import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs#这里我们创建了50个数据点,并将它们分为了2类
x,y=make_blobs(n_samples=50,centers=2,random_state=6)
print('x',x[:2])
print('y',y[:2])make_blobs函数是为聚类产生数据集,产生一个数据集和相应的标签
n_samples:表示数据样本点个数,默认值100
n_features:是每个样本的特征(或属性)数,也表示数据的维度,默认值是2
centers:表示类别数(标签的种类数),默认值3
cluster_std表示每个类别的方差,例如我们希望生成2类数据,其中一类比另一类具有更大的方差,可以将cluster_std设置为[1.0,3.0],浮点数或者浮点数序列,默认值1.0
center_box:中心确定之后的数据边界,默认值(-10.0, 10.0)
shuffle :将数据进行洗乱,默认值是True
random_state:官网解释是随机生成器的种子,可以固定生成的数据,给定数之后,每次生成的数据集就是固定的。若不给定值,则由于随机性将导致每次运行程序所获得的的结果可能有所不同。在使用数据生成器练习机器学习算法练习或python练习时建议给定数值。
#构建一个内核为线性的支持向量机模型
clf = svm.SVC(kernel='linear',C=1000) C:惩罚项参数,C越大, 对误分类的惩罚越大(泛化能力越弱)
kernel:核函数类型
linear:线性核函数
poly:多项式核函数
rbf: 高斯核函数
sigmoid: sigmod核函数
degree:多项式核函数的阶数.
gamma: 核函数系数,默认为auto(代表其值为样本特征数的倒数), 只对’rbf’,‘poly’,'sigmod’有效.定义了单个训练样本有多大的影响力.一个大的gamma,其附近的其他样本一定会被影响到.
class_weight:{dict,‘balanced’},可选类别权重.
decision_function_shape:‘ovo’(默认,one vs one),‘ovr’(one vs reset).
clf.fit(x,y)
#画图
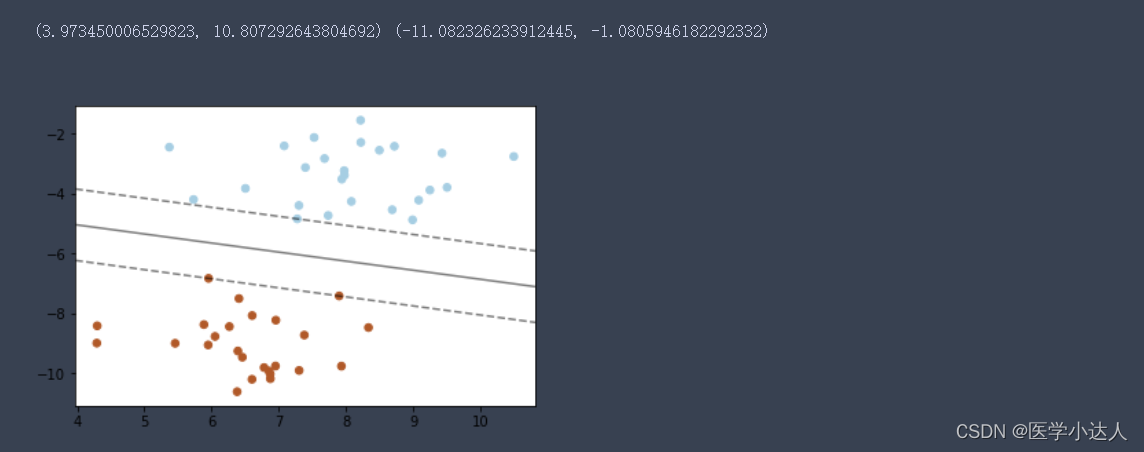
plt.scatter(x[:,0],x[:,1],c=y,s=30,cmap=plt.cm.Paired)
#建立图形坐标
ax=plt.gca()
xlim=ax.get_xlim()#获取数据点x坐标的最大值和最小值
ylim=ax.get_ylim()#获取数据点y坐标的最大值和最小值
print(xlim,ylim)
#根据坐标轴生成等差数列(这里是对参数进行网格搜索)
xx=np.linspace(xlim[0],xlim[1],30)
yy=np.linspace(ylim[0],ylim[1],30)
YY,XX=np.meshgrid(yy,xx)
xy=np.vstack([XX.ravel(),YY.ravel()]).T
Z=clf.decision_function(xy).reshape(XX.shape)
#画出分类的边界
ax.contour(XX,YY,Z,colors='K',levels=[-1,0,1],alpha=0.5,linestyles=["--","-","--"])
ax.scatter(clf.support_vectors_[:,0],clf.support_vectors_[:,1],s=100,linewidths=1,facecolors="none")
plt.show()结果: