)随机选择特征。 3)构建决策树。 4)分类:投票。回归:平方误差最小化。
RF有两个随机采样过程
有放回的随机采样-bootstrap采样: 行采样:采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本 列采样: 从M个feature中,选择m个(m << M)
RF的特点?
放回抽样,特征和样本随机采样,无剪枝,投票,可以减小方差,CART若学习器。
RF的优缺点
优点
1)可以处理高维数据 2)减小了单模型的方差和偏差。 3)可以计算特征的重要程度。
劣势
1)对于回归问题RF的精准度不够。 2)抗噪声干扰能力弱,无法自动处理异常样本。 3)模型越深越容易过拟合。
4.集成学习Boosting之GBDT、XGBOOST、LightGBM等介绍。
GBDT的算法特点?
1)与传统Boosting(Adaboost)不同,每次计算不是减小残差而是消除残差。
2)每次重新建模都是往残差减小的方向进行建模,在Gradient Boost时利用loss function负梯度方向的残差拟合新的CART回归树。这里损失函数和logistics一样采用logloss= ,这里Gradient Boost与Gradient Descent 不同,GD是针对可微分的函数,使解往梯度负方向迭代,对下一次迭代做一阶泰勒展开: ,set,,一直迭代直到,函数收敛,停止迭代,r为学习率。泰勒展开就是一种对于f(x)在x=处n阶可导。利用多项式对函数进行逼近。
3) 弱学习器只能是CART回归树。
4)GBDT做分类时,每一次迭代需要有k棵树,k是类别数目,每棵树对一个类别进行预测。每个叶子节点也只是输出一个值,可把这颗树看作一个函数f,f将输入样本的特征映射为该值。(注意,该值并不是类别的概率,概率还需要一个logistic转化,logistic regression是:特征x先转化成实值z,然后z经过logistic regression转化成概率p(x),这里叶子节点的值相当于z)。
参考:https://blog.csdn.net/xsqlx/article/details/51330627
GBDT与RF比较?
1)都是由多棵树组成。
2)GBDT用于分类,每个CART数的结果是概率。
3)RF结果是投票,GBDT结果是加权求和。
4)RF偏重与减小方差,提高稳定性。GBDT偏重与提高偏差,提高精准率。
5)GBDT对异常值敏感,RF不敏感。
6)RF对采样的训练集不加以区分,GBDT按照偏差进行权重处理。
XGBoost的特点?
论文: https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf Slide : https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf 总结:http://blog.csdn.net/sb19931201/article/details/52557382
原论文:https://arxiv.org/pdf/1603.02754v1.pdf
1)XGBoost是陈天奇读博的时候针对GBDT改进的一个可扩展的端到端树增强系统xgboost,工程源码非常具有研读的价值。
2)稀疏数据感知,对拥有大量缺失值的数据做one-hot编码,单独分裂节点进行处理。
3)采用加权分位数法来搜索近似最优分裂节点,提供特征排序和数据压缩功能,都属内存操作,因此内存消耗较大。
4)C++并行分布式计算框架。
5)弱分类器支持线性分类器:逻辑回归和线性回归;也支持树分类器:gbdt。
6)对t次迭代后的误差函数进行二次泰勒展开使得loss function在下一个点损失最小,以此作为分裂条件,这里与CART取均方误差最小为分裂不同。
7)损失函数中加入了正则化。
8)xgboost分裂和GBDT一样采用了贪心算法。
XGBoost与GBDT比较?
1)GBDT只能以CART作为基分类器,xgboost还支持线性分类器,此时xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。 可以通过booster [default=gbtree]设置参数:gbtree: tree-based、models/gblinear: linear models
2)GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。 —对损失函数做了改进(泰勒展开,一阶信息g和二阶信息h)
3)论文中2.1 Regularized Learning Objective,xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性 —正则化包括了两个部分,都是为了防止过拟合,剪枝是都有的,叶子结点输出L2平滑是新增的。
4)shrinkage and column subsampling —还是为了防止过拟合,论文2.3节有介绍。
(1)shrinkage缩减类似于学习速率,在每一步tree boosting之后增加了一个参数n(权重),通过这种方式来减小每棵树的影响力,给后面的树提供空间去优化模型。
(2)column subsampling列(特征)抽样,说是从随机森林那边学习来的,防止过拟合的效果比传统的行抽样还好(行抽样功能也有),并且有利于后面提到的并行化处理算法。
5)split finding algorithms(划分点查找算法):— (1)exact greedy algorithm—贪心算法获取最优切分点 ,通过每次尝试分裂一个叶节点,计算分裂前后的增益,选择增益最大的。 (2)approximate algorithm— 近似算法,提出了候选分割点概念,先通过直方图算法获得候选分割点的分布情况,然后根据候选分割点将连续的特征信息映射到不同的buckets中,并统计汇总信息。详细见论文3.3节 (3)Weighted Quantile Sketch—分布式加权直方图算法,论文3.4节 这里的算法(2)、(3)是为了解决数据无法一次载入内存或者在分布式情况下算法(1)效率低的问题,以下引用的还是wepon大神的总结:
可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
6.对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。 —稀疏感知算法,论文3.4节,Algorithm 3: Sparsity-aware Split Finding
7.Built-in Cross-Validation(内置交叉验证)
XGBoost allows user to run a cross-validation at each iteration of the boosting process and thus it is easy to get the exact optimum number of boosting iterations in a single run. This is unlike GBM where we have to run a grid-search and only a limited values can be tested.
8.continue on Existing Model(接着已有模型学习)
User can start training an XGBoost model from its last iteration of previous run. This can be of significant advantage in certain specific applications. GBM implementation of sklearn also has this feature so they are even on this point.
9.High Flexibility(高灵活性)
XGBoost allow users to define custom optimization objectives and evaluation criteria. This adds a whole new dimension to the model and there is no limit to what we can do.
10.并行化处理 —系统设计模块,块结构设计等
xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
此外xgboost还设计了高速缓存压缩感知算法,这是系统设计模块的效率提升。 当梯度统计不适合于处理器高速缓存和高速缓存丢失时,会大大减慢切分点查找算法的速度。 (1)针对 exact greedy algorithm采用缓存感知预取算法 (2)针对 approximate algorithms选择合适的块大小
Light GBM与XGBoost比较?
1)微软出的一个比xgboost更加高效的一个分布式Boosting树模型。
2)histogram算法,基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点;优点在于决策树生长策略上。
3)XGBoost采用的是带深度限制的level-wise生长策略,Level-wise过一次数据可以能够同时分裂同一层的叶子,容易进行多线程优化,不容易过拟合;但不加区分的对待同一层的叶子,带来了很多没必要的开销(因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂)·
4)LightGBM采用leaf-wise生长策略,每次从当前所有叶子中找到分裂增益最大(一般也是数据量最大)的一个叶子,然后分裂,如此循环;但会生长出比较深的决策树,产生过拟合(因此LightGBM 在leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合)。
5)比xgboost更快的训练速度和更高的效率:LightGBM使用基于直方图的算法。例如,它将连续的特征值分桶(buckets)装进离散的箱子(bins),这是的训练过程中变得更快。
6)更低的内存占用:使用离散的箱子(bins)保存并替换连续值导致更少的内存占用。
7)更高的准确率(相比于其他任何提升算法) :它通过leaf-wise分裂方法产生比level-wise分裂方法更复杂的树,这就是实现更高准确率的主要因素。然而,它有时候或导致过拟合,但是我们可以通过设置 max-depth 参数来防止过拟合的发生。
8)大数据处理能力:相比于XGBoost,由于它在训练时间上的缩减,它同样能够具有处理大数据的能力。支持进程粒度的并行学习 。
| 对比项 | XGBoost | LightGBM |
|---|---|---|
| 正则化 | L1/L2 | L1/L2 |
| 列采样 | yes | yes |
| Exact Gradient | yes | yes |
| 近似算法 | yes | no |
| 稀疏数据 | yes | yes |
| 分布式并行 | yes | yes |
| 缓存 | yes | no |
| out of core | yes | no |
| 加权数据 | yes | yes |
| 树增长方式 | level-wise | leaf-wise |
| 基于算法 | pre-sorted | histgram |
| 最大树深度控制 | 无 | 有 |
| dropout | no | yes |
| Bagging | yes | yes |
| 用途 | 回归、分类、rank | 回归、分类、lambdrank |
| GPU支持 | no | yes |
| 网络通信 | point-to-point | collective-communication |
| CategoricalFeatures | 无优化 | 优化 |
| Continued train with input GBDT model | no | yes |
| Continued train with input | no | yes |
| Early Stopping(both training and prediction) | no | yes |
LightGBM的重要参数
task:默认值=train,可选项=train,prediction;指定我们希望执行的任务,该任务有两种类型:训练和预测;
application:默认值=regression,type=enum,options=options
regression:执行回归任务;
binary:二分类;
multiclass:多分类;
lambdarank:lambrank应用;
data:type=string;training data,LightGBM将从这些数据中进行训练;
num_iterations:默认值为100,类型为int。表示提升迭代次数,也就是提升树的棵树;
num_leaves:每个树上的叶子数,默认值为31,类型为int;
device:默认值=cpu;可选项:cpu,gpu。也就是我们使用什么类型的设备去训练我们的模型。选择GPU会使得训练过程更快;
min_data_in_leaf:每个叶子上的最少数据;
feature_fraction:默认值为1;指定每次迭代所需要的特征部分;
bagging_fraction:默认值为1;指定每次迭代所需要的数据部分,并且它通常是被用来提升训练速度和避免过拟合的。
min_gain_to_split:默认值为1;执行分裂的最小的信息增益;
max_bin:最大的桶的数量,用来装数值的;
min_data_in_bin:每个桶内最少的数据量;
num_threads:默认值为OpenMP_default,类型为int。指定LightGBM算法运行时线程的数量;
label:类型为string;指定标签列;
categorical_feature:类型为string;指定我们想要进行模型训练所使用的特征类别;
num_class:默认值为1,类型为int;仅仅需要在多分类的场合。
5.深度森林GCF介绍。
深度森林(Deep Forest)是周志华教授和冯霁博士在2017年2月28日发表的论文《Deep Forest: Towards An Alternative to Deep Neural Networks》中提出来的一种新的可以与深度神经网络相媲美的基于树的模型,其结构如图所示。
文中提出的多粒度级联森林(Multi-Grained Cascade Forest)是一种决策树集成方法,性能较之深度神经网络有很强的竞争力。相比深度神经网络,gcForest有如下若干有点:
1. 容易训练,计算开销小 2.天然适用于并行的部署,效率高 3. 超参数少,模型对超参数调节不敏感,并且一套超参数可使用到不同数据集 4.可以适应于不同大小的数据集,模型复杂度可自适应伸缩 5. 每个级联的生成使用了交叉验证,避免过拟合 6. 在理论分析方面也比深度神经网络更加容易。
Paper:https://arxiv.org/abs/1702.08835v2 Github:https://github.com/kingfengji/gcForest Website:http://lamda.nju.edu.cn/code_gcForest.ashx
南京大学机器学习与数据挖掘研究所提供了基于Python 2.7
多粒度级联森林算法解读
多粒度级联森林的结构主要分为多粒度扫描、级联森林两个部分。
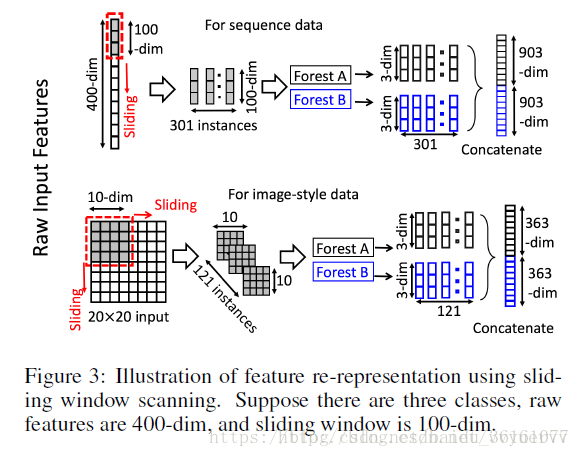
从上面的图可以看出,假设原始数据是400维的,然后分别用大小为100,200,300的窗口进行滑动,分别得到301 * 100,201 *100, 101 * 100的数据,也就是得到了301,201,101个实例为100维,200维,300维的子样本数据,这些数据其实都是一个样本里面的特征,不是有301个样本,不过这里为了好理解就将这301个当成了子样本,这一步有点k折交叉采样的意思,然后分别将这批数据送到级联随机森林里面,这里的随机森林是成对出现的,一个是普通随机森林一个是完全随机森林,为了增加集成学习的多样性。完全随机森林和普通随机森林的不同点在于,完全随机森林中的每棵树通过随机选择一个特征在树的每个节点进行分割实现生成,树一直生长,直到每个叶节点只包含相同类的实例或不超过10个实例。类似地,普通每个随机森林也包含1000棵树,通过随机选择数量的特征作为候选(d是输入特征的数量),然后选择具有最佳 gini 值的特征作为分割。每个森林中的树的数值是一个超参数。假设一个随机森林的分类之后的类别个数是3个,一个样本经过一个随机森林后就得到了一个3维的概率分布,之前我们分别得到了301,201,101个样本,那么这3批样本进入一个随机森林以后得到的概率就有903,603,303个了,图中每一批次用了2个随机森林,那么最后得到的概率的个数就有了903 X 2, 603 X 2, 303 X 2.然后将这些概率拼接称一个,就变成了一个3618dim的数据了,到这里,多粒度扫描的步骤完成了,多粒度扫描的过程就相当于特征的提取,下面是级联森林的过程了。可以看作一个smote过程。
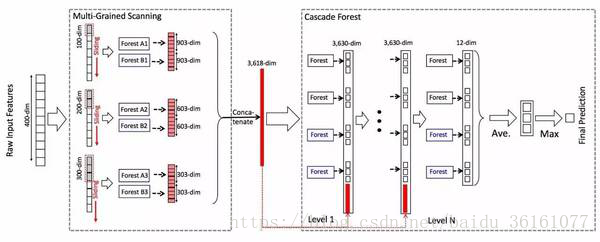
将得到的3618维的数据x送到随机森林里面,每个随机森林又得到了一个3维的数据,图中level 1用了4个随机森林,其中上面两个黑色的是完全随机森林,下面的两个是普通随机森林,这样就得到了4个3维的密度数据,再将原先的x,拼接起来就变成了3618 + 12 = 3630维的数据了,将这个数据作为下一层的输入,之后又得到4个3维的数据,再和原始的x拼接,得到3630维的术数据,作为下一层的输入,这样传递到最后一层,就不用将原来的数据再拼接起来了,因为它是最后一层了,不需要再拼接起来作为下一层的输入了,最后输出4个3维的数据,将这4个3维的数据取平均,得到一个3维的数据,然后在这个3维的数据里面取最大的,作为预测。整个多粒度级联森林的层数是自适应调节的,在级联森林的构造阶段,只要构造当前层时,经过交叉验证的验证准确率相比于前一层没有提升,那么级联森林的构造就此停止,整个结构也就完成了。
-
注: 多粒度扫描实际上是一个类似卷积滑窗极限特征提取和过采样的过程, 经过特征之间的不断卷积和过采样,该过程极耗内存,一味追求精准度。
总结
树模型是生成规则的利器,但是由于数据量不足和样本的噪声和错误,可能会造成提取出来的规则错误。