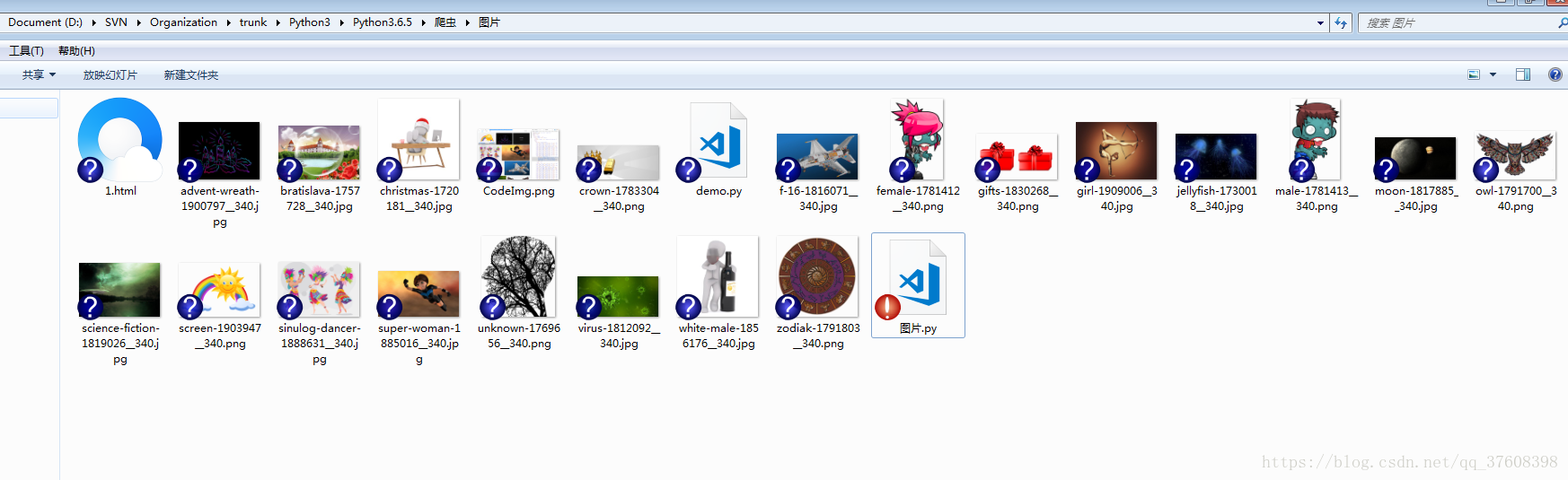
Python3抓取网页图片
爬取的路径:URL = https://pixabay.com/zh/editors_choice/?media_type=illustration&pagi=3 (通过多次调试发现这个pagi值是个变量,表示页数,抓取其他页数图片可以修改这个值,或者循环抓取),废话不多说,
原页面图片:
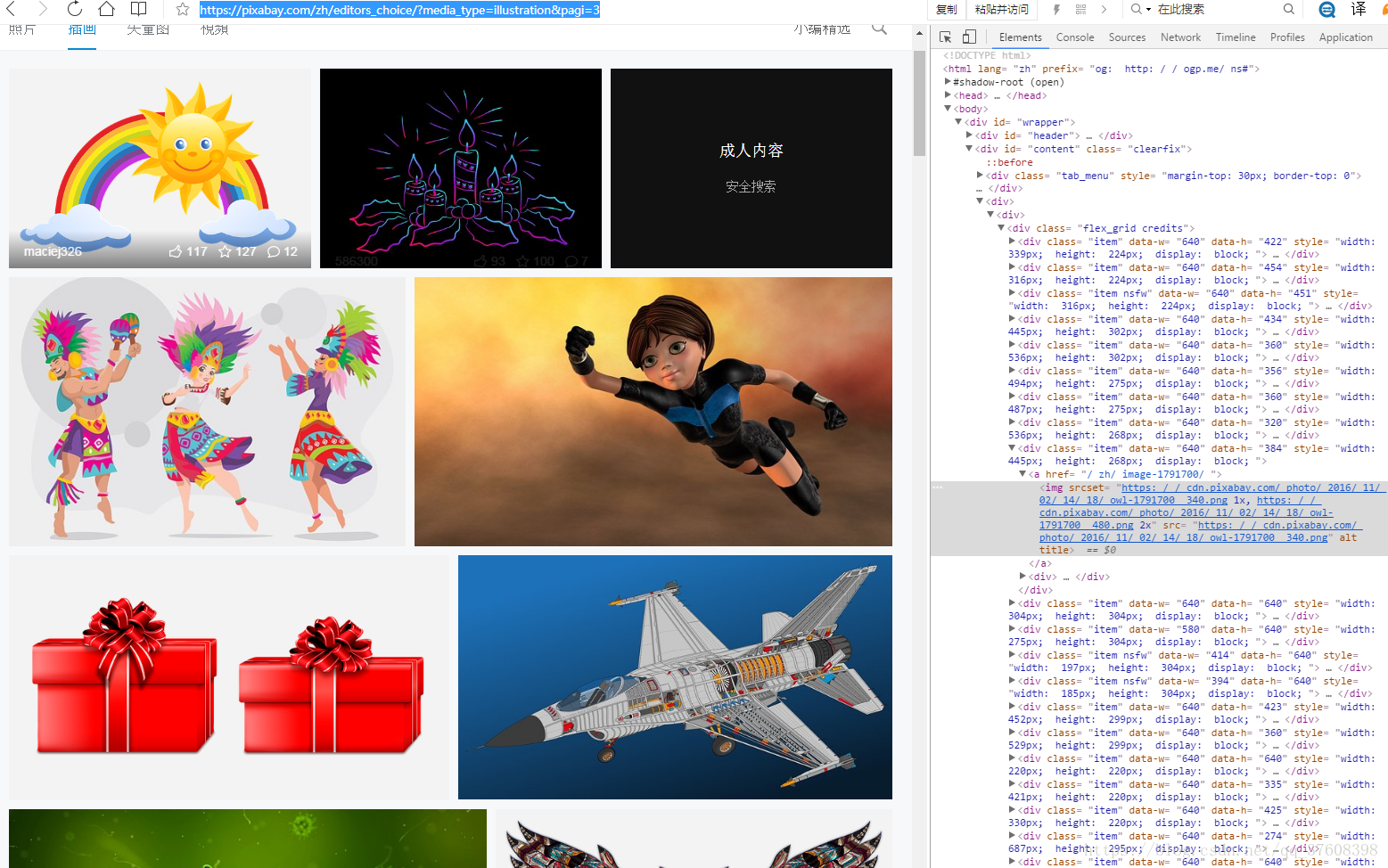
代码如下:
#coding:utf-8
import requests
import re
import urllib
import os
from bs4 import BeautifulSoup
url = 'https://pixabay.com/zh/editors_choice/?media_type=illustration&pagi=3'
cookies = {
'Cookie':'bid=_lOjPCNt9wI; ll="118282"; _vwo_uuid_v2=90A455F697D39C4E7ADE716F87221D41|b2cfd7bec4a7b17a840474041b898d19; __utmc=30149280; _ga=GA1.2.1644812988.1515427525; _gid=GA1.2.1120993180.1526163442; push_noty_num=0; push_doumail_num=0; ct=y; __yadk_uid=1UDWf6kQP5PYke9rFuHb2klf4KbW2B5R; _pk_ses.100001.8cb4=*; __utma=30149280.1644812988.1515427525.1526171405.1526171405.1; __utmz=30149280.1526171405.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmt=1; dbcl2="178599165:Y53LLRSxUvs"; _gat_UA-7019765-1=1; ck=QzdS; _pk_id.100001.8cb4=8ab848a65c47cc4a.1526171404.1.1526171408.1526171404.; __utmv=30149280.17859; __utmb=30149280.3.10.1526171405'
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4882.400 QQBrowser/9.7.13059.400'
}
def getCode(url):
r = requests.get(url,cookies = cookies, headers = headers)
# print(r.status_code)
# print(r.)
r.encoding = 'UTF-8'
tmp = r.text
return tmp
def getHtmlTree(url):
tmp = getCode(url)
htmlTree = BeautifulSoup(tmp,"html.parser")
return htmlTree
def getUrlList(url):
HtmlTree = getHtmlTree(url)
imgList = HtmlTree.find_all('img')
UrlList = []
for imgUrl in imgList:
if imgUrl.get('src') :
UrlList.append(imgUrl.get('src'))
return UrlList
def saveImg(url):
try:
img = requests.get(url,cookies = cookies, headers = headers)
except requests.exceptions.MissingSchema:
print('路径异常!')
return
flag = url.split('/')
print(flag[-1])
imgName = flag[-1]
f = open(imgName,'wb')
f.write(img.content)
f.close()
# cmd = 'del /q /s *.png'
# cmd1 = 'del /q /s *.jpg'
# os.system(cmd)
# os.system(cmd1)
if __name__ == '__main__':
UrlList = getUrlList(url)
for url in UrlList:
saveImg(url)
下载下来的效果图: