博主简介
博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c++,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,如果有错误之处,大家可以指正。
专栏简介: 本专栏主要研究计算机视觉,涉及算法,案例实践,网络模型等知识。包括一些常用的数据处理算法,也会介绍很多的Python第三方库。如果需要,点击这里订阅专栏 。
给大家分享一个我很喜欢的一句话:“每天多努力一点,不为别的,只为日后,能够多一些选择,选择舒心的日子,选择自己喜欢的人!”

目录
前言
在刚经历了AI的大变革,ChatGpt的一夜爆火,让很多人的思想一下被刷新,很多人在见识了gpt的功能后不免的担心,未来人工智能是否会取代人类。对于这个问题,我的见解是人工智能的最根本就是人,作为一种辅助工具,他只是减轻我们的工作负担,让我们能够把精力投入到更重要的事中,简单点,就是推动人类社会的发展。但是人工智能的高速发展,也在警告我们,如果我们不去尝试创新,不去思考,或许部分岗位会被人工智能替代。很多人会面临失业,无岗就业。这也是人工智能发展会带来的必然后果。所以如果不想被人工智能所摒弃,我们更应该去驾驭它,而不是去担忧他是否会威胁到我们。
机器学习简介
人工智能和机器学习又有什么相关联喃?人工智能中讲得最多的就是对数据的处理,如果说人一秒处理一条信息,那么一天就是86400条,一年就是31536000条,这还是不停的状态下,显然是不存在的,况且对于现在的大数据,一天的数据量超过几亿条,单单的靠人是不可能处理的,所以这时候机器学习的优势就体现出来了。对于大量的数据,机器学习可以很快地处理完毕,但是,机器学习的速度只是相比较人类的速度而言是比较快的,和深度学习相比,速度还是很慢的。对于深度学习,神经网络,相信很多小伙伴都听过,但是却不知道具体的概念,或者说他们之间的关系。所以就没有很好的学习路径。这几天博主正在整理它们之间的关系。后面会出一个章节来介绍它们之间的关系,以及学习的路径。方便大家学习人工智能。
机器学习模型分类
一般来说,我们会把数据分成训练集和测试集,这是为了防止过拟合。我们知道只要参数够多,我们就能拟合任意的函数,所以我们会在训练集对我们的模型进行训练,使其对训练集的分类准确率变高,之后在测试集上测试,如果在测试集上准确率也很高,那么我们就认为这个模型是可靠的。
根据数据有无标签,机器学习可以分为有监督学习和无监督学习,当然还有近年来型出现的半监督学习。有时候我们没有足够的标签,例如,从一亿中张图片找到包含人脸的图片,就要对一亿张图片进行标记,这是相当困难的事情,所以,我们就可以采用高中生物上讲过的抽样,从这么多的照片中抽取一部分进行标记,然后对这部分数据进行有监督学习。第二种是直接对所有数据集进行无监督学习。
根据不同的学习目标,机器学习模型又可以分成生成式模式和判别式模型。生成式模型预测数据的分布,例如高斯分布,判别式模型则是预测数据的分类,例如图像有人脸还是没有。判别模式在预测方面更具优势,而生成模式往往用来产生新的数据,也更容易被理解。举个例子,对于画面,判别式模型只能判别画的对不对,而生成模式可以自己作画。
根据数据表标签是连续的还是非连续的,机器学习模型又可以分为分类器和回归器。对于非连续的标签,我们往往使用分类器把每个标签看作一类;反之,对于连续的标签,我们往往使用回归器,目标值为任意实数,也可以认为在值域中的每个实数为一类。

OpenCV机器学习数据流
在机器学习中,第一部也是最重要的一步就是数据流的搭建,在现实中,数据往往不是规则化的或是格式化的。这些情况对我们进行模型搭建不利。所以就需要一个类来实现数据处理,那就是cv2.TrainData.
| virtual | ~TrainData () |
| virtual int | getCatCount (int vi) const =0 |
| virtual Mat | getCatMap () const =0 |
| virtual Mat | getCatOfs () const =0 |
| virtual Mat | getClassLabels () const =0 |
| Returns the vector of class labels. More... | |
| virtual Mat | getDefaultSubstValues () const =0 |
| virtual int | getLayout () const =0 |
| virtual Mat | getMissing () const =0 |
| virtual int | getNAllVars () const =0 |
| virtual void | getNames (std::vector< String > &names) const =0 |
| Returns vector of symbolic names captured in loadFromCSV() More... | |
| virtual Mat | getNormCatResponses () const =0 |
| virtual void | getNormCatValues (int vi, InputArray sidx, int *values) const =0 |
| virtual int | getNSamples () const =0 |
| virtual int | getNTestSamples () const =0 |
| virtual int | getNTrainSamples () const =0 |
| virtual int | getNVars () const =0 |
| virtual Mat | getResponses () const =0 |
| virtual int | getResponseType () const =0 |
| virtual void | getSample (InputArray varIdx, int sidx, float *buf) const =0 |
| virtual Mat | getSamples () const =0 |
| virtual Mat | getSampleWeights () const =0 |
| virtual Mat | getTestNormCatResponses () const =0 |
| virtual Mat | getTestResponses () const =0 |
| virtual Mat | getTestSampleIdx () const =0 |
| virtual Mat | getTestSamples () const =0 |
| Returns matrix of test samples. More... | |
| virtual Mat | getTestSampleWeights () const =0 |
| virtual Mat | getTrainNormCatResponses () const =0 |
| Returns the vector of normalized categorical responses. More... | |
| virtual Mat | getTrainResponses () const =0 |
| Returns the vector of responses. More... | |
| virtual Mat | getTrainSampleIdx () const =0 |
| virtual Mat | getTrainSamples (int layout=ROW_SAMPLE, bool compressSamples=true, bool compressVars=true) const =0 |
| Returns matrix of train samples. More... | |
| virtual Mat | getTrainSampleWeights () const =0 |
| virtual void | getValues (int vi, InputArray sidx, float *values) const =0 |
| virtual Mat | getVarIdx () const =0 |
| virtual Mat | getVarSymbolFlags () const =0 |
| virtual Mat | getVarType () const =0 |
| virtual void | setTrainTestSplit (int count, bool shuffle=true)=0 |
| Splits the training data into the training and test parts. More... | |
| virtual void | setTrainTestSplitRatio (double ratio, bool shuffle=true)=0 |
| Splits the training data into the training and test parts. More... | |
| virtual void | shuffleTrainTest ()=0 |
详细的类容,可以参考:TrainData中的常用方法。
我们的首要任务就是对数据进行打包,在TrainData中,我们使用create()方法,将数据转化成opencv可识别的矩阵。此方法的参数是:输入矩阵samples(float32),输出矩阵response,训练变量varIdx、训练样本sampleIdx、样本权重sampleWeights。这里需要注意的是,传统图像都是三通道,这里的输入必须是单通道,所以,可以将每一个像素按行排列,而每一列就是此像素的每一个特征。同时,对于不是浮点型数据的数据,就需要进行转换,但是必须一一对应,最常用的就是空值,或者缺失值。一般设为-1.0或者-9999.0.
对于数据存储,我们存储的格式为csv,在python中,一般用loadFromCSV()方法,该方法的参数为:文件名filename、跳过头函数headerLineCount、特征开始编号responseStartIdx、特征结束编号responseEndIdx、特征类型varTypeSpec、分隔符delimiter和缺失值符号missch。
读取了数据后,我们需要对数据进行分割,除了分成训练集、测试集之外,有时由于数据量过于庞大,我们还需要将其切分为不同的部分再进行训练,这在深度学习中非常常用。
分割训练集和测试集可以使用setrainTestSplit()、setTrainTestSplitRatio()和shuffleTrainTest()等方法。其中前两个方法都是指定训练集数量,而最后一个则是随机分配。
分割后查看训练集和测试集则用getTrainSample()和getTestSamples()方法。
OpenCV机器学习算法
OpenCV中的ML库复杂机器学习,其中包括了各种常用算法。
| lass | cv::ml::ANN_MLP |
| Artificial Neural Networks - Multi-Layer Perceptrons. More... | |
| class | cv::ml::Boost |
| Boosted tree classifier derived from DTrees. More... | |
| class | cv::ml::DTrees |
| The class represents a single decision tree or a collection of decision trees. More... | |
| class | cv::ml::EM |
| The class implements the Expectation Maximization algorithm. More... | |
| class | cv::ml::SVM::Kernel |
| class | cv::ml::KNearest |
| The class implements K-Nearest Neighbors model. More... | |
| class | cv::ml::LogisticRegression |
| Implements Logistic Regression classifier. More... | |
| class | cv::ml::DTrees::Node |
| The class represents a decision tree node. More... | |
| class | cv::ml::NormalBayesClassifier |
| Bayes classifier for normally distributed data. More... | |
| class | cv::ml::ParamGrid |
| The structure represents the logarithmic grid range of statmodel parameters. More... | |
| class | cv::ml::RTrees |
| The class implements the random forest predictor. More... | |
| struct | cv::ml::SimulatedAnnealingSolverSystem |
| This class declares example interface for system state used in simulated annealing optimization algorithm. More... | |
| class | cv::ml::DTrees::Split |
| The class represents split in a decision tree. More... | |
| class | cv::ml::StatModel |
| Base class for statistical models in OpenCV ML. More... | |
| class | cv::ml::SVM |
| Support Vector Machines. More... | |
| class | cv::ml::SVMSGD |
| Stochastic Gradient Descent SVM classifier. More... | |
| class | cv::ml::TrainData |
| Class encapsulating training data. More... | |
详细的可以去官网查看:OpenCV机器学习类。
1.cv2.KNearest(),K近邻算法,最简单的分类器之一,对于测试数据,由于其距离最近的K个训练样本进行投票,从而确定分类结果。
2.cv2.EM(),EM算法,用于将多个高斯分布的和分离,换言之,用多个高斯分布去拟合数据。
3.cv2.DTress(),决策树模型,经常作为判别分类器,在树的每一个节点,通过数据特征和一个阈值将数据划分到不同的子结点中,最后使得叶子节点只存在一类数据。此种方法训练慢,测试快。
4.cv2.Boost(),随即森林中的boosting方法,训练多棵树,加权求和所有树得到最终的结果。每棵树的训练目标为之前树的和与真实值之间的残差。
5.cv2.LogisticBayesClassifier(),逻辑回归,虽然叫回归,但是大多数时候用于分类问题。逻辑函数是在线性模型的基础上,加入sigmoid激活函数,从而实现将输出归一化到[0,1],作为分类的概率值。
6.cv2.NormalBayesClassifier(),朴素贝叶斯模型,此模型是基于贝叶斯概率和贝叶斯定理的模型。
7.cv2.SVM()算法,最经典的机器学习模型,此模型支持向量机(SVM),既可以用于分类,又可以用于回归,可以对任意维度的空间进行建模。方法是将低维的非线性分类转换到高维的线性分类。
K近邻算法的实现
import cv2
import numpy as np
import matplotlib.pyplot as plt
#生成训练集
trainData=np.random.randint(0,100,(25,2)).astype(np.float32)
#生成标签
respose=np.random.randint(0,2,(25,1)).astype(np.float32)
#标签为1则画红色
red=trainData[respose.ravel()==1]
plt.scatter(red[:,0],red[:,1],80,'r','^')
#标签为2则画蓝色
blue=trainData[respose.ravel()==0]
plt.scatter(blue[:,0],blue[:,1],80,'b','s')
#生成测试点
newcomer=np.random.randint(0,50,(1,2)).astype(np.float32)
#创建KNN
knn=cv2.ml.KNearest_create()
#训练
knn.train(trainData,cv2.ml.ROW_SAMPLE,respose)
#测试,k=3
ret,results,neighbours,dist=knn.findNearest(newcomer,3)
#按结果画出点
if results == np.array([[1.0]]):
plt.scatter(newcomer[:,0],newcomer[:,1],80,'r','o')
else:
plt.scatter(newcomer[:,0],newcomer[:,1],80,'b','o')
plt.show()
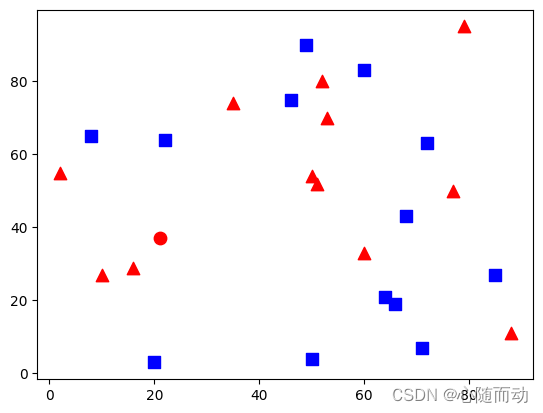
ML库中的所有算法都是基于公共基类cv2.StateModel继承而来,包括所有训练和预测方法。其中常用的方法就是train():训练,此方法可选参数为输入样本samples、模型参数值、输出response;predict()方法:预测,此方法的可选参数为输入样本samples、输出结果results、模型参数值。
好了,本节的内容就到此结束了,很抱歉,由于学业繁忙,所以很久没更了,后面我会抽空更新的。下一节我们学习向量机支持的目标检测与识别。大家用空夺去opencv官网看看各函数的使用。
拜拜了你嘞!
