事先搭建好zookeeper和hadoop集群,(启动zk和hadoop)
1、下载安装包
-
https://archive.apache.org/dist/spark/spark-2.3.3/spark-2.3.3-bin-hadoop2.7.tgz
-
spark-2.3.3-bin-hadoop2.7.tgz
2、解压文件
cd /kkb/soft
tar -zxvf spark-2.3.3-bin-hadoop2.7.tgz -C /kkb/install
3、修改配置文件spark-env.sh
-
cd /kkb/install/spark-2.3.3-bin-hadoop2.7/conf/
-
cp spark-env.sh.template spark-env.sh
-
vim spark-env.sh
#配置java的环境变量
export JAVA_HOME=/opt/install/jdk1.8.0_141
#配置history日志信息
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=10 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log"
#配置zk相关信息
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark"扫描二维码关注公众号,回复: 14603911 查看本文章
4、修改slaves配置文件
-
cp slaves.template slaves
-
vim slaves
node01
node02
node03
5、修改spark-defaults.conf配置选项
cd /kkb/install/spark-2.3.3-bin-hadoop2.7/conf/
cp spark-defaults.conf.template spark-defaults.confvim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.compress true
spark.eventLog.dir hdfs://node01:8020/spark_log
如果spark 运行过程中, 报lzo错误,将一下两项添加进来
spark.driver.extraClassPath /kkb/install/hadoop-2.6.0-cdh5.14.2/share/hadoop/comm
on/hadoop-lzo-0.4.20.jar
spark.executor.extraClassPath /kkb/install/hadoop-2.6.0-cdh5.14.2/share/hadoop/comm
on/hadoop-lzo-0.4.20.jar
或者直接拷贝hadoop的lzo文件到spark的jars文件夹下面
cp /kkb/install/hadoop-2.6.0-cdh5.14.2/share/hadoop/common/hadoop-lzo-0.4.20.jar /kkb/install/spark-2.3.3-bin-hadoop2.7/jars
6、分发安装目录到其他机器
-
node01执行以下命令分发安装包
cd /kkb/install/
scp -r spark-2.3.3-bin-hadoop2.7/ node02:$PWD
scp -r spark-2.3.3-bin-hadoop2.7/ node03:$PWD
7、hdfs创建文件
hdfs dfs -mkdir -p /spark_log
8、启动
node01上面
cd /kkb/install/spark-2.3.3-bin-hadoop2.7/sbin
./start-all.sh
node02上面
cd /kkb/install/spark-2.3.3-bin-hadoop2.7/sbin
./start-master.sh
访问master主节点web管理界面 :http://node01:8080/
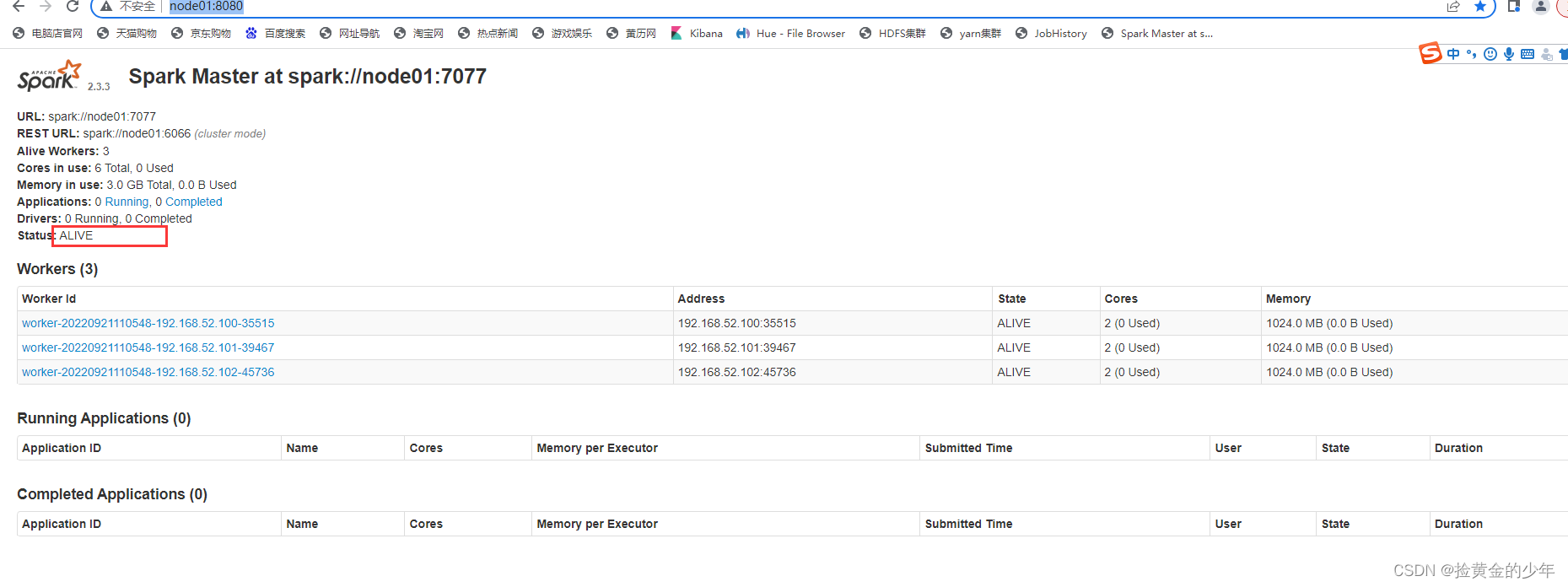
访问备份master节点 :http://node02:8080/
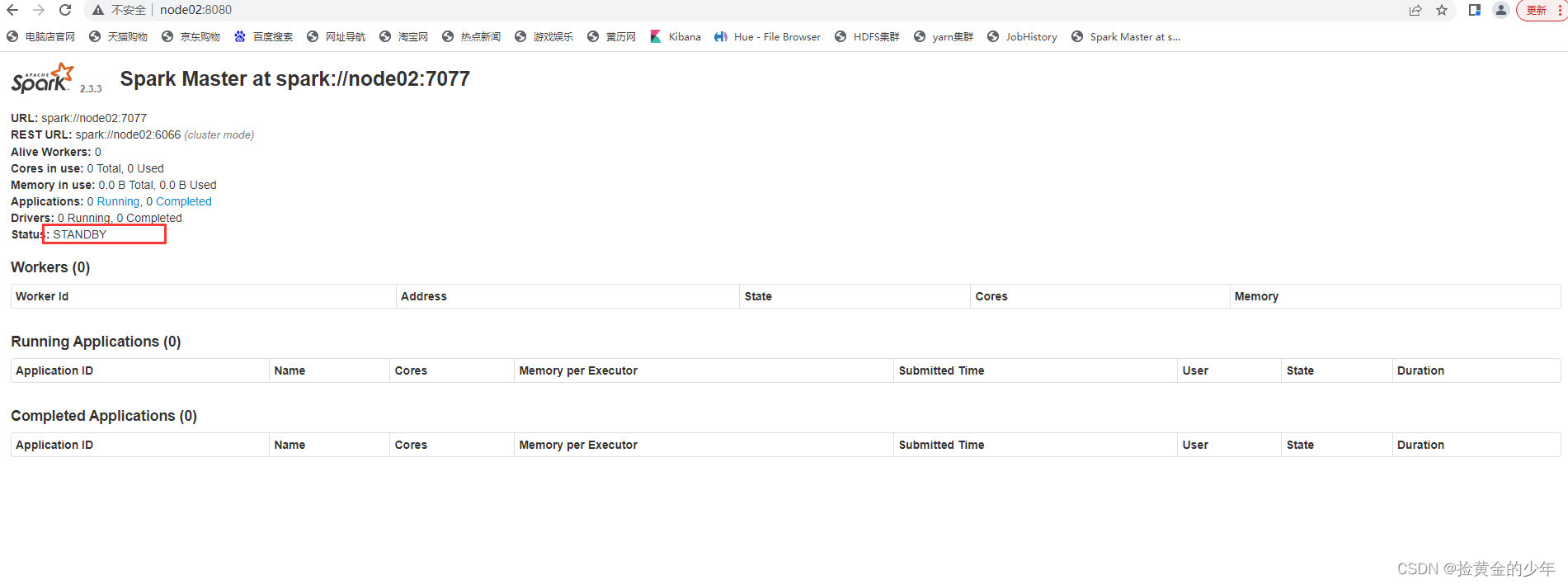
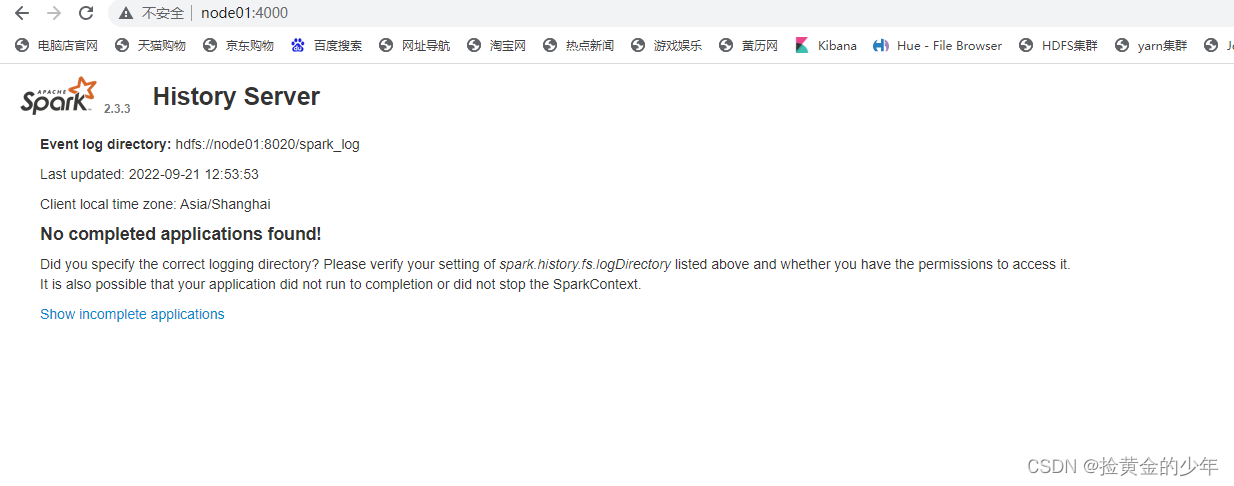
在node01上面启动 historyserver
cd /kkb/install/spark-2.3.3-bin-hadoop2.7/sbin
./start-history-server.sh
访问historyserver历史任务访问界面 http://node01:4000/
sparkRDD算子
在Spark中,Transformation算子(也称转换算子),在没有Action算子(也称行动算子)去触发的时候,是不会执行的,可以理解为懒算子,而Action算子可以理解为触发算子。
还有一种Shuffle类算子,就是上面说到的洗牌算子。
1、action算子
| 动作 | 含义 |
|---|---|
| reduce(func) | reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。 |
| collect() | 在驱动程序中,以数组的形式返回数据集的所有元素 |
| count() | 返回RDD的元素个数 |
| first() | 返回RDD的第一个元素(类似于take(1)) |
| take(n) | 返回一个由数据集的前n个元素组成的数组 |
| takeOrdered(n, [ordering]) | 返回自然顺序或者自定义顺序的前 n 个元素 |
| saveAsTextFile(path) | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) | 将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
| saveAsObjectFile(path) | 将数据集的元素,以 Java 序列化的方式保存到指定的目录下 |
| countByKey() | 针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
| foreach(func) | 在数据集的每一个元素上,运行函数func |
| foreachPartition(func) | 在数据集的每一个分区上,运行函数func |
2、Transformation算子
| 转换 | 含义 |
|---|---|
| map(func) | 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
| filter(func) | 返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
| flatMap(func) | 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
| mapPartitions(func) | 类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) | 类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U] |
| union(otherDataset) | 对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) | 对源RDD和参数RDD求交集后返回一个新的RDD |
| distinct([numTasks])) | 对源RDD进行去重后返回一个新的RDD |
| groupByKey([numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) | 与sortByKey类似,但是更灵活 |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
| cogroup(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD |
| coalesce(numPartitions) | 减少 RDD 的分区数到指定值。 |
| repartition(numPartitions) | 重新给 RDD 分区 |
| repartitionAndSortWithinPartitions(partitioner) | 重新给 RDD 分区,并且每个分区内以记录的 key 排序 |
3、Shuffle算子
去重
def distinct() def distinct(numPartitions: Int)
聚合
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)] def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] def groupBy[K](f: T => K, p: Partitioner):RDD[(K, Iterable[V])] def groupByKey(partitioner: Partitioner):RDD[(K, Iterable[V])] def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner): RDD[(K, U)] def aggregateByKey[U: ClassTag](zeroValue: U, numPartitions: Int): RDD[(K, U)] def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C)] def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, numPartitions: Int): RDD[(K, C)] def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null): RDD[(K, C)]
排序
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length): RDD[(K, V)] def sortBy[K](f: (T) => K, ascending: Boolean = true, numPartitions: Int = this.partitions.length)(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
重分区
def coalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty) def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null)
集合或者表操作
def intersection(other: RDD[T]): RDD[T] def intersection(other: RDD[T], partitioner: Partitioner)(implicit ord: Ordering[T] = null): RDD[T] def intersection(other: RDD[T], numPartitions: Int): RDD[T] def subtract(other: RDD[T], numPartitions: Int): RDD[T] def subtract(other: RDD[T], p: Partitioner)(implicit ord: Ordering[T] = null): RDD[T] def subtractByKey[W: ClassTag](other: RDD[(K, W)]): RDD[(K, V)] def subtractByKey[W: ClassTag](other: RDD[(K, W)], numPartitions: Int): RDD[(K, V)] def subtractByKey[W: ClassTag](other: RDD[(K, W)], p: Partitioner): RDD[(K, V)] def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))] def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))] def join[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, W))] def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
2、常见算子总结
1、map(不存在shuffle)
map是对RDD中的每个元素都执行一个指定的函数来产生一个新的RDD。 任何原RDD中的元素在新RDD中都有且只有一个元素与之对应。
package demo1
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("map").setMaster("local[*]")
val sc = new SparkContext(conf)
/**
* map算子,一共有多少元素就会执行多少次,和分区数无关,修改分区数进行测试
**/
val rdd: RDD[Int] = sc.parallelize(1.to(5), 1)
val mapRdd: RDD[Int] = rdd.map(x => {
println("执行") //一共被执行5次
x * 2
})
val result: Array[Int] = mapRdd.collect()
result.foreach(x => print(x + "\n"))
}
}
2、mapPartitions (不存在shuffle)
mapPartitions是map的一个变种。map的输入函数是应用于RDD中每个元素,
而mapPartitions的输入函数是应用于每个分区,也就是把每个分区中的内容作为整体来处理的。
使用mapPartitions要比map高效的多,比如:将RDD中的所有数据通过JDBC连接写入数据库,如果使用map函数,要为每一个元素都创建一个connection,这样开销很大,如果使用mapPartitions,那么只需要针对每一个分区建立一个connection。
它的函数定义为:
def mapPartitions[U: ClassTag](f: Iterator[T] => Iterator[U], preservesPartitioning: Boolean = false): RDD[U]*
f 即为输入函数,它处理每个分区里面的内容。每个分区中的内容将以Iterator[T]传递给输入函数f,f的输出结果是Iterator[U]。最终的RDD由所有分区经过输入函数处理后的结果合并起来的。
参数preservesPartitioning表示是否保留父RDD的partitioner分区信息。
package demo1
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo4 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("mapPartitions").setMaster("local[*]")
val sc = new SparkContext(conf)
/**
* mapPartitions算子,一个分区内处理,几个分区就执行几次,优于map函数,常用于时间转换,数据库连接
**/
val rdd: RDD[Int] = sc.parallelize(1.to(10), 2)
val mapRdd: RDD[Int] = rdd.mapPartitions(it => {
println("执行") //分区2次,共打印2次
it.map(x => x * 2)
})
val result: Array[Int] = mapRdd.collect()
result.foreach(x => print(x + "\t"))
}
}
3、mapPartitionsWithIndex(不存在shuffle)
加入了分区序列
package demo1
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo5 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("mapPartitionsWithIndex").setMaster("local[*]")
val sc = new SparkContext(conf)
/**
* mapPartitionsWithIndex算子,一个分区内处理,几个分区就执行几次,返回带有分区号的结果集
**/
val rdd: RDD[Int] = sc.parallelize(1.to(10), 2)
val value: RDD[(Int, Int)] = rdd.mapPartitionsWithIndex((index, it) => {
println("执行") //执行两次
it.map(x=>(index, x))
})
val result: Array[(Int, Int)] = value.collect()
result.foreach(x => print(x + "\t"))
}
}
4 filter(不存在shuffle)
filter 是对RDD中的每个元素都执行一个指定的函数来过滤产生一个新的RDD。 任何原RDD中的元素在新RDD中都有且只有一个元素与之对应。
-
需求:把 List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10) 中大于5的元素进行过滤
val rdd1 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10)).filter (x => x > 5 ).collect ---> rdd1: Array[Int] = Array(6, 7, 8, 9, 10) ---<
1.5 flatMap
与map类似,区别是原RDD中的元素经map处理后元素一一对应的关系,
而原RDD中的元素经flatmap处理后可生成多个元素来构建新RDD。 俗称扁平化
val rdd1 = sc.parallelize(Array("a b c", "d e f", "h i j")).flatMap(_.split(" ")).collect
--->
rdd1: Array[String] = Array(a, b, c, d, e, f, h, i, j)
---<
词频统计例子
package demo1
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkCount1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WorkCount").setMaster("local[*]")
val sc = new SparkContext(conf)
val tuples: Array[(String, Int)] = sc.textFile(ClassLoader.getSystemResource("word.csv")
.getPath).flatMap(_.split(",")).map((_, 1)).groupByKey().map(x => (x._1, x._2.size)).collect();
tuples.foreach(println)
sc.stop()
}
}
方法一,通过reducebykey统计
val tuples: Array[(String, Int)] = sc.textFile(ClassLoader.getSystemResource("word.csv").getPath)
.flatMap(_.split(","))
.map((_, 1))
.reduceByKey(_ + _)
.collect()
tuples.foreach(println)
方法一,通过groupBy统计
val tuples: Array[(String, Int)] = sc.textFile(ClassLoader.getSystemResource("word.csv")
.getPath).flatMap(_.split(",")).groupBy(x => x).map(y => (y._1, y._2.size)).collect()
方法三、通过 groupByKey进行统计
val tuples: Array[(String, Int)] = sc.textFile(ClassLoader.getSystemResource("word.csv")
.getPath).flatMap(_.split(",")).map((_, 1)).groupByKey().map(x => (x._1, x._2.size)).collect()
coalesce(默认不存在shuffle)
coalesce(numPatitions)缩减,缩减分区到指定数量,用于大数据集过滤后,提高小数据集的执行效率,默认只能减不能加。(默认不存在shuffle,如果将第二个参数设置为true会产生shuffle)
该函数用于将RDD进行重分区,使用HashPartitioner。 第一个参数为重分区的数目,第二个为是否进行shuffle,默认为false;
val rdd1 = sc.parallelize(1.to(10),5)
rdd1.partitions.length
--->
5
---<val rdd2 = rdd1.coalesce(2)
rdd2.partitions.length
--->
2
---<val rdd3 = rdd2.coalesce(10)
rdd3.partitions.length
--->
2
---<val rdd4 = rdd2.coalesce(15,true)
rdd4.partitions.length
repartition(减少分区无shuffle,增加分区存在shuffle)
repartition(numPatitions)更改分区,更改分区到指定数量,可加可减,但是减少还是使用coalesce,将这个理解为增加。
该函数其实就是coalesce函数第二个参数为true的实现
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope { coalesce(numPartitions, shuffle = true) }
val rdd1 = sc.parallelize(1.to(10),5)
rdd1.partitions.length
--->
5
---<val rdd2 = rdd1.repartition(2)
rdd2.partitions.length
--->
2
---<val rdd3 = rdd2.repartition(10)
rdd3.partitions.length
--->
10
---<
glom (不存在shuffle)
将每一个分区的元素合并成一个数组,形成新的RDD类型:RDD[Array[T]] ,合并分区元素算子
-
需求:分别合并三个分区的数字为一个元素。
val rdd1 = sc.parallelize(1.to(10), 3).glom().collect
--->
rdd1: Array[Array[Int]] = Array(Array(1, 2, 3), Array(4, 5, 6), Array(7, 8, 9, 10))
---<
RDD互交(交并差笛拉)
-
intersection 交集(存在shuffle)
val rdd1 = sc.parallelize(List(5, 6, 4, 3)) val rdd2 = sc.parallelize(List(1, 2, 3, 4)) val rdd3 = rdd1.intersection(rdd2).collect ---> rdd3: Array[Int] = Array(4, 3) ---<
-
union并集(不存在shuffle)
val rdd1 = sc.parallelize(List(5, 6, 4, 3)) val rdd2 = sc.parallelize(List(1, 2, 3, 4)) val rdd3 = rdd1.union(rdd2).collect ---> rdd3: Array[Int] = Array(5, 6, 4, 3, 1, 2, 3, 4) ---<
-
subtract差集(存在shuffle)
val rdd1 = sc.parallelize(List(5, 6, 4, 3)) val rdd2 = sc.parallelize(List(1, 2, 3, 4)) val rdd3 = rdd1.subtract(rdd2).collect ---> rdd3: Array[Int] = Array(6, 5) ---<
-
cartesian笛卡尔积(不存在shuffle)
val rdd1 = sc.parallelize(List('a', 'b', 'c'))
val rdd2 = sc.parallelize(List('A', 'B', 'C'))
val rdd3 = rdd1.cartesian(rdd2).collect
--->
rdd3: Array[(Char, Char)] = Array((a,A), (a,B), (a,C), (b,A), (b,B), (b,C), (c,A), (c,B), (c,C))
---<
-
zip拉链(必须保证RDD分区元素数量相同)(不存在shuffle)
val rdd1 = sc.parallelize(List(5, 6, 4, 3)) val rdd2 = sc.parallelize(List(1, 2, 3, 4)) val rdd3 = sc.parallelize(List(1, 2, 3)) val rdd4 = rdd1.zip(rdd2).collect ---> rdd4: Array[(Int, Int)] = Array((5,1), (6,2), (4,3), (3,4)) ---< scala> rdd1.zip(rdd3).collect ---> java.lang.IllegalArgumentException: Can't zip RDDs with unequal numbers of partitions: List(1, 10) ---<
distinct(存在shuffle)
distinct([numTasks])去重,参数表示任务数量,默认值和分区数保持一致
val rdd1 = sc.parallelize(Array(1,2,3,4,2,3,4,3,4,5)).distinct(2).collect ---> rdd1: Array[Int] = Array(4, 2, 1, 3, 5) ---<
sample(不存在shuffle)
sample(withReplacement,fraction,seed)抽样,常用在解决定位大key问题
-
以指定的随机种子随机抽样出比例为fraction的数据(抽取到的数量是size*fraction),注意:得到的结果并不能保证准确的比例,也就是说fraction只决定了这个数被选中的比率,并不是从数据中抽出多少百分比的数据,决定的不是个数,而是比率。
-
withReplacement表示抽出的数据是否放回,true为有放回抽样,flase为无放回抽样,放回表示数据有可能会被重复抽取到,false则不可能重复抽取到,如果为false则fraction必须在[0,1]内,是true则大于0即可。
-
seed用于指定随机数生成器种子,一般默认的,或者传入当前的时间戳,(如果传入定值,每次取出结果一样)
val rdd1 = sc.parallelize(1.to(10)).sample(false,0.5).collect
--->
抽出结果没有重复
---<
val rdd1 = sc.parallelize(1.to(10)).sample(true,2).collect
--->
抽出结果没有重复
---<val rdd1 = sc.parallelize(1.to(10)).sample(true,2,1).collect
--->
抽出结果有重复
rdd1: Array[Int] = Array(1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 4, 4, 5, 5, 7, 8, 9, 10, 10, 10)
---<
groupBy(存在shuffle)
根据条件函数分组
def groupBy[K](f: (T) ⇒ K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])]
val rdd1 = sc.parallelize(1.to(10)).groupBy(x => x % 2).collect ---> x => x % 2要么是0,要么是1;那么0、1是每组的key rdd1: Array[(Int, Iterable[Int])] = Array((0,CompactBuffer(2, 4, 6, 8, 10)), (1,CompactBuffer(1, 3, 5, 7, 9))) ---< val rdd1 = sc.parallelize(1.to(10)).groupBy(x => x % 2 == 0).collect ---> x => x % 2 == 0要么是true,要么是false;那么true、false是每组的key rdd1: Array[(Boolean, Iterable[Int])] = Array((false,CompactBuffer(1, 3, 5, 7, 9)), (true,CompactBuffer(2, 4, 6, 8, 10))) ---<
sortBy(存在shuffle)
根据条件函数排序
def sortBy[K](f: (T) ⇒ K, ascending: Boolean = true, numPartitions: Int = this.partitions.length)(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
val rdd1 = sc.parallelize(Array(4, 2, 3, 1, 5), 1).sortBy(x => x, false).collect ---> rdd1: Array[Int] = Array(5, 4, 3, 2, 1) ---< val rdd1 = sc.parallelize(Array(4, 2, 3, 1, 5), 1).sortBy(x => x, true).collect ---> rdd1: Array[Int] = Array(1, 2, 3, 4, 5) ---<
reduce(存在shuffle)
def reduce(f: (T, T) ⇒ T): T
根据映射函数f,对RDD中的元素进行二元计算,返回计算结果。
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5)).reduce(_ + _)
--->
15
---<
scala> val rdd2 = sc.parallelize(List("1","2","3","4","5"),5).reduce(_ + _)
rdd2: String = 14523
scala> val rdd2 = sc.parallelize(List("1","2","3","4","5"),5).reduce(_ + _)
rdd2: String = 12453
--->
非本地模式运行时:
这里可能会出现多个不同的结果,由于元素在不同的分区中,
每一个分区都是一个独立的task线程去运行。这些task运行有先后关系
---<
foreach、foreachPartition(不存在shuffle)
val rdd1 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10))
//foreach实现对rdd1里的每一个元素乘10然后打印输出
rdd1.foreach(x=>println(x * 10))//foreachPartition实现对rdd1里的每一个元素乘10然后打印输出
rdd1.foreachPartition(iter => iter.foreach(x=>println(x * 10)))foreach:用于遍历RDD,将函数f应用于每一个元素,无返回值(action算子)。
foreachPartition: 用于遍历操作RDD中的每一个分区。无返回值(action算子)。
总结:
一般使用mapPartitions或者foreachPartition算子比map和foreach更加高效,推荐使用。
k-v类型常见算子
大多数Spark算子都可以用在任意类型的RDD上,但是有一些比较特殊的操作只能用在key-value类型的RDD上,以下列出的By操作都是shuffle算子,正常情况下都会产生shuffle
特殊情况不会进行shuffle,比如聚合类算子之前做一次group by,或者使用相同的分区器进行一次分区然后再去聚合,就不会发生shuffle
实际场景中说到的避免shuffle,并不是所有的情况都可以避免shuffle算子,要不然也没有存在的意义了,而是在shuffle操作之前进行一些预分区操作,也就是分区内聚合。如单词统计可以使用groupByKey进行分组后在统计,这时可以使用reduceByKey算子(在shuffle之前会有combine(预聚合)操作)或者combineByKey算子或者foldByKey算子来替代,来进行优化
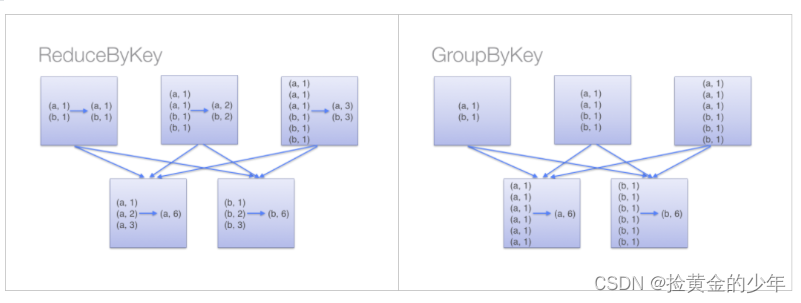
partitionBy
repartition 和 partitionBy 都是对数据进行重新分区,默认都是使用 HashPartitioner,区别在于partitionBy 只能用于 PairRDD,作用于PairRDD时,repartition 其实使用了一个随机生成的数来当做 Key,而不是使用原来的 Key!而partitionBy 是作用与原来的Key
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
object Demo0 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("partitionBy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.parallelize(Array(("a", 1), ("a", 2), ("b", 1), ("b", 3), ("c", 1), ("e", 1)), 2)
println("rdd1分区数:" + rdd1.partitions.length) //2
println("rdd1分区器:" + rdd1.partitioner) //None
println
val rdd2: RDD[(String, Int)] = rdd1.repartition(4)
println("rdd2分区数:" + rdd2.partitions.length) //4
println("rdd2分区器:" + rdd2.partitioner) //None
println
val rdd3: RDD[(String, Int)] = rdd1.partitionBy(new HashPartitioner(4))
println("rdd3分区数:" + rdd3.partitions.length) //4
println("rdd3分区器:" + rdd3.partitioner) //Some(org.apache.spark.HashPartitioner@4)
println
println("rdd2:")
rdd2.glom().mapPartitionsWithIndex((index, iter) => {
iter.map(arr => {
(index, arr.mkString(","))
})
}).foreach(print)
//(0,(a,2))(1,(b,1),(b,3))(2,(c,1))(3,(a,1),(e,1))
println
println
println("rdd3:")
rdd3.glom().mapPartitionsWithIndex((index, iter) => {
iter.map(arr => {
(index, arr.mkString(","))
})
}).foreach(print)
//(0,)(3,(c,1))(2,(b,1),(b,3))(1,(a,1),(a,2),(e,1)) key相同的肯定在一个分区
}
}
2.2 自定义分区器
使用partitionBy案例结合自定义分区器
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
object Demo1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("partitionBy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
println(rdd2.partitions.length) //1
println(rdd2.partitioner) //None
println()
val rdd3: RDD[(String, Int)] = rdd2.partitionBy(new MyPatitioner(2))
println(rdd3.partitions.length) //2
println(rdd3.partitioner) //Some(com.kkb.spark.demo.MyPatitioner@41c204a0)
println()
val result: RDD[(Int, (String, Int))] = rdd3.mapPartitionsWithIndex((index, iter) => {
iter.map(x => (index, (x._1, x._2)))
})
result.foreach(println)
/**
* (0,(hadooop,1))
* (1,(hello,1))
* (0,(spark,1))
* (1,(hello,1))
**/
}
}
/**
*
* @param num 分区数
*/
class MyPatitioner(num: Int) extends Partitioner {
override def numPartitions: Int = num
override def getPartition(key: Any): Int = {
System.identityHashCode(key) % num.abs
}
}
reduceByKey
reduceByKey(V , V)=>V 根据key进行聚合,在shuffle之前会有combine(预聚合)操作
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object Demo2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("reduceByKey").setMaster("local[*]")
val sc = new SparkContext(conf)val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
val result: RDD[(String, Int)] = rdd2.reduceByKey(_ + _)
result.foreach(x => print(x + "\t")) //(spark,1) (hadooop,1) (hello,2)
}
}
groupByKey
根据key进行分组,直接shuffle
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("groupByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
val result: RDD[(String, Iterable[Int])] = rdd2.groupByKey()
result.foreach(x => print(x + "\t"))
//(spark,CompactBuffer(1)) (hadooop,CompactBuffer(1)) (hello,CompactBuffer(1, 1))
result.map(x => (x._1, x._2.size)).foreach(x => print(x + "\t")) //(spark,1) (hadooop,1) (hello,2)
}
}
aggrateByKey
def aggregateByKey[U](zeroValue: U)(seqOp: (U, V) ⇒ U, combOp: (U, U) ⇒ U)(implicit arg0: ClassTag[U]): RDD[(K, U)]
基于Key分组然后去聚合的操作,耗费资源太多,这时可以使用reduceByKey或aggrateByKey算子去提高性能
aggrateByKey分区内聚合,后在进行shuffle聚合
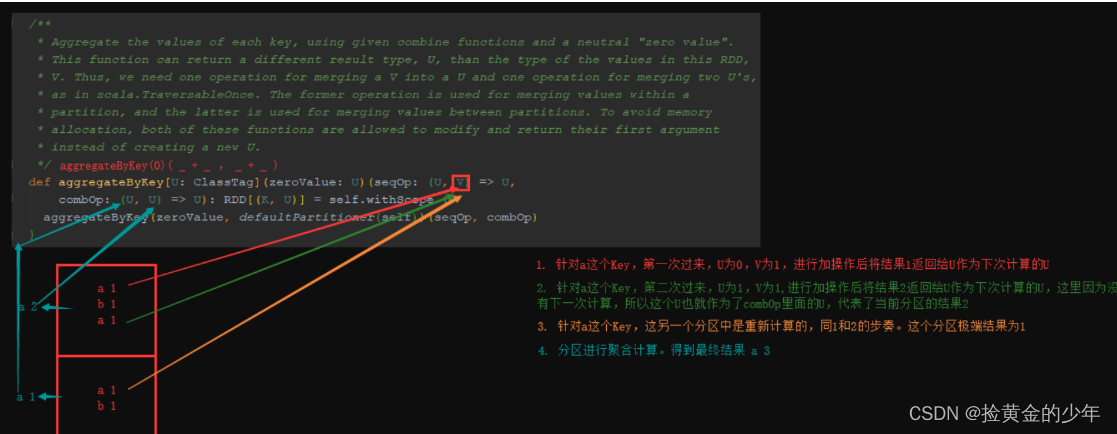
package demo03Key_Value
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* zeroValue 来进行累加的初始值
* seqOp来针对每个分区内部的数据进行聚合操作
* combOp,对分区之后结果进行累加操作
*/
object Demo4 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("aggregateByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
//写法一
val seqOp = (partSum: Int, value: Int) => {
partSum + value
}
val combOp = (partSumThis: Int, partSumOther: Int) => {
partSumThis + partSumOther
}
rdd2.aggregateByKey(0)(seqOp, combOp).foreach(x => print(x + "\t"))
println
//写法二
//柯里化的好处,可以进行类型推断
rdd2.aggregateByKey(0)((partSum, value) => {
partSum + value
}, (partSumThis, partSumOther) => {
partSumThis + partSumOther
}).foreach(x => print(x + "\t"))
println
//写法三:简化
val result: RDD[(String, Int)] = rdd2.aggregateByKey(0)(_ + _, _ + _)
result.foreach(x => print(x + "\t")) //(spark,1) (hadooop,1) (hello,2)
}
}
foldByKey
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]折叠计算,没有aggrateByKey灵活,如果分区内和分区外聚合计算不一样,则不行
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo5 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("foldByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
//方式一
rdd2.foldByKey(0)((x, y) => {x + y}).foreach(x => print(x + "\t"))
println()
//简写
val result: RDD[(String, Int)] = rdd2.foldByKey(0)(_ + _)
result.foreach(x => print(x + "\t")) //(spark,1) (hadooop,1) (hello,2)
}
}
2.6 combineByKey
def combineByKey[C]( createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, numPartitions: Int): RDD[(K, C)]根据Key组合计算,与aggrateByKey相似
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo6 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("combineByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
val result: RDD[(String, Int)] = rdd2.combineByKey(v => v, (c: Int, v: Int) => c + v, (c1: Int, c2: Int) => c1 + c2)
result.foreach(x => print(x + "\t")) //(spark,1) (hadooop,1) (hello,2)
}
}
2.7 sortByKey
OrderedRDDFunctions
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length) : RDD[(K, V)]根据Key排序,产生shuffle
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo7 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("sortByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("ahello", "bhadooop", "chello", "dspark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
rdd2.sortByKey().foreach(x => print(x + "\t")) //默认升序排序 (dspark,1) (chello,1) (bhadooop,1) (ahello,1)
println
rdd2.sortByKey(true).foreach(x => print(x + "\t"))
}
}
2.8 mapValues(不存在Shuffle)
def mapValues[U](f: V => U): RDD[(K, U)]PairRDDFunctions
Pass each value in the key-value pair RDD through a map function without changing the keys
将f应用到每个kv对的value;key保持不变
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo8 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("mapValues").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hadooop", "hello", "spark"), 1)
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
rdd2.mapValues(x => x + 1).foreach(x => print(x + "\t")) //(hello,2) (hadooop,2) (hello,2) (spark,2)
}
}
join
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]特殊情况不会进行shuffle,在join之前做一次group by,或者使用相同的分区器进行一次分区然后再去join这时join不会发生shuffle
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo9 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("join").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.parallelize(Array(("a", 10), ("b", 10), ("a", 20), ("d", 10)))
val rdd2: RDD[(String, Int)] = sc.parallelize(Array(("a", 30), ("b", 20), ("c", 10)))
//内连接 (a,(10,30)) (b,(10,20)) (a,(20,30))
rdd1.join(rdd2).foreach(x => print(x + "\t"))
//左链接(b,(10,Some(20))) (d,(10,None)) (a,(10,Some(30))) (a,(20,Some(30)))
rdd1.leftOuterJoin(rdd2).foreach(x => print(x + "\t"))
//右链接(c,(None,10)) (a,(Some(10),30)) (b,(Some(10),20)) (a,(Some(20),30))
rdd1.rightOuterJoin(rdd2).foreach(x => print(x + "\t"))
//全链接(b,(Some(10),Some(20))) (c,(None,Some(10))) (d,(Some(10),None)) (a,(Some(10),Some(30))) (a,(Some(20),Some(30)))
rdd1.fullOuterJoin(rdd2).foreach(x => print(x + "\t"))
}
}
2.10 cogroup
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))] 还有很多其他形式的重载 def cogroup[W1, W2](other1: RDD[(K, W1)], other2: RDD[(K, W2)], partitioner: Partitioner) : RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2]))]根据Key聚合RDD
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo10 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("cogroup").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.parallelize(Array(("a", 10), ("b", 10), ("a", 20), ("d", 10)))
val rdd2: RDD[(String, Int)] = sc.parallelize(Array(("a", 30), ("b", 20), ("c", 10)))
/**
* (c,(CompactBuffer(),CompactBuffer(10)))
* (b,(CompactBuffer(10),CompactBuffer(20)))
* (a,(CompactBuffer(10, 20),CompactBuffer(30)))
* (d,(CompactBuffer(10),CompactBuffer()))
*/
rdd1.cogroup(rdd2).foreach(println)
}
}
案例
1、使用spark程序来实现PV的统计
需求:通过spark程序读取access.log,统计一共有多少访问量(PV-page view页面浏览量或点击量)
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object PvCount {
def main(args: Array[String]): Unit = {
//1、创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setAppName("PV").setMaster("local[2]")
//2、创建SparkContext对象
val sc = new SparkContext(sparkConf)
sc.setLogLevel("warn")
//3、读取数据文件
val dataRDD: RDD[String] = sc.textFile(this.getClass().getClassLoader.getResource("access.log").getPath)
//4、统计PV
val pv: Long = dataRDD.count()
println(s"pv:$pv")
//5、关闭sc
sc.stop()
}
}
3.2 使用spark程序来实现UV的统计
需求:通过spark程序读取access.log,统计一共有多少人进行了访问(UV-unique visitor访问某个站点或点击某个网页的不同IP地址的人数)
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//求出所有ip地址,再去重
object UvCount {
def main(args: Array[String]): Unit = {
//1、创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setAppName("PV").setMaster("local[2]")
//2、创建SparkContext对象
val sc = new SparkContext(sparkConf)
sc.setLogLevel("warn")
//3、读取数据文件
val dataRDD: RDD[String] = sc.textFile(this.getClass().getClassLoader.getResource("access.log").getPath)
//4、获取所有的ip地址
val ipsRDD: RDD[String] = dataRDD.map(x => x.split(" ")(0))
//5、对ip地址进行去重
val distinctRDD: RDD[String] = ipsRDD.distinct()
//6、统计uv
val uv: Long = distinctRDD.count()
println(s"uv:$uv")
sc.stop()
}
}
3.3 使用spark程序统计访问最多前五位的URL
需求:通过spark程序读取access.log,统计访问URL最多的前五位
注意:使用空格切割文件之后,成为一个数组,下标为10就是访问的URL
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
//对每个url计数;然后按次数降序排序;再取头5个
object VisitTopN {
def main(args: Array[String]): Unit = {
//1、创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setAppName("VisitTopN").setMaster("local[2]")
//2、创建SparkContext对象
val sc = new SparkContext(sparkConf)
sc.setLogLevel("warn")
//3、读取数据文件
val dataRDD: RDD[String] = sc.textFile(this.getClass().getClassLoader.getResource("access.log").getPath)
//4、先对数据进行过滤
val filterRDD: RDD[String] = dataRDD.filter(x => x.split(" ").length > 10)
//5、获取每一个条数据中的url地址链接
val urlsRDD: RDD[String] = filterRDD.map(x => x.split(" ")(10))
//6、过滤掉不是http的请求
val fUrlRDD: RDD[String] = urlsRDD.filter(_.contains("http"))
//7、把每一个url计为1
val urlAndOneRDD: RDD[(String, Int)] = fUrlRDD.map(x => (x, 1))
//8、相同的url出现1进行累加
val result: RDD[(String, Int)] = urlAndOneRDD.reduceByKey(_ + _)
//9、对url出现的次数进行排序----降序
val sortRDD: RDD[(String, Int)] = result.sortBy(_._2, false)
//10、取出url出现次数最多的前5位
val top5: Array[(String, Int)] = sortRDD.take(5)
top5.foreach(println)
sc.stop()
}
}
3.4 读取mysql数据
需求一:求取每个搜索关键字
search_key下的职位数量,并将结果入库mysql,注意:实现高效入库需求二,求取每个搜索关键字
search_key岗位下最高薪资的工作信息
-
导入job_detail.sql,job_count.sql到mysql数据库
-
pom.xml
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.38</version> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.7</version> </dependency>
import java.sql.{Connection, DriverManager}
import org.apache.commons.lang3.StringUtils
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
case class Job_Detail(job_id:String, job_name:String, job_url:String,job_location:String, job_salary:String,
job_company:String,job_experience:String,job_class:String,job_given:String,
job_detail:String, company_type:String,company_person:String ,
search_key:String, city:String)
object JdbcOperate {
//定义一个函数,无参,返回一个jdbc的连接(用于创建JdbcRDD的第二个参数)
val getConn: () => Connection = () => {
DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb?characterEncoding=UTF-8","root","root")
}
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("JdbcRddDemo").setMaster("local[4]")
val sparkContext = new SparkContext(conf)
//创建RDD,这个RDD会记录以后从MySQL中读数据
val jdbcRDD: JdbcRDD[Job_Detail] = new JdbcRDD(
sparkContext, //SparkContext
getConn, //返回一个jdbc连接的函数
"SELECT * FROM jobdetail WHERE job_id >= ? AND job_id <= ?", //sql语句(要包含两个占位符)
1, //第一个占位符的最小值
75000, //第二个占位符的最大值
8, //分区数量
rs => {
val job_id = rs.getString(1)
val job_name: String = rs.getString(2)
val job_url = rs.getString(3)
val job_location: String = rs.getString(4)
val job_salary = rs.getString(5)
val job_company: String = rs.getString(6)
val job_experience = rs.getString(7)
val job_class: String = rs.getString(8)
val job_given = rs.getString(9)
val job_detail: String = rs.getString(10)
val company_type = rs.getString(11)
val company_person: String = rs.getString(12)
val search_key = rs.getString(13)
val city: String = rs.getString(14)
Job_Detail(job_id, job_name, job_url,job_location, job_salary, job_company,job_experience,job_class,job_given,job_detail, company_type,company_person ,search_key, city)
}
)
val searchKey: RDD[(String, Iterable[Job_Detail])] = jdbcRDD.groupBy(x => x.search_key)
//需求一:求取每个搜索关键字下的职位数量,并将结果入库mysql,注意:实现高效入库
//第一种实现方式
val searchKeyRdd: RDD[(String, Int)] = searchKey.map(x => (x._1,x._2.size))
//第二种实现方式
//求取每个搜索关键字出现的岗位人数
val resultRdd: RDD[(String, Int)] = jdbcRDD.map(x => (x.search_key,1)).reduceByKey(_ + _).filter(x => x._1 != null)
//数据量变少,缩减分区个数
val rsultRdd2: RDD[(String, Int)] = resultRdd.coalesce(2)
//将统计的结果写回去mysql
rsultRdd2.foreachPartition( iter =>{ //创建数据库连接
val conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb?characterEncoding=UTF-8", "root", "root")
//关闭自动提交
conn.setAutoCommit(false);
val statement = conn.prepareStatement("insert into job_count(search_name, job_num) values (?, ?)")
//遍历
iter.foreach(record =>{
//赋值操作
statement.setString(1, record._1)
statement.setInt(2, record._2)
//添加到一个批次中
statement.addBatch()
})
//批量提交该分区所有数据
statement.executeBatch()
conn.commit()
conn.close()
// 关闭资源
statement.close()
//利用连接池,使用完了就回收
})
//需求二,求取每个搜索关键字岗位下最高薪资的工作信息,以及最低薪资下的工作信息
val getEachJobs: RDD[(String, Iterable[Job_Detail])] = jdbcRDD.groupBy(x => x.search_key)
val maxJobDetail: RDD[Job_Detail] = getEachJobs.map(x => {
val value: Iterable[Job_Detail] = x._2
val array: Array[Job_Detail] = value.toArray
array.maxBy(x => {
val job_salary: String = x.job_salary
val result = if (StringUtils.isNotEmpty(job_salary) && job_salary.contains("k") && job_salary.contains("-") && job_salary.replace("k", "").split("-").length >= 2) {
val strings: Array[String] = job_salary.replace("k", "").split("-")
val result2 = if (strings.length >= 2) {
strings(1).toInt
} else {
0
}
result2
} else {
0
}
result
})
})
val details: Array[Job_Detail] = maxJobDetail.collect()
details.foreach(x =>{
println(x.job_id + "\t" + x.job_salary + "\t" + x.search_key + "\t" + x.job_company)
})
sparkContext.stop()
}
}
3.5 广播变量
对于某些时候,我们需要大表join小表,或者小表join大表的时候,我们就可以考虑使用广播变量,将小表的数据一次性全部读取加载,然后进行join,避免shuffle的过程产生,提高数据处理速度,我们可以通过使用广播变量,将小表数据存放到每个Executor的内存中,只驻留一份变量副本, 而不是对每个 task 都传输一次大变量,省了很多的网络传输, 对性能提升具有很大帮助, 而且会通过高效的广播算法来减少传输代价。使用广播变量的场景很多, 我们都知道spark 一种常见的优化方式就是小表广播, 使用 map join 来代替 reduce join, 我们通过把小的数据集广播到各个节点上,节省了一次特别 expensive(昂贵) 的 shuffle 操作。比如driver 上有一张数据量很小的表, 其他节点上的task 都需要 lookup 这张表, 那么 driver 可以先把这张表 copy 到这些节点,这样 task 就可以在本地查表了。
-
创建orders.txt
1001,20150710,p0001,2 1002,20150710,p0002,3 1002,20150710,p0003,3
-
创建pdts.txt
p0001,xiaomi,1000,2 p0002,appale,1000,3 p0003,samsung,1000,4
-
案例代码
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkBroadCast {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("sparkBroadCast").setMaster("local[4]")
val sparkContext = new SparkContext(conf)
//读取文件,将商品文件数据内容作为广播变量
val productRdd: RDD[String] = sparkContext.textFile(".\\src\\main\\resources\\pdts.txt")
//将数据收集起来
val mapProduct: collection.Map[String, String] = productRdd.map(x => {
(x.split(",")(0), x)
}).collectAsMap()
//开始广播
val broadCastValue: Broadcast[collection.Map[String, String]] = sparkContext.broadcast(mapProduct)
//读取订单数据
val ordersRDD: RDD[String] = sparkContext.textFile(".\\src\\main\\resources\\orders.txt")
//订单数据rdd进行拼接商品数据
val proudctAndOrderRdd: RDD[String] = ordersRDD.mapPartitions(eachPartition => {
val getBroadCastMap: collection.Map[String, String] = broadCastValue.value
val finalStr: Iterator[String] = eachPartition.map(eachLine => {
val ordersGet: Array[String] = eachLine.split(",")
val getProductStr: String = getBroadCastMap.getOrElse(ordersGet(2), "")
eachLine + "\t" + getProductStr
})
finalStr
})
println(proudctAndOrderRdd.collect().toBuffer)
sparkContext.stop()
}
}
累加器案例
累加器问题抛出
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object accumulator1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Accumulator").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5), 2)
var a = 1
rdd1.foreach(x => {
a += 1
println("rdd: "+a)
})
println("-----")
println("main: "+a)
/**
* rdd: 2
* rdd: 2
* rdd: 3
* rdd: 3
* rdd: 4
* -----
* main: 1
* */
}
}
从上面可以看出,2个问题:
变量是在RDD分区中进行累加,并且2个RDD分区中的变量不同
最后并没有main方法中的变量值改变
考虑到main方法中的a变量是在Driver端,而RDD分区又是在Excutor端进行计算,所以只是拿了一个Driver端的镜像,而且不同步回Driver端
在实际开发中,我们需要进行这种累加,这时就用到了累加器
2、累加器案例
Spark提供了一些常用累加器,主要针对值类型
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
object accumulator2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Accumulator").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5), 2)
val acc: LongAccumulator = sc.longAccumulator("acc")
rdd1.foreach(x => {
acc.add(1)
println("rdd: "+acc.value)
})
println("-----")
println("main: "+acc.count)
/**
* rdd: 1
* rdd: 1
* rdd: 2
* rdd: 2
* rdd: 3
* -----
* main: 5
* */
}
}
如上代码,我们发现累加器是分区内先累加,再分区间累加
自定义累加器
-
案例一:自定义Int累加器
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
object accumulator3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Accumulator").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5), 2)
val acc = new MyAccumulator
//注册累加器
sc.register(acc)
rdd1.foreach(x => {
acc.add(1)
println("rdd: " + acc.value)
})
println("-----")
println("main: " + acc.value)
/**
* rdd: 1
* rdd: 1
* rdd: 2
* rdd: 3
* rdd: 2
* -----
* main: 5
**/
}
}
class MyAccumulator extends AccumulatorV2[Int, Int] {
var sum: Int = 0
//判断累加的值是不是空
override def isZero: Boolean = sum == 0
//如何把累加器copy到Executor
override def copy(): AccumulatorV2[Int, Int] = {
val accumulator = new MyAccumulator
accumulator.sum = sum
accumulator
}
//重置值
override def reset(): Unit = {
sum = 0
}
//分区内的累加
override def add(v: Int): Unit = {
sum += v
}
//分区间的累加,累加器最终的值
override def merge(other: AccumulatorV2[Int, Int]): Unit = {
other match {
case o: MyAccumulator => this.sum += o.sum
case _ =>
}
}
override def value: Int = this.sum
}
-
案例二:自定义map平均值累加器
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
object accumulator4 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("partitionBy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5), 2)
val acc = new MyAccumulatorV2
//注册累加器
sc.register(acc)
rdd1.foreach(x => {
acc.add(x)
})
println("main: " + acc.value)
/**main: Map(sum -> 15.0, count -> 5.0, avg -> 3.0) */
}
}
class MyAccumulatorV2 extends AccumulatorV2[Int, Map[String, Double]] {
var map: Map[String, Double] = Map[String, Double]()
//判断累加的值是不是空
override def isZero: Boolean = map.isEmpty
//如何把累加器copy到Executor
override def copy(): AccumulatorV2[Int, Map[String, Double]] = {
val accumulator = new MyAccumulatorV2
accumulator.map ++= map
accumulator
}
//重置值
override def reset(): Unit = {
map = Map[String, Double]()
}
//分区内的累加
override def add(v: Int): Unit = {
map += "sum" -> (map.getOrElse("sum", 0d) + v)
map += "count" -> (map.getOrElse("count", 0d) + 1)
}
//分区间的累加,累加器最终的值
override def merge(other: AccumulatorV2[Int, Map[String, Double]]): Unit = {
other match {
case o: MyAccumulatorV2 =>
this.map += "sum" -> (map.getOrElse("sum", 0d) + o.map.getOrElse("sum", 0d))
this.map += "count" -> (map.getOrElse("count", 0d) + o.map.getOrElse("count", 0d))
case _ =>
}
}
override def value: Map[String, Double] = {
map += "avg" -> map.getOrElse("sum", 0d) / map.getOrElse("count", 1d)
map
}
}
sparkSQL自定义函数
用户自定义函数类别分为以下三种:
-
UDF(User-defined functions) 用户自定义函数,输入一行输出一行(一对一)
-
UDAF(User Defined Aggregate Function)用户定义的聚合函数, 输入多行输出一行(多对一)
-
UDTF(User-Defined Table-Generating Functions) 用户自定义生成函数。输入一行输出多行(一对多)
下面测试原始数据结构如下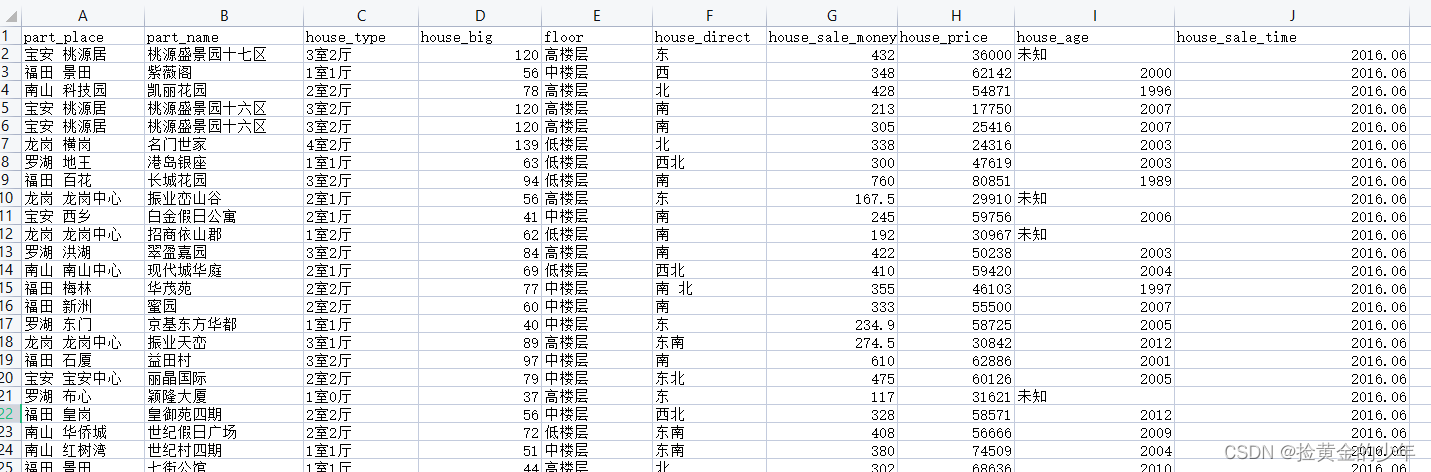
9.1 自定义UDF
package com.kaikeba.sql
import java.util.regex.{Matcher, Pattern}
import org.apache.spark.SparkConf
import org.apache.spark.sql.api.java.UDF1
import org.apache.spark.sql.types.DataTypes
import org.apache.spark.sql.{DataFrame, SparkSession}//todo: 自定义UDF函数:一对一
object CustomSparkUDF {
def main(args: Array[String]): Unit = {//todo: 1、构建SparkSession
val sparkConf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("CustomSparkUDF")
val spark: SparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._//todo: 2、加载csv文件
val df: DataFrame = spark
.read
.format("csv")
.option("timestampFormat", "yyyy/MM/dd HH:mm:ss ZZ")
.option("header", "true")
.option("multiLine", true)
.load("./secondHandHouse/深圳链家二手房成交明细.csv")
//todo: 3、注册成表
df.createOrReplaceTempView("house_sale")//todo: 4、自定义UDF函数
spark.udf.register("house_udf",new UDF1[String,String] {
val pattern: Pattern = Pattern.compile("^[0-9]*$")
override def call(input: String): String = {
val matcher: Matcher = pattern.matcher(input)
if(matcher.matches()){
input
}else{
"1990"
}
}
},DataTypes.StringType)//todo: 5、使用自定义UDF函数进行查询
spark.sql("select house_udf(house_age) from house_sale limit 200").show()spark.stop()
}
}
2、自定义UDAF
需求:自定义UDAF函数,读取深圳二手房数据,然后按照楼层进行分组,求取每个楼层的平均成交金额 (对数据的自定义聚合操作)
package com.kaikeba.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._//todo: 自定义UDAF函数:多对一
object CustomSparkUDAF {
def main(args: Array[String]): Unit = {//todo: 1、构建SparkSession
val sparkConf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("CustomSparkUDAF")
val session: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
session.sparkContext.setLogLevel("WARN")//todo: 2、加载csv文件
val df: DataFrame = session
.read
.format("csv")
.option("timestampFormat", "yyyy/MM/dd HH:mm:ss ZZ")
.option("header", "true")
.option("multiLine", true)
.load("./secondHandHouse/深圳链家二手房成交明细.csv")//todo: 3、注册成表
df.createOrReplaceTempView("house_sale")
session.sql("select floor from house_sale limit 30").show()//todo: 4、注册UDAF函数
session.udf.register("udaf",new MyAverage)//todo: 5、然后按照楼层进行分组,求取每个楼层的平均成交金额
session.sql("select floor, udaf(house_sale_money) from house_sale group by floor").show()
//todo: 6、关闭
session.stop()
}
}//todo: 自定义UDAF函数
class MyAverage extends UserDefinedAggregateFunction {
/**
* 可以看出,继承这个类之后,要重写里面的八个方法, 每个方法代表的含义是:
inputSchema:输入数据的类型
bufferSchema:产生中间结果的数据类型
dataType:最终返回的结果类型
deterministic:确保一致性(输入什么类型的数据就返回什么类型的数据),一般用true
initialize:指定初始值
update:每有一条数据参与运算就更新一下中间结果(update相当于在每一个分区中的运算)
merge:全局聚合(将每个分区的结果进行聚合)
evaluate:计算最终的结果
*/// todo: 输入数据的类型
def inputSchema: StructType = StructType(StructField("floor", DoubleType) :: Nil)// todo: 产生中间结果的数据类型
def bufferSchema: StructType = {
StructType(StructField("sum", DoubleType) :: StructField("count", LongType) :: Nil)
}//todo: 最终返回的结果类型
def dataType: DataType = DoubleType//todo: 对于相同的输入是否一直返回相同的输出。
def deterministic: Boolean = true//todo: 指定初始值
def initialize(buffer: MutableAggregationBuffer): Unit = {
// 用于存储不同类型的楼房的总成交额
buffer(0) = 0D
// 用于存储不同类型的楼房的总个数
buffer(1) = 0L
}//todo: 相同Execute间的数据合并。(分区内聚合)
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
//每有一条数据参与运算就更新一下中间结果
if (!input.isNullAt(0)) {
buffer(0) = buffer.getDouble(0) + input.getDouble(0)
buffer(1) = buffer.getLong(1) + 1
}
}//todo: 不同Execute间的数据合并(全局聚合)
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getDouble(0) + buffer2.getDouble(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}//todo: 计算最终结果
def evaluate(buffer: Row): Double = buffer.getDouble(0) / buffer.getLong(1)
}
自定义UDTF函数(对单个数据进行拆分,拆分后多行数据)
package com.kaikeba.sql
import java.util.ArrayList
import org.apache.hadoop.hive.ql.exec.{UDFArgumentException, UDFArgumentLengthException}
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory
import org.apache.hadoop.hive.serde2.objectinspector.{ObjectInspector, ObjectInspectorFactory, StructObjectInspector}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
//todo: 自定义UDTF函数:多对一
object CustomSparkUDTF {
def main(args: Array[String]): Unit = {//todo: 1、构建SparkSession
val sparkConf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("CustomSparkUDTF")
val session: SparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
session.sparkContext.setLogLevel("WARN")//todo: 2、加载csv文件
val df: DataFrame = session
.read
.format("csv")
.option("timestampFormat", "yyyy/MM/dd HH:mm:ss ZZ")
.option("header", "true")
.option("multiLine", true)
.load("./secondHandHouse/深圳链家二手房成交明细.csv")//todo: 3、注册成表
df.createOrReplaceTempView("house_sale")
//todo: 4、注册udtf函数
// 注册utdf算子,这里无法使用sparkSession.udf.register(),注意包全路径
session.sql("create temporary function mySplit as 'com.kaikeba.sql.myUDTF'")//todo: 5、将part_place(部分地区)以空格切分进行展示
session.sql("select part_place, mySplit(part_place,' ') from house_sale limit 50").show()//todo: 6、关闭
session.stop()
}
}//todo: 自定义UDTF函数
class myUDTF extends GenericUDTF {
// 该函数的作用:①输入参数校验,只能传递一个参数 ②指定输出的字段名和字段类型
override def initialize(args: Array[ObjectInspector]): StructObjectInspector = {
//参数个数校验,判断参数是否为2
if (args.length != 2) {
throw new UDFArgumentLengthException("UserDefinedUDTF takes only two argument")
}
// 用于验证参数的类型,判断第一个参数是不是字符串参数
if (args(0).getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentException("UserDefinedUDTF takes string as a parameter")
}//初始化表结构
//创建数组列表存储表字段
val fieldNames: ArrayList[String] = new ArrayList[String]()
var fieldOIs: ArrayList[ObjectInspector] = new ArrayList[ObjectInspector]()
// 输出字段的名称
fieldNames.add("newColumn")// 这里定义的是输出列字段类型
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector)
//将表结构两部分聚合在一起
ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs)
}// 用于处理数据,入参数组objects里只有1行数据,即每次调用process方法只处理一行数据
override def process(objects: Array[AnyRef]): Unit = {
//获取数据
val data: String = objects(0).toString
//获取分隔符
val splitKey: String = objects(1).toString()
//切分数据
val words: Array[String] = data.split(splitKey)//遍历写出
words.foreach(x => {
//将数据放入集合
var tmp: Array[String] = new Array[String](1)
tmp(0) = x
//写出数据到缓冲区
forward(tmp)
})
}override def close(): Unit = {
}
}
sparkSQL整合hive
1、拷贝hive-site.xml配置文件
将node03服务器安装的hive家目录下的conf文件夹下面的hive-site.xml拷贝到spark安装的各个机器节点,node03执行以下命令进行拷贝
cd /kkb/install/hive-1.1.0-cdh5.14.2/conf
cp hive-site.xml /kkb/install/spark-2.3.3-bin-hadoop2.7/conf
scp hive-site.xml node01:/kkb/install/spark-2.3.3-bin-hadoop2.7/conf
scp hive-site.xml node02:/kkb/install/spark-2.3.3-bin-hadoop2.7/conf
2、拷贝mysql连接驱动包
将hive当中mysql的连接驱动包拷贝到spark安装家目录下的lib目录下,node03执行下命令拷贝mysql的lib驱动包
cd /kkb/install/hive-1.1.0-cdh5.14.2/lib/
cp mysql-connector-java-5.1.38.jar /kkb/install/spark-2.3.3-bin-hadoop2.7/jars
scp mysql-connector-java-5.1.38.jar node01:/kkb/install/spark-2.3.3-bin-hadoop2.7/jars
scp mysql-connector-java-5.1.38.jar node02:/kkb/install/spark-2.3.3-bin-hadoop2.7/jars
3、进入spark-sql直接操作hive数据库当中的数据
在spark2.0版本后由于出现了sparkSession,在初始化sqlContext的时候,会设置默认的spark.sql.warehouse.dir=spark-warehouse,
此时将hive与sparksql整合完成之后,在通过spark-sql脚本启动的时候,还是会在哪里启动spark-sql脚本,就会在当前目录下创建一个spark.sql.warehouse.dir为spark-warehouse的目录,存放由spark-sql创建数据库和创建表的数据信息,与之前hive的数据息不是放在同一个路径下(可以互相访问)。但是此时spark-sql中表的数据在本地,不利于操作,也不安全。
-
所有在启动的时候需要加上这样一个参数:
-
--conf spark.sql.warehouse.dir=hdfs://node01:8020/user/hive/warehouse
-
保证spark-sql启动时不在产生新的存放数据的目录,sparksql与hive最终使用的是hive同一存放数据的目录
-
-
spark-sql \
--master spark://node01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
--conf spark.sql.warehouse.dir=hdfs://node01:8020/user/hive/warehouse
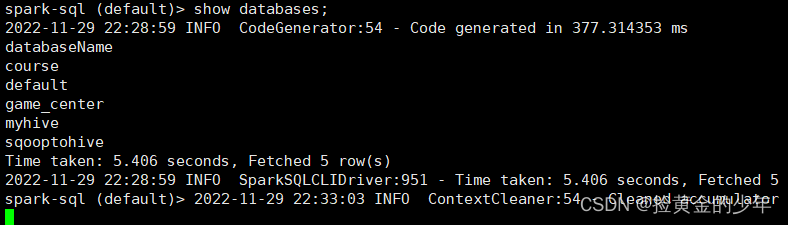
5、执行sql语句操作hive表数据
6、通过脚本的方式跑sql作业==
#!/bin/sh
#定义sparksql提交脚本的头信息
SUBMITINFO="spark-sql --master spark://node01:7077 --executor-memory 1g --total-executor-cores 2 --conf spark.sql.warehouse.dir=hdfs://node01:8020/user/hive/warehouse"
#定义一个sql语句
SQL="select * from hive_source;"
#执行sql语句 类似于 hive -e sql语句
echo "$SUBMITINFO"
echo "$SQL"
$SUBMITINFO -e "$SQL"
spark的thrift server与hive进行远程交互
1、node03执行以下命令修改hive-site.xml的配置属性,添加以下几个配置
cd /kkb/install/hive-1.1.0-cdh5.14.2/conf
vim hive-site.xml
<property>
<name>hive.metastore.uris</name>
<value>thrift://node03:9083</value>
<description>Thrift URI for the remote metastore</description>
</property>
<property>
<name>hive.server2.thrift.min.worker.threads</name>
<value>5</value>
</property>
<property>
<name>hive.server2.thrift.max.worker.threads</name>
<value>500</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10021</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node03</value>
</property>
2、修改完的配置文件分发到其他机器
cd /kkb/install/hive-1.1.0-cdh5.14.2/conf
cp hive-site.xml /kkb/install/spark-2.3.3-bin-hadoop2.7/conf
scp hive-site.xml node01:/kkb/install/spark-2.3.3-bin-hadoop2.7/conf
scp hive-site.xml node02:/kkb/install/spark-2.3.3-bin-hadoop2.7/conf
3、在node03启动metastore服务
cd /kkb/install/hive-1.1.0-cdh5.14.2/
bin/hive --service metastore
4、node03执行以下命令启动spark的thrift server
注意:hive安装在哪一台,就在哪一台服务器启动spark的thrift server
cd /kkb/install/spark-2.3.3-bin-hadoop2.7
sbin/start-thriftserver.sh --master spark://node01:7077 --executor-memory 1g --total-executor-cores 2
查看日志信息,是否启动,日志目录如下
/kkb/install/hive-1.1.0-cdh5.14.2/logs/hive.log
启动后可以查看日志信息,下面日志这个就是hive连接不到MySQL,
2022-11-29 21:07:40,046 ERROR [BoneCP-pool-watch-thread]: bonecp.BoneCP (BoneCP.java:obtainInternalConnection(292)) - Failed to acquire connection to
jdbc:mysql://node03:3306/hive?createDatabaseIfNotExist=true&characterEncoding=latin1&useSSL=false
. Sleeping for 7000 ms. Attempts left: 1
java.sql.SQLException: No suitable driver found for
jdbc:mysql://node03:3306/hive?createDatabaseIfNotExist=true&characterEncoding=latin1&useSSL=false
我查找到几种解决方案
我出现的问题就是格式问题,我用idea把hive-site.xml内容格式化一下,格式后,虽然好看,但是version不在同一列,所以hive连接不到MySQL,所以也找到不到MySQL元数据信息
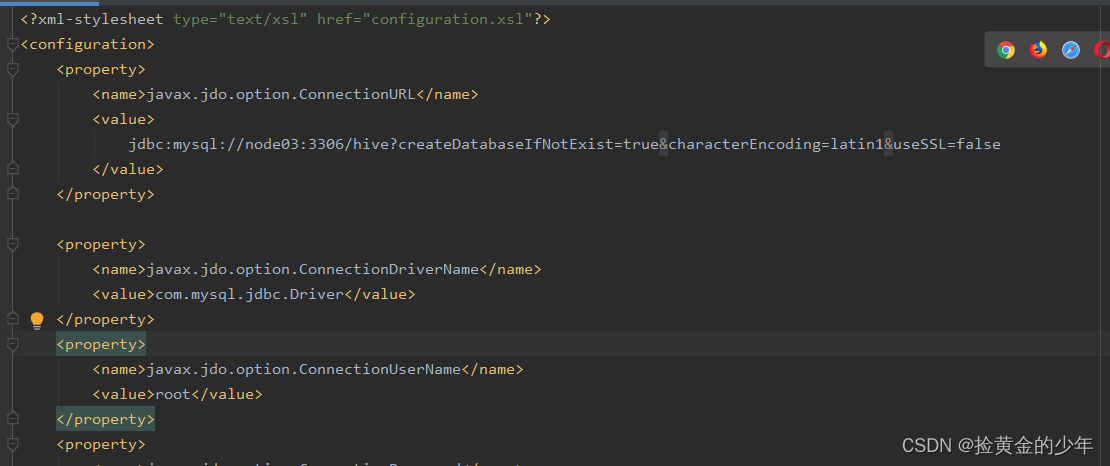
正确的如下
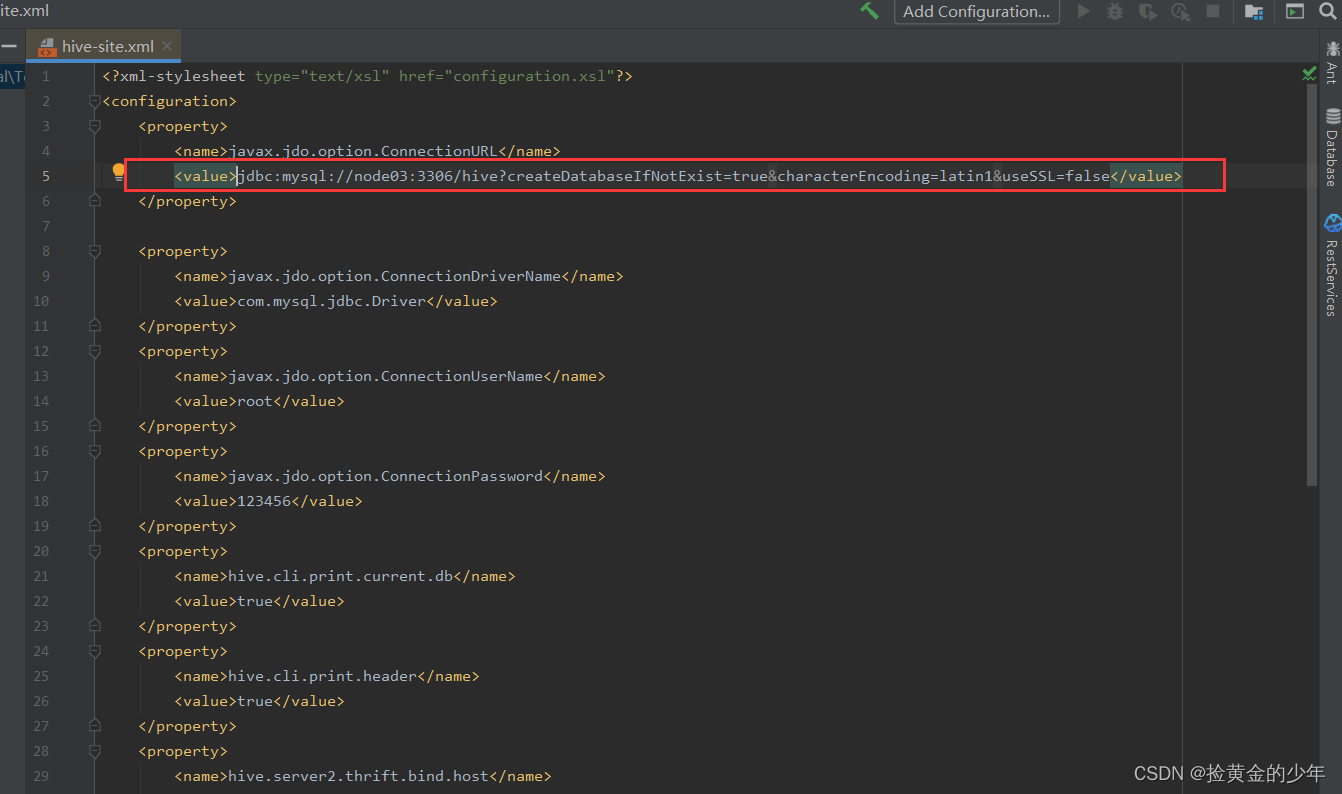
修改了hive-site.xml信息,则重启一下metastore服务
5、配置完成之后
直接使用beeline来连接
直接在node03服务器上面使用beeline来进行连接spark-sql
cd /kkb/install/spark-2.3.3-bin-hadoop2.7
bin/beelinebeeline> !connect jdbc:hive2://node03:10021
Connecting to jdbc:hive2://node03:10021
Enter username for jdbc:hive2://node03:10021: hadoop
Enter password for jdbc:hive2://node03:10021: 123456
 如果报错连接不上,先去查询thrift server启动状况,查看日志,再查看hive日志,逐层解决问题
如果报错连接不上,先去查询thrift server启动状况,查看日志,再查看hive日志,逐层解决问题
sparkSQL采用API操作hive
项目引入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.3.3</version>
</dependency>
-
2、将服务端配置hive-site.xml,放入idea工程中的resources路径下
-
3、在项目根目录下创建一个data目录,然后创建文件person.txt,准备测试数据
import org.apache.spark.sql.{DataFrame, SparkSession}
//todo: 通过代码开发实现sparksql操作hive表
object SparkSQLOnHive {
def main(args: Array[String]): Unit = {
//todo: 1、构建SparkSession对象
val spark: SparkSession = SparkSession.builder()
.appName("HiveSupport")
.master("local[2]")
.enableHiveSupport() //开启对hive的支持
.getOrCreate()//todo: 2、直接使用sparkSession去操作hivesql语句
//2.1 创建一张hive表
spark.sql("create table if not exists default.kaikeba(id string,name string,age int) row format delimited fields terminated by ','")//2.2 加载数据到hive表中
spark.sql("load data local inpath './data/kaikeba.txt' into table default.kaikeba ")//2.3 查询
spark.sql("select * from default.kaikeba").show()
spark.sql("select count(*) from default.kaikeba").show()//todo: 关闭SparkSession
spark.stop()
}
} -
sparkSQL的执行过程
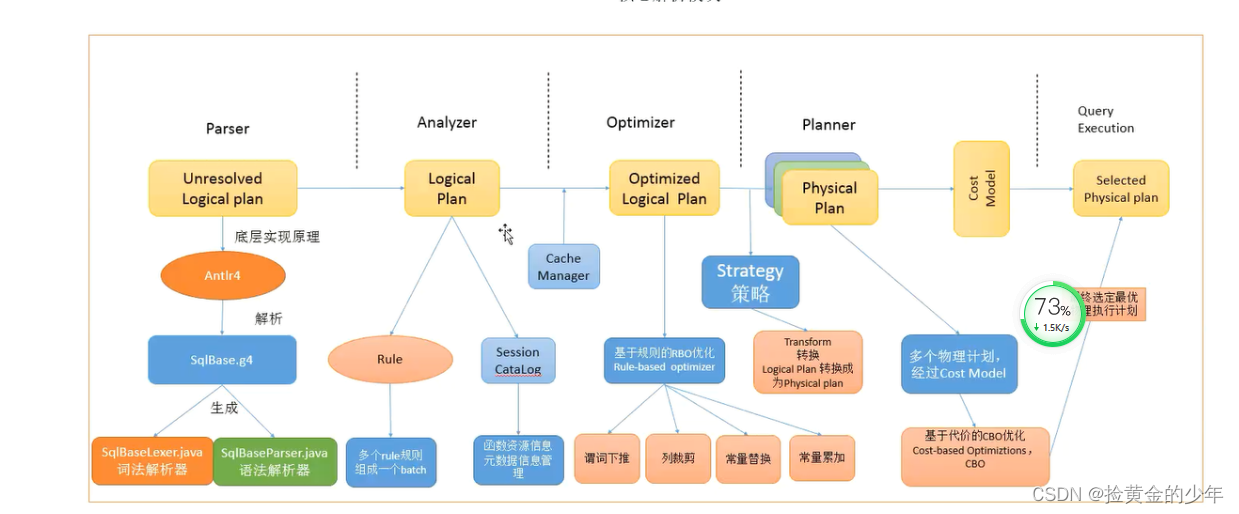
1、输入sql,dataFrame或者dataSet
2、通过Parser进行SQL语法的解析,底层是有一个Antlr4解析SQL,基于SqlBase.g4对sql语法词法的解析,之后他形成一个语法树,这个语法树就是( Unresolved Logical Plan (未解析的逻辑计划 )
3、然后我们基于未解析的逻辑计划,用到Analyzer(分析器),将未解析的逻辑计划解析成,解析后的逻辑计划,
4、然后使用到Optimizer优化器,进行解析逻辑计划的优化,使用到一些RBO优化规则,如谓词下推,列裁剪,常亮替换,常亮累加等
5、经过我们的优化器优化后,再进行一些转换,转化成对应的一些物理计划physical plans(后序我们要将物理计划翻译成代码,到spark集群运行)
6、然后利用代价模型(cost model)选择最佳的 physical plan;即物理执行计划
7、Code Generation(代码生成器):这个过程会把 SQL 查询生成 Java 字 节码。即代码生成阶段