CAVLC-CAVLC概念
CAVLC的全称是Context-Adaptive Varialbe-Length Coding,即基于上下文的自适应变长编码。CAVLC的本质是变长编码,它的特性主要体现在自适应能力上,CAVLC可以根据已编码句法元素的情况动态的选择编码中使用的码表,并且随时更新拖尾系数后缀的长度,从而获得极高的压缩比。H.264标准中使用CAVLC对4×4模块的亮度和色度残差数据进行编码。
CAVLC-CAVLC原理
在H.264标准编码体系中,视频图像在经过了预测、变换及量化编码后表现出如下的特性:4×4块残差数据块比较稀疏,其中非零系数主要集中在低频部分,而高频系数大部分是零;量化后的数据经过zig-zag扫描,DC系数附近的非零系数值较大,而高频位置上的非零系数值大部分是+1和-1;相邻的4×4块的非零系数的数目是相关的。CAVLC就是利用编码后残差数据的这些特性,通过自适应对不同码表的选择,利用较少的编码数据对残差数据进行无损的熵编码,进一步减少了编码数据的冗余和相关性,提高了H.264的压缩效率。
CAVLC-CAVLC编码流程
视频图像在经过预测、变换和量化编码后,需要经过Zig-zag扫描和重新的排序过程,为后序的CAVLC编码进行准备。一个残差数据块的CAVLC熵编码的流程如图所示:
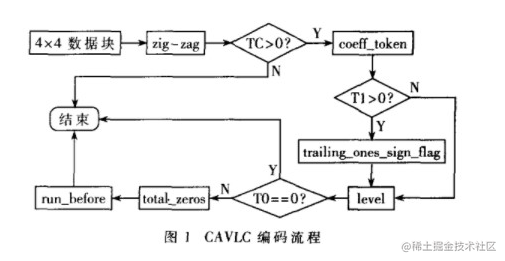
CAVLC熵编码处理流程
1、TotalCoeffs和TrailingOnes的编码
从码流的起始位置开始计算整个编码块中非零系数的数目(TotalCoeffs),非零系数的数目为从0-16,非零系数的数目被赋值给变量TotalCoeffs。 拖尾系数是指码流中正或者负1的个数(+/-1)。拖尾系数的数目(TrailingOnes)被限定在3个以内,如果+/-1的数目超过3个,则只有最后3个被视为拖尾系数,其余的被视为普通的非零系数,拖尾系数的数目被赋值为变量TrailingOnes。
2、判断计算nC值
nC(Number Current 当前块值)值的计算集中体现了CAVLC的基于上下文的思想,通过nC值选择不同H.264标准附录CAVLC码表。
3、查表获得coeff_token编码
根据之前编码和计算过程所得的变量TotalCoeffs、TrailingOnes和nC值可以查H.264标准附录CAVLC码表,即可得出coeff_token编码序列。
4、编码每个拖尾系数的符号:前面的coeff_token编码中已经包含了拖尾系数的总数,还需进一步对拖尾系数的符号进行编码。由于拖尾系数符合为正(+)或负(-),因此,在H.264标准中规定用0表示正1(+1)、1表示负1(-1)。当拖尾系数的数目超过3个只有最后3个被认定为拖尾系数,因此对符号的编码顺序应按照反向扫描的顺序进行。
5、编码除拖尾系数之外的非零系数的幅值(Levels)
非零系数的幅值(Levels)由两个部分组成:前缀(level_prefix)和后缀(level_suffix)。levelCode、levelSuffixsSize和suffixLength是编码过程中需要使用的三个变量,其中levelCode是中间过程中用到的无符号数,levelSuffixsSize表示后缀长度位数,suffixLength代表Level的码表序号。
6、编码最后一个非零系数前零的数目(TotalZeros)
TotalZeros指的是在最后一个非零系数前零的数目,此非零系数指的是按照正向扫描的最后一个非零系数。因为非零系数数目(TotalCoeffs)是已知,这就决定了TotalZeros可能的最大值。根据TotalCoeffs值,H.264标准共提供了25个变长表格供查找,其中编码亮度数据时有15个表格供查找,编码色度DC 2×2块(4:2:0格式)有3个表格、编码色度DC 2×4块(4:2:2格式)有7个表格。
7、编码每个非零系数前零的个数(RunBefore)
在CAVLC中,变量 ZerosLeft表示当前非零系数左边的所有零的个数,ZerosLeft的初始值等于TotalZeros。每个非零系数前零的个数(RunBefore)是按照反序来进行编码的,从最高频的非零系数开始。H.264标准中根据不同ZerosLeft和RunBefore,构建了RunBefore编码表格供编码查找使用。根据表格每编码完一个RunBefore,对ZerosLeft的值进行更新,继续编码下一个RunBefore,直至全部完成所有非零系数前零的个数的编码。当ZerosLeft=0即没有剩余0需要编码时或者只有一个非零系数时,均不需要再进行RunBefore编码。
CAVLC-CAVLC解码流程
CAVLC熵解码是上述CAVLC熵编码的逆过程,CAVLC熵解码的输入数据是来自片层数据的比特流,解码的基本单位是一个4×4的像素块,输出为包含4×4块每个像素点所有幅值的序列。CAVLC解码步骤如下:

- 初始化所有的系数幅值
- 解码非零系数个数(TotalCoeff)和拖尾系数个数(TrailingOnes)。
- 解码拖尾系数符号(trailing_ones_sign_flag)
- 解码非零系数幅值
- 解码total_zeros和run_before
- 组合非零系数幅值和游程信息,得到整个残差数据块
上下文自适应的变长编码(CAVLC)
CAVLC的全称叫做“上下文自适应的变长编码Context-based Adaptive Variable Length Coding”。所谓“上下文自适应”,说明了CAVLC算法不是像指数哥伦布编码那样采用固定的码流-码字映射的编码,而是一种动态编码的算法,因而压缩比远远超过固定变长编码UVLC等算法。
在H.264标准中,CAVLC主要用于预测残差的编码。在本系列第二篇博文中我们给出了H.264的编码流图,其中可知,熵编码的输入为帧内/帧间预测残差经过变换-量化后的系数矩阵。以4×4大小的系数矩阵为例,经过变换-量化后,矩阵通常呈现以下特性:
- 经过变换量化后的矩阵通常具有稀疏的特性,即矩阵中大多数的数据已0为主。CAVLC可以通过游程编码高效压缩连续的0系数串;
- 经过zig-zag扫描的系数矩阵的最高频非0系数通常是值为±1的数据串。CAVLC可以通过传递连续的+1或-1的长度来高效编码高频分量;
- 非零系数的幅值通常在靠近DC(即直流分量)部分较大,而在高频部分较小;
- 矩阵内非0系数的个数同相邻块相关;
熵编码回顾
熵编码:
- 无损编码:解码后可无失真还原信源信息;
- 利用信源符号的概率特性,使编码后的信息尽可能接近信源的熵;
常见熵编码方法:
- 变长编码:哈夫曼编码、香农-费诺编码、指数哥伦布编码;
- 算数编码;
CAVLC
上下文自适应的变长编码:
用于亮度和色度预测残差的编码,以量化后的变换系数的形式; 变换系数矩阵的特征:
- 稀疏:矩阵元素以0为主;
- 非零系数集中于低频;
- 高频部分的非零系数大部分为±1;
- 非零系数个数同相邻块有关;
CAVLC的上下文模型:
- 编码非零系数的表格索引;
- 更新编码非零系数时的后缀长度
CALVC的编码过程
编码需要的重要元素:
一般都是以4X4的宏块做编码,所以下面是0~16
- 非零系数的个数(TotalCoeffs):取值范围为[0, 16],即当前系数矩阵中包括多少个非0值的元素;
- 拖尾系数的个数(TrailingOnes):取值范围为[0, 3],表示最高频的几个值为±1的系数的个数,如果±1 的个数大于 3 个,只有最后 3 个被视为拖尾系数,其余的被视为普通的非零系数。
- 拖尾系数的符号:以1 bit表示,0表示+,1表示-;
- 当前块值(numberCurrent):用于选择编码码表,由上方和左侧的相邻块的非零系数个数计算得到。普通非0系数的幅值(level):幅值的编码分为prefix和suffix两个部分进行编码。编码过程按照反序编码,即从最高频率非零系数开始。
- 最后一个非0系数之前的0的个数(TotalZeros);
- 每个非0系数之前0的个数(RunBefore):按照反序编码,即从最高频非零系数开始;对于最后一个非零系数(即最低频的非零系数)前的0的个数,以及没有剩余的0系数需要编码时,不需要再继续进行编码。
系数矩阵Z形扫描
CAVLC对一个固定大小的系数矩阵进行编码,例如:
{
3, 2, -1, 0,
1, 0, 1, 0,
-1, 0, 0, 0,
0, 0, 0, 0,
}
扫描:
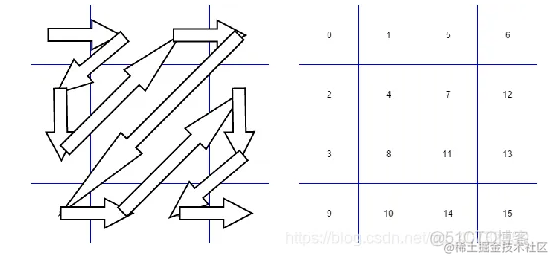
扫描重排之后得到一维数组:[3, 2, 1, -1, 0, -1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
编码过程
- 确定当前块值nC,选择coeff_token的码表;
- 根据非零系数个数TotalCoeffs和拖尾系数个数TrailingOnes,编码coeff_token;
- 编码拖尾系数的符号;
- 编码拖尾系数之外的普通非零系数;
- 编码最末非零系数之前0的总个数;
- 编码每个非零系数之前的0的个数;
CAVLC解析残差过程
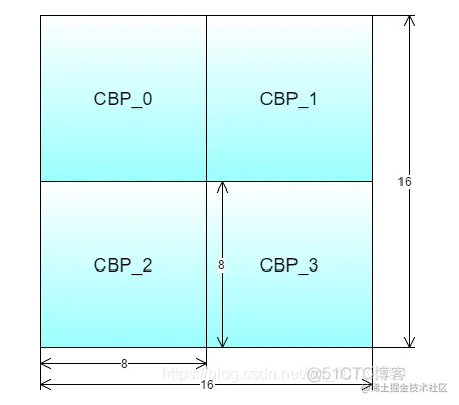
在编码残差时对宏块的分割:
- cbp:表示一个8×8像素块是否进行编码;
- block:CAVLC编码的基本单元为4×4,在一个cbp表示的块中进一步分割
使用CAVLC解析宏块残差语法元素的顺序:
- numCoeff, trailingOnes;
- levels;
- totalZeros;
- runBefore;
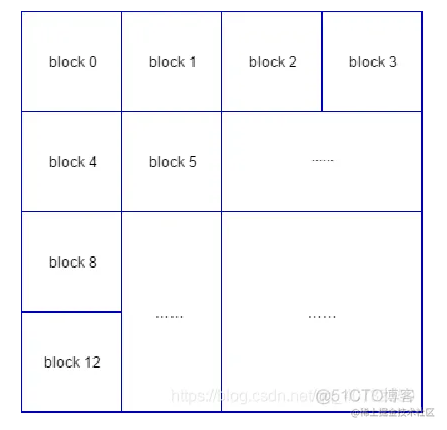
编码上下文的确定与相邻块的有效性
在解析coeffToken时,码表的选择依赖于上下文信息; 决定上下文的信息由相邻块获取,主要是块中非0系数的个数; 块的有效和无效:
- Slice上边沿宏块的0、1、2、3号块,其上邻块无效;
- Slice左边沿宏块的0、4、8、12号块,其左邻块无效;
- Slice左上宏块的0号块,其左、上邻块均无效;
色度块、Intra16x16模式的解析
色度块、Intra16x16模式块的解析思想类似4x4亮度块:
- 依次解析numCoeff、trailingOnes、trailingSigns、levels、totalZeros、runBefore;
不同之处:
- 每个单元内系数数量最大值;
- AC/DC是否分别解析;
- nC值的计算方法;
不同分割模式的比较

文末
CAVLC属于熵编码。熵编码是一种无损压缩编码方法,它生成的码流可以经解码无失真地恢复出原数据。熵编码是建立在随机过程的统计特性基础上的,因此它主要为了降低数据的统计冗余。
在 H.264 的 CAVLC(基于上下文自适应的可变长编码)相比于huffman编码,它可以通过根据已编码句法元素的情况自适应调整当前编码中使用的码表,从而取得了极高的压缩比。