自然语言处理笔记总目录
论文地址:BERT
何为BERT
BERT,全称Bidirectional Encoder Representation from Transformers,是2018年10月由Google AI研究院提出的一种预训练模型。
BERT在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且在11种不同NLP测试中创出SOTA表现。包括将GLUE基准推高至80.4% (绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进5.6%)。成为NLP发展史上的里程碑式的模型成就。
BERT的架构
如下图最左所示,BERT采用了Transformer Encoder block进行连接,是一个双向编码模型
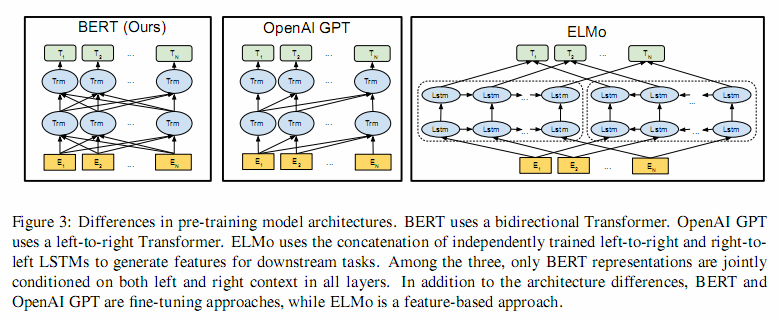
从BERT架构图中可以看到,宏观上BERT分三个主要模块:
- 最底层黄色标记的Embedding模块
- 中间层蓝色标记的Transformer模块
- 最上层绿色标记的预微调模块
Embedding模块:BERT中的该模块是由三种Embedding共同组成而成,如下图

- Token Embeddings 是词嵌入张量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings 是句子分段嵌入张量,是为了服务后续的两个句子为输入的预训练任务
- Position Embeddings 是位置编码张量,此处注意和传统的Transformer不同,不是三角函数计算的固定位置编码,而是通过学习得出来的.
- 整个Embedding模块的输出张量就是这3个张量的直接加和结果
- 双向Transformer模块:BERT中只使用了经典Transformer架构中的Encoder部分,完全舍弃了Decoder部分。而两大预训练任务也集中体现在训练Transformer模块中
预微调模块:
- 经过中间层Transformer的处理后,BERT的最后一层根据任务的不同需求而做不同的调整即可
- 比如对于sequence-level的分类任务,BERT直接取第一个 [CLS] token 的final hidden state,再加一层全连接层后进行softmax来预测最终的标签
对于不同的任务,微调都集中在预微调模块,BERT论文中几种重要的NLP微调任务架构图展示如下
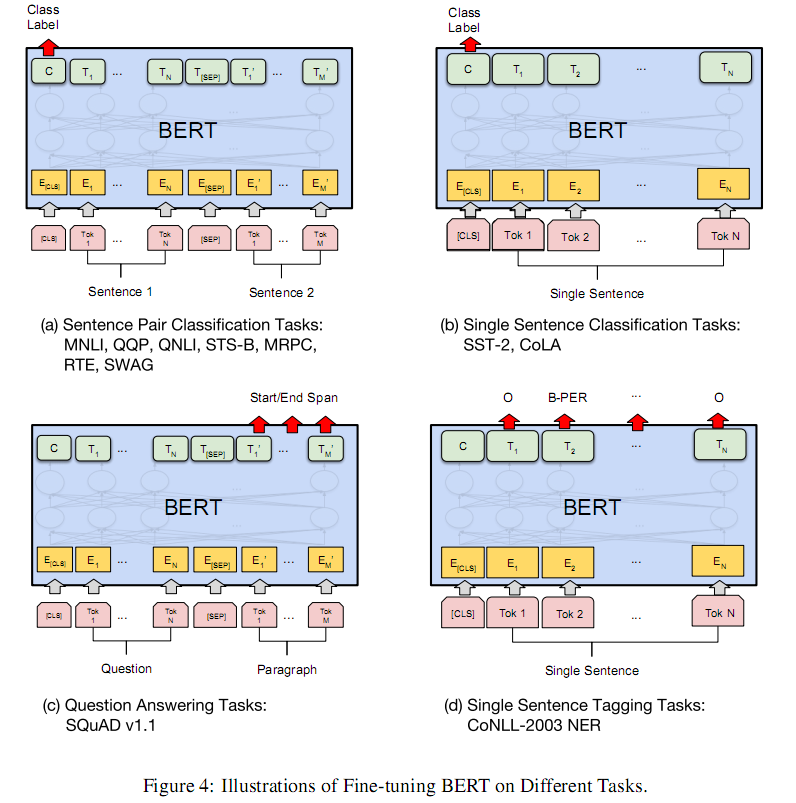
从上图中可以发现,在面对特定任务时,只需要对预微调层进行微调,就可以利用Transformer强大的注意力机制来模拟很多下游任务,并得到SOTA的结果。
(句子对关系判断,单文本主题分类,问答任务(QA),单句贴标签(NER))
若干可选的超参数建议如下:
Batch size: 16, 32
Learning rate (Adam): 5e-5, 3e-5, 2e-5
Epochs: 3, 4
BERT的预训练任务
BERT包含两个预训练任务:
- 任务一:Masked LM (带mask的语言模型训练)
- 任务二:Next Sentence Prediction (下一句话预测任务)
任务一:Masked LM (带mask的语言模型训练)
- 关于传统的语言模型训练,都是采用left-to-right,或者left-to-right + right-to-left结合的方式,但这种单向方式或者拼接的方式提取特征的能力有限。为此BERT提出一个深度双向表达模型(deep bidirectional representation)。即采用MASK任务来训练模型
- 1:在原始训练文本中,随机的抽取15%的token作为参与MASK任务的对象
- 2:在这些被选中的token中,数据生成器并不是把它们全部变成[MASK],而是有下列3种情况
- 2.1:在80%的概率下,用[MASK]标记替换该token,比如 my dog is hairy → \rightarrow → my dog is [MASK]
- 2.2:在10%的概率下,用一个随机的单词替换token,比如 my dog is hairy → \rightarrow → my dog is apple
- 2.3:在10%的概率下,保持该token不变,比如 my dog is hairy → \rightarrow → my dog is hairy
- 3:模型在训练的过程中,并不知道它将要预测哪些单词?哪些单词是原始的样子?哪些单词被遮掩成了[MASK]?哪些单词被替换成了其他单词?正是在这样一种高度不确定的情况下,反倒逼着模型快速学习该token的分布式上下文的语义,尽最大努力学习原始语言说话的样子。同时因为原始文本中只有15%的token参与了MASK操作,并不会破坏原语言的表达能力和语言规则。
任务二:Next Sentence Prediction (下一句话预测任务)
- 在NLP中有一类重要的问题比如QA(Quention-Answer),NLI(Natural Language Inference),需要模型能够很好的理解两个句子之间的关系,从而需要在模型的训练中引入对应的任务。在BERT中引入的就是Next Sentence Prediction任务。采用的方式是输入句子对(A, B),模型来预测句子B是不是句子A的真实的下一句话
- 1:所有参与任务训练的语句都被选中作为句子A
- 1.1:其中50%的B是原始文本中真实跟随A的下一句话。(标记为IsNext, 代表正样本)
- 1.2:其中50%的B是原始文本中随机抽取的一句话。(标记为NotNext, 代表负样本)
- 2:在任务二中,BERT模型可以在测试集上取得97%-98%的准确率