OneEE: A One-Stage Framework for Fast Overlapping and Nested Event Extraction

论文:https://arxiv.53yu.com/pdf/2209.02693.pdf
代码:https://github.com/Cao-Hu/OneEE (代码未上传)
期刊/会议:COLING 2022
摘要
事件抽取(EE)是信息抽取的基本任务,旨在从非结构化文本中抽取结构化事件信息。大多数先前的工作集中于抽取平面事件,而忽略了重叠或嵌套的事件。一些用于重叠和嵌套EE的模型包括几个抽取事件触发词和论元的连续阶段,这些阶段会受到错误传播的影响。因此,我们设计了一个简单而有效的标注方案和模型来表述EE作为词-词关系识别,称为OneEE。通过并行网格标记,在一个阶段内同时识别触发词和论元词之间的关系,从而获得非常快的事件抽取速度。该模型采用自适应事件融合模块生成事件感知表示,采用距离感知预测器集成相对距离信息进行词-词关系识别,并通过实例验证了这两种机制的有效性。在3个重叠和嵌套的EE基准(即FewFC、Genia11和Genia13)上进行的实验表明,OneEE实现了最先进的(SoTA)结果。此外,在相同条件下,OneEE的推理速度比基线的推理速度快,由于支持并行推理,可以进一步大幅度提高推理速度。
1、简介
图1展示了现有事件抽取的情况,大致可以分为Flat Event,Overlapped Event,Nested Event三种。传统的方法常将EE看成序列标注任务,不能有效解决事件提及的重叠问题,如图1中的(b)所示,两个重叠的事件共享触发词acquired。图1中的©展示了嵌套事件的例子,其中Gene Expression事件是另一个Positive Regulation事件的Theme论元。

重叠和嵌套EE的前期研究(Yang et al, 2019;Li et al,2020)采用基于管道的方法,在几个连续的阶段抽取事件触发词和论元。最近,最先进的模型Sheng等人(2021)也使用了这样一种连续执行事件类型检测、触发词抽取和论元抽取的方法。这种方法的主要问题是后一阶段依赖于前一阶段,这固有地带来了误差传播问题。
为了解决上述问题,我们提出了一种新的标记方案,将重叠和嵌套的EE转换为词-词关系识别。如图2所示,我们设计了两种类型的关系,包括跨度关系(S-*)和角色关系(R-*)。S-*处理触发词和论元识别,表示两个单词是触发词(T)的头尾边界还是论元(a)的头尾边界。R-*处理论元角色分类,表示论元是否在事件中扮演“*”角色。

在此基础上,我们进一步提出了一个单阶段事件抽取模型,该模型主要包括三个部分。首先,它采用BERT (Devlin et al, 2019)作为编码器来获得上下文化的单词表示。然后,使用自适应事件融合层(由一个注意模块和两个门融合模块组成)获得每种事件类型的事件感知上下文表示。在预测层,我们通过计算距离感知分数,并行预测每对单词之间的跨度和角色关系。最后,可以在一个阶段中使用这些关系标签解码事件触发词、论元及其角色,而不会出现错误传播。
我们在3个重叠和嵌套的EE数据集上评估了OneEE (FewFC (Zhou et al, 2021), Genia11 (Kim et al, 2011)和Genia13),并进行了广泛的实验和分析。
- 我们设计了一种新的标记方案,将事件抽取转换为单词-单词关系识别任务,为重叠和嵌套的EE提供了一种新颖而简单的解决方案。
- 我们提出了OneEE,这是一个单阶段模型,可以有效地并行抽取重叠和嵌套EE的词-词关系。
- 我们进一步提出了自适应事件融合层,以获得事件感知的上下文表示,并有效地集成事件信息。
- OneEE在性能和推理速度方面都优于SoTA模型。
2、相关工作
2.1 事件抽取
传统的EE(即扁平或常规事件抽取)(Li et al, 2013; Nguyen et al, 2016; Liu et al, 2018; Sha et al, 2018; Nguyen and Nguyen, 2019)将EE制定为序列标记任务,为每个token分配标签(例如,BIO标记方案)。例如,Nguyen等人(2016)使用两个双向RNN来获得更丰富的表示,然后将其用于联合预测事件触发词和论元角色。Liu等人(2018)通过引入基于注意的GCN来对依赖图信息建模,联合抽取了多个事件触发词和论元(Fei et al, 2021b; Li et al, 2021a; Fei et al, 2022b)。然而,他们的基本假设,事件提及不相互重叠,并不总是有效的。不规则的EE(即重叠和嵌套的EE)并没有受到太多的关注,这更具有挑战性和现实意义。
现有的重叠和嵌套EE的方法(Yang et al, 2019; Li et al, 2020)以管道方式执行事件抽取,有几个步骤。为了解决论点重叠,Yang等人(2019)采用多组二元分类器,其中每个severs为一个角色检测特定于角色的论元范围,但无法解决触发词重叠。除了管道方法外,处理重叠EE的最新尝试是Sheng等人(2021)在级联解码的联合框架中。他们是第一个同时处理所有重叠模式的。Sheng等人(2021)依次执行类型检测、触发词抽取和论元抽取,其中重叠的目标根据特定的前一个预测分别抽取。然而,大多数多级方法都存在误差传播问题。
2.2 基于标记的信息抽取
标记方案在信息抽取领域得到了广泛的研究。传统的序列标记方法(例如BIO)很难处理不规则的信息抽取(例如重叠的NER)。一些研究人员(Zheng et al, 2017)扩展了BIO标签方案,以适应更复杂的场景。然而,由于有限的灵活性,它们受到标签歧义问题的困扰。近年来,网格标记方案由于其呈现词对之间关系的特点,被应用于许多信息抽取任务中,如意见挖掘(Wu et al, 2020)、关系抽取(Wang et al, 2020)和命名实体识别(Wang et al, 2021)。例如,TPLinker (Wang et al, 2020)通过用链接标签标记token对,实现了在训练和推理之间没有间隙的单阶段联合关系抽取。受这些工作的启发,我们设计了标签方案来解决重叠和嵌套的EE,它在一个阶段平行预测触发词或论元词之间的关系。
同样值得注意的是,这项工作继承了最近成功的词-词关系检测思想,如Li等人(2022b)。Li等人(2022b)提出用基于网格标注方案的词-词建模统一所有的NER(包括扁平提及、嵌套提及和不连续提及)。然而,这项工作与Li等人(2022b)在两个方面有所不同。首先,我们成功地将词-词标记的思想从NER扩展到EE,其中我们为嵌套和重叠的事件重新设计了两种关系类型。其次,从建模的角度,设计了自适应事件融合层,完全支持单阶段(端到端)复杂事件检测,极大地避免了错误的传播。
3、问题定义
事件抽取的目标包括抽取事件触发词及其论元。我们可以将重叠和嵌套EE形式化如下:给定一个由 N N N个标记或单词组成的输入句子 X = { x 1 , x 2 , … , x N } X = \{x_1, x_2,\ldots, x_N\} X={ x1,x2,…,xN}和事件类型 e ∈ E e∈\mathcal{E} e∈E,任务旨在抽取每个token对 ( x i , x j ) (x_i, x_j) (xi,xj)之间的跨度关系 S \mathcal{S} S和角色关系 R \mathcal{R} R,其中 E \mathcal{E} E表示事件类型集合, S \mathcal{S} S和 R \mathcal{R} R为预定义标签。这些关系可以在下面解释,为了更好地理解,我们还提供了如图2所示的示例。
- S \mathcal{S} S: span关系表示 x i x_i xi和 x j x_j xj是所抽取的触发词跨度S-T或论元跨度S-A的起始和结束标记,其中 1 ≤ i ≤ j ≤ N 1≤i≤j≤N 1≤i≤j≤N。
- R \mathcal{R} R:角色关系表示带有 x j x_j xj的论元充当触发词包含 x i x_i xi的事件的某个角色R-*,其中 1 ≤ i , j ≤ n 1≤i, j≤n 1≤i,j≤n,*表示角色类型。
- NONE \text{NONE} NONE:表示该词对不存在本文定义的任何关系。
4、框架
我们的模型体系结构如图3所示,它主要由三个部分组成。首先,使用广泛使用的预训练语言模型BERT (Devlin et al, 2019)作为编码器,从输入句子中产生上下文化的单词表示。然后,采用自适应事件融合层(由一个注意力模块和两个门模块组成)将目标事件类型嵌入到上下文表示中;然后利用预测层联合抽取词对之间的跨度关系和角色关系。

4.1 编码层
我们利用BERT作为模型的编码器,因为它已被证明是EE中表示学习的SoTA模型之一。给定一个输入句子 X = { x 1 , x 2 , … , x N } X = \{x_1, x_2,\ldots,x_N\} X={ x1,x2,…,xN},我们将每个token x i x_i xi转换为单词块,然后将它们输入预训练的BERT模块。在BERT计算之后,每个句子词都可能涉及几个片段的向量表示。这里我们使用最大池化来生成单词表示 H = { h 1 , h 2 , … , h N } ∈ R N × d h H = \{h_1, h_2,\ldots, h_N\}∈\mathbb{R}^{N×d_h} H={ h1,h2,…,hN}∈RN×dh基于词块表示。
4.2 自适应事件融合层
由于我们的框架的目标是预测目标事件类型 e t e_t et的词对之间的关系,因此生成事件感知表示非常重要。因此,为了融合编码器提供的事件信息和上下文信息,我们设计了一个自适应融合层。如图3所示,它包括一个注意力模块(用于建模事件之间的交互并获取全局事件信息)和两个门融合模块(用于使用上下文化的单词表示集成全局和目标事件信息)。
注意力机制:受到Transformer的self-attention启发(Vaswani et al, 2017; Wei et al, 2019b)中,我们首先引入了一种注意力机制,其输入由query、key和value组成。输出是按value的加权和计算的,其中分配给每个value的权重是query与相应value的点积。注意力机制可以表述为:
Attention ( Q , K , V ) = softmax ( Q K ⊤ d h ) V \text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^{\top}}{\sqrt{d_h}}) V Attention(Q,K,V)=softmax(dhQK⊤)V
d h \sqrt{d_h} dh是放缩因子, Q , K , V Q,K,V Q,K,V分别是query,key,value的tensor。
门融合机制:我们设计了一种门融合机制来整合两种特征并过滤掉不必要的信息。门矢量 g g g由全连接的sigmoid函数层产生,可以自适应控制输入流:
Gate ( p , q ) = g ⊙ p + ( 1 − g ) ⊙ q \text{Gate}(p,q)=g \odot p + (1-g) \odot q Gate(p,q)=g⊙p+(1−g)⊙q
g = σ ( W g [ p ; q ] + b g ) g=\sigma (W_g[p;q]+b_g) g=σ(Wg[p;q]+bg)
p , q p,q p,q是输入向量, σ ( ⋅ ) \sigma(\cdot) σ(⋅)是sigmoid激活函数, ⊙ , [ ; ] \odot,[;] ⊙,[;]分别是逐元素点积和连接操作, W g , b g W_g,b_g Wg,bg是可训练参数。
我们利用注意力机制为每个上下文化的词表示获取全局事件嵌入。给定一组随机初始化的事件类型嵌入 E = { e 1 , e 2 , … , e M } ∈ R M × d h E = \{e_1, e_2,\ldots, e_M\}∈\mathbb{R}^{M×d_h} E={
e1,e2,…,eM}∈RM×dh,其中 M M M为事件类型数,计算可表示为:
E g = Attention ( W q H , W k E , W v E ) E^g=\text{Attention}(W_qH,W_kE,W_vE) Eg=Attention(WqH,WkE,WvE)
E g E^g Eg是attention机制的输出, W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv分别是可学习参数。
为了将全局事件信息编码为单词表示,我们采用gate模块来融合上下文单词表示和全局事件表示。在此之后,我们使用另一种门机制来集成目标事件类型嵌入和最后一个门模块的输出。整个过程可以表述为:
H g = Gate ( H , E g ) H^g=\text{Gate}(H,E^g) Hg=Gate(H,Eg)
V t = Gate ( H g , e t ) V^t=\text{Gate}(H^g,e_t) Vt=Gate(Hg,et)
其中 e t ∈ E e_t∈E et∈E表示目标事件类型嵌入, V t = { v 1 , v 2 , … , v N } ∈ R N × d h V_t = \{v_1, v_2,\ldots, v_N\}∈\mathbb{R}^{N×d_h} Vt={ v1,v2,…,vN}∈RN×dh是最后的事件感知词表示。
4.3 联合预测层
在自适应事件融合层之后,我们得到事件感知的单词表示 V t V^t Vt,用于联合预测每对单词之间的跨度和角色关系。对于每个词对 ( w i , w j ) (w_i, w_j) (wi,wj),我们计算一个分数来衡量它们对于关系 s ∈ S s∈\mathcal{S} s∈S和 r ∈ R r∈\mathcal{R} r∈R的可能性。
距离意识得分:为了集成相对距离信息和单词对表示,我们引入了一个距离感知评分函数。对于来自一个表示序列的两个向量 p i p_i pi和 p j p_j pj,我们将它们与Su等人(2021)的相对位置嵌入结合起来,然后通过它们的点积计算得分:
Score ( p i , p j ) = ( R i p i ) ⊤ ( R j p j ) = p i ⊤ R j − i p j \text{Score}(p_i,p_j)=(R_ip_i)^{\top}(R_jp_j)=p_i^{\top}R_{j-i}p_j Score(pi,pj)=(Ripi)⊤(Rjpj)=pi⊤Rj−ipj
R i , R j R_i,R_j Ri,Rj分别是 p i , p j p_i,p_j pi,pj的位置嵌入, R j − i = R i ⊤ R j R_{j-i}=R_i^{\top}R_j Rj−i=Ri⊤Rj。因此,我们获得了词对 ( w i , w j ) (w_i,w_j) (wi,wj)目标事件类型 t t t跨度得分 c i j s c_{ij}^s cijs和角色的分 c i j r c_{ij}^r cijr:
c i j s = Score ( W s 1 v i t , W s 2 v j t ) c_{ij}^s=\text{Score}(W_{s1}v_i^t,W_{s2}v_j^t) cijs=Score(Ws1vit,Ws2vjt)
c i j r = Score ( W r 1 v i t , W r 2 v j t ) c_{ij}^r=\text{Score}(W_{r1}v_i^t,W_{r2}v_j^t) cijr=Score(Wr1vit,Wr2vjt)
W s 1 , W s 2 , W r 1 , W r 2 W_{s1},W_{s2},W_{r1},W_{r2} Ws1,Ws2,Wr1,Wr2是可学习参数。
4.2 训练详细
c i j ∗ c_{ij}^* cij∗, ∗ * ∗表示关系 s s s或 r r r,我们的训练目标是最小化circle loss的变体(Sun et al, 2020),它扩展了softmax交叉熵损失来解决多标签分类问题。此外,我们引入了一个阈值分数 δ δ δ,注意到有关系的对的分数大于 δ δ δ,而其他对的分数小于它。损失函数可表示为:
L ∗ = log ( e δ + ∑ ( i , j ) ∈ Ω ∗ e − c i j ∗ ) + log ( e δ + ∑ ( i , j ) ∉ Ω ∗ e c i j ∗ ) L^*=\log(e^{\delta}+\sum_{(i,j) \in \Omega *} e^{-c_{ij}^*})+\log(e^{\delta}+\sum_{(i,j) \notin \Omega *} e^{c_{ij}^*}) L∗=log(eδ+(i,j)∈Ω∗∑e−cij∗)+log(eδ+(i,j)∈/Ω∗∑ecij∗)
Ω ∗ Ω* Ω∗表示关系 ∗ * ∗的对集, δ δ δ设为零。
最后,我们枚举所选事件类型集 E ′ \mathcal{E}' E′中的所有事件类型,得到总损失:
L = ∑ t ∈ E ′ ( ∑ s ∈ S L s + ∑ r ∈ R L r ) L=\sum_{t \in \mathcal{E}'}(\sum_{s \in \mathcal{S}} L^s + \sum_{r \in \mathcal{R}}L^r) L=t∈E′∑(s∈S∑Ls+r∈R∑Lr)
其中 S ′ \mathcal{S}' S′是从 S \mathcal{S} S中抽样的子集。
4.5 推理
在推理过程中,我们的模型能够通过将事件类型嵌入并行注入自适应事件融合层来抽取所有事件。如图4所示,一旦我们的模型在一个阶段预测了某一事件类型的所有标记,整个解码过程可以概括为四个步骤:首先,我们获得触发词或论元的开始和结束索引。第二,我们获取触发词和论元范围。第三,我们根据R-*关系匹配触发词和论元。最后,将事件类型分配给该事件结构。特别地,我们对每种事件类型重复上述四个步骤。

5、实验
数据集

实验结果


表2报告了所有方法在重叠EE数据集FewFC上的结果,而表3报告了嵌套EE数据集Genia11和Genia13上的结果。我们可以观察到:
1)我们的方法显著优于所有其他方法,并在所有三个数据集上都获得了最先进的F1分数。
2)与序列标注方法相比,我们的模型获得了更好的召回率和F1分数。具体而言,在FewFC数据集上,我们的模型在召回率和AC F1分数上比BERT-CRFjoint分别提高了11.7%和6.3%,在两个Genia数据集上,AC F1分数平均提高了4.4%。结果表明,序列标注方法只能解决Flat EE问题,OneEE模型在重叠和嵌套EE问题上是有效的。
3)与多阶段方法相比,我们的模型在F1分数上的表现也有了很大的提高。我们的模型在三个数据集上的TC F1得分平均比最先进的模型CasEE高出2.1%。我们认为这是因为我们的自适应事件融合模块很好地学习了事件特征。特别是,我们的模型在三个数据集上比CasEE平均提高了3.4%的AI和1.6%的AC。结果显示了我们的单阶段框架的优越性,它可以很好地实现重叠和嵌套的事件抽取,并且没有错误传播。
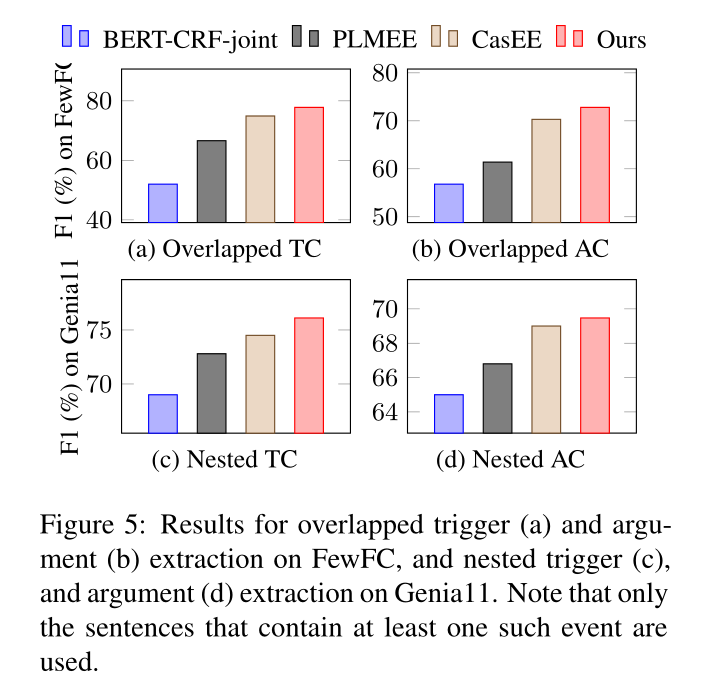
图五展示了OneEE效果好于其他模型,重点原因有两个:
- 相对于序列标注模型,OneEE有效解决了嵌套EE问题。
- 相对于CasEE模型,OneEE有效解决了错误传播问题。
消融实验






6、总结
本文提出了一种新的基于词-词关系识别的单阶段框架,以同时处理重叠和嵌套的EE。词对之间的关系预先定义为触发词或论元内的词-词关系,并交叉触发词-论元对。此外,我们提出了一种高效的模型,该模型由自适应事件融合层和距离感知预测层组成,前者用于整合目标事件表示,而前者用于联合识别各种关系。实验结果表明,该模型在三个数据集上都获得了新的SoTA结果,并且速度比SoTA模型快。