
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。
学习日记
目录
一、前言
在学习数据结构和算法的时候,经常会碰到 O(1),O(n)等等用来表示时间和空间复杂度,那这到底是什么意思。我们对于同一个问题经常有不同的解决方式,比如排序算法就有十种经典排序(快排,归并排序等),虽然对于排序的结果相同,但是在排序过程中消耗时间和资源却是不同。
对于不同排序算法之间的衡量方式就是通过程序执行所占用的时间和空间两个维度去考量。
二、 时间复杂度
判断一个算法所编程序运行时间的多少,并不是将程序编写出来,通过在计算机上运行所消耗的时间来度量。原因很简单,一方面,解决一个问题的算法可能有很多种,一一实现的工作量无疑是巨大的,得不偿失;另一方面,不同计算机的软、硬件环境不同,即便使用同一台计算机,不同时间段其系统环境也不相同,程序的运行时间很可能会受影响,严重时甚至会导致误判。
实际场景中,我们更喜欢用一个估值来表示算法所编程序的运行时间。所谓估值,即估计的、并不准确的值。注意,虽然估值无法准确的表示算法所编程序的运行时间,但它的得来并非凭空揣测,需要经过缜密的计算后才能得出。
也就是说,表示一个算法所编程序运行时间的多少,用的并不是准确值(事实上也无法得出),而是根据合理方法得到的预估值。那么,如何预估一个算法所编程序的运行时间呢?很简单,先分别计算程序中每条语句的执行次数,然后用总的执行次数间接表示程序的运行时间。
以一段简单的 C 语言程序为例,预估出此段程序的运行时间:
for(int i = 0 ; i < n ; i++) //<- 从 0 到 n,执行 n+1 次
{
a++; //<- 从 0 到 n-1,执行 n 次
}可以看到,这段程序中仅有 2 行代码,其中:
- for 循环从 i 的值为 0 一直逐增至 n(注意,循环退出的时候 i 值为 n),因此 for 循环语句执行了 n+1 次;
- 而循环内部仅有一条语句,a++ 从 i 的值为 0 就开始执行,i 的值每增 1 该语句就执行一次,一直到 i 的值为 n-1,因此,a++ 语句一共执行了 n 次。
因此,整段代码中所有语句共执行了 (n+1)+n 次,即 2n+1 次。数据结构中,每条语句的执行次数,又被称为该语句的频度。整段代码的总执行次数,即整段代码的频度。
扫描二维码关注公众号,回复: 14602015 查看本文章
例:
for(int i = 0 ; i < n ; i++) // n+1 { for(int j = 0 ; j < m ; j++) // n*(m+1) { num++; // n*m } }
比较以上 2 段程序的运行时间,即比较 2n+1 和 2*n2+2*n+1 的大小,显然当 n 无限大时,前者要远远小于后者。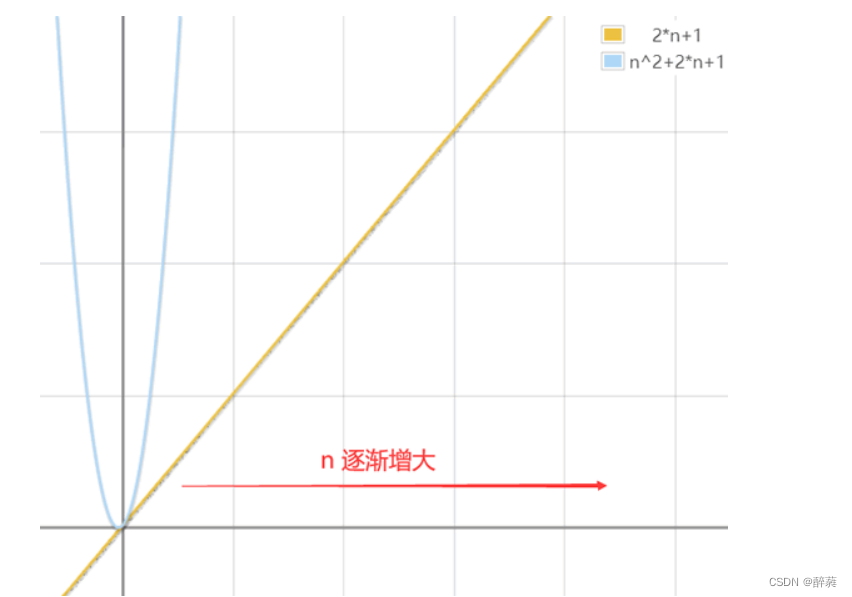
我们把 算法需要执行的运算次数 用 输入大小n 的函数 表示,即 T(n) 。
此时为了 估算算法需要的运行时间 和 简化算法分析,我们引入时间复杂度的概念。定义:存在常数 c 和函数 f(N),使得当 N >= c 时 T(N) <= f(N),表示为 T(n) = O(f(n)) 。
当 N >= 2 的时候,f(n) = n^2 总是大于 T(n) = n + 2 的,于是我们说 f(n) 的增长速度是大于或者等于 T(n) 的,也说 f(n) 是 T(n) 的上界,可以表示为 T(n) = O(f(n))。
因为f(n) 的增长速度是大于或者等于 T(n) 的,即T(n) = O(f(n)),所以我们可以用 f(n) 的增长速度来度量 T(n) 的增长速度,所以我们说这个算法的时间复杂度是 O(f(n))。
算法的时间复杂度,用来度量算法的运行时间,记作: T(n) = O(f(n))。它表示随着 输入大小n 的增大,算法执行需要的时间的增长速度可以用 f(n) 来描述。
显然如果 T(n) = n^2,那么 T(n) = O(n^2),T(n) = O(n^3),T(n) = O(n^4) 都是成立的,但是因为第一个 f(n) 的增长速度与 T(n) 是最接近的,所以第一个是最好的选择,所以我们说这个算法的复杂度是 O(n^2) 。
算法的时间复杂度是logn的,一定是log 以2为底n的对数么?
其实不然,也可以是以10为底n的对数,也可以是以20为底n的对数,但我们统一说 logn,也就是忽略底数的描述。
我们在决定使用那些算法的时候 ,不是时间复杂越低的越好,要考虑数据规模,如果数据规模很小 甚至可以用O(n^2)的算法比 O(n)的更合适
大O其实就是数据量级突破一个点且数据量级非常大的情况下所表现出的时间复杂度,这个点也就是 常数项系数已经不起决定性作用的点。