一python简单了解:
Python是跨平台的,它可以运行在Windows、Mac和各种Linux/Unix系统上。在Windows上写Python程序,放到Linux上也是能够运行的。
pyton可以爬虫,爬虫是属于运营的比较多的一个场景吧,有一个库叫 Requests ,这个库是一个模拟HTTP请求的一个库,非常的出名! 爬取后的数据分析与计算是Python最为擅长的领域,非常容易整合。不过目前Python比较流行的网络爬虫框架是功能非常强大的scrapy。
二开发工具
IDE : pycharm
附链接:http://www.jetbrains.com/pycharm/?fromMenu
Pycharm: PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。
三单独安装的第三方模块
2.1通过pip命令安装各种包
pip 是 Python 包管理工具,该工具提供了对Python 包的查找、下载、安装、卸载的功能。
2.2pip install requests
释义:Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,Requests它会比urllib更加方便,可以节约我们大量的工作。
2.3pip intsall BeautifulSoup4
释义:Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
2.4pip install pillow
释义:PIL:Python Imaging Library,已经是Python平台事实上的图像处理标准库了。PIL功能非常强大,但API却非常简单易用。
四 源码
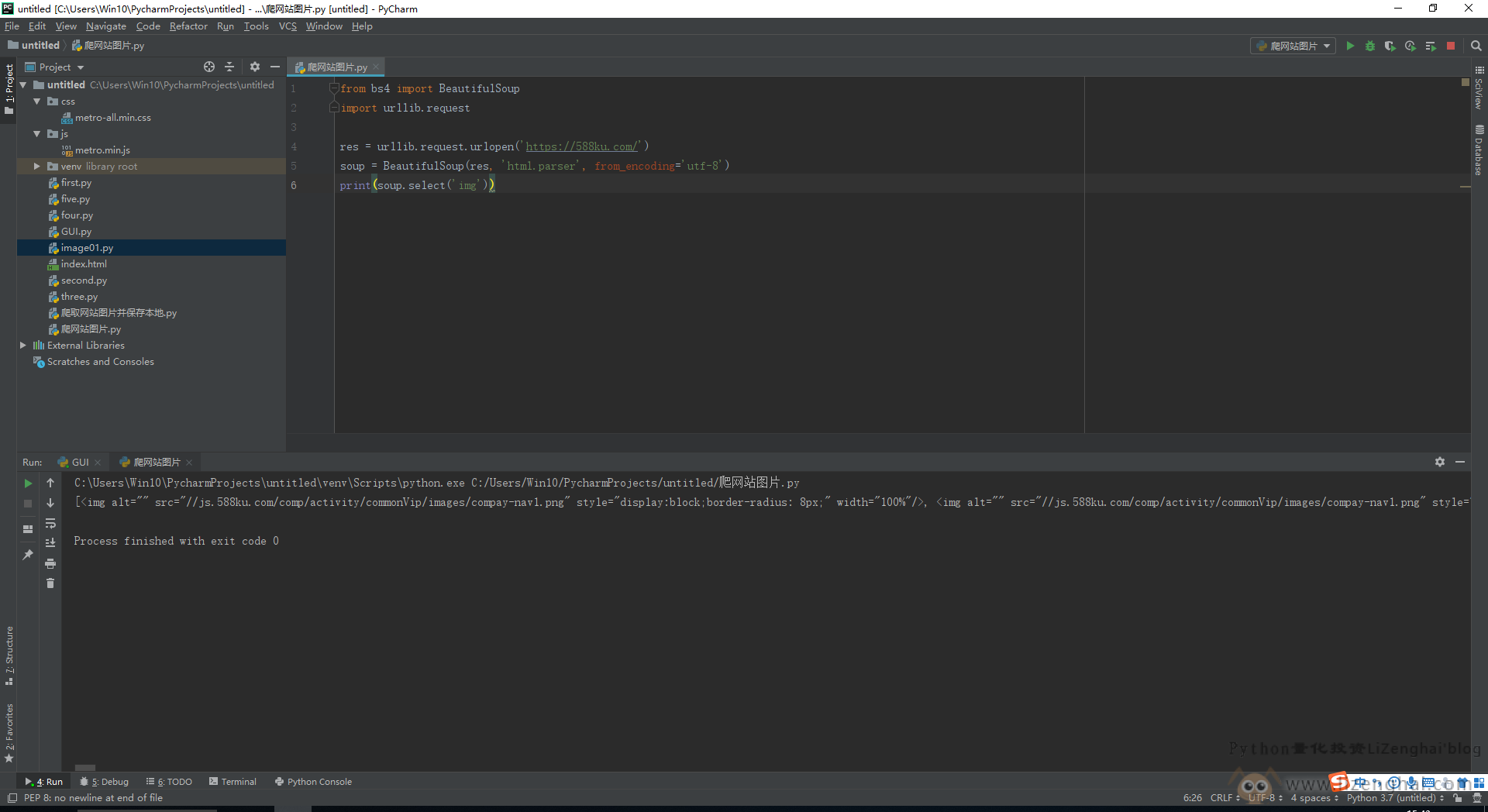
from bs4 import BeautifulSoup
import urllib.request
res = urllib.request.urlopen(‘https://588ku.com/’)
soup = BeautifulSoup(res, ‘html.parser’, from_encoding=’utf-8′)
print(soup.select(‘img’))
五学Python后到底能干什么?
运维、web开发、应用开发、大数据、数据挖掘、科学计算、机器学习、人工智能、自然语言处理……
Python开发:侧重于测试、运维方向,课程涵盖网络编程、数据库操作、网络爬虫、网络监控、 自动化测试、自动化运维等Python最主流的技术。
Python+大数据:即Python企业级开发与大数据运维,作为和大数据运维无缝结合的语言, Python+大数据才是真正的大数据。
我是琉璃 在互联网行走的程序媛 小小人儿 大大梦想
好了,今天暂时分享到这里,不定期更新~~