- 相关资源: github
- 注意:部分内容为个人理解,如有错误还请您不吝赐教。
第二课 图像分类与基础视觉模型
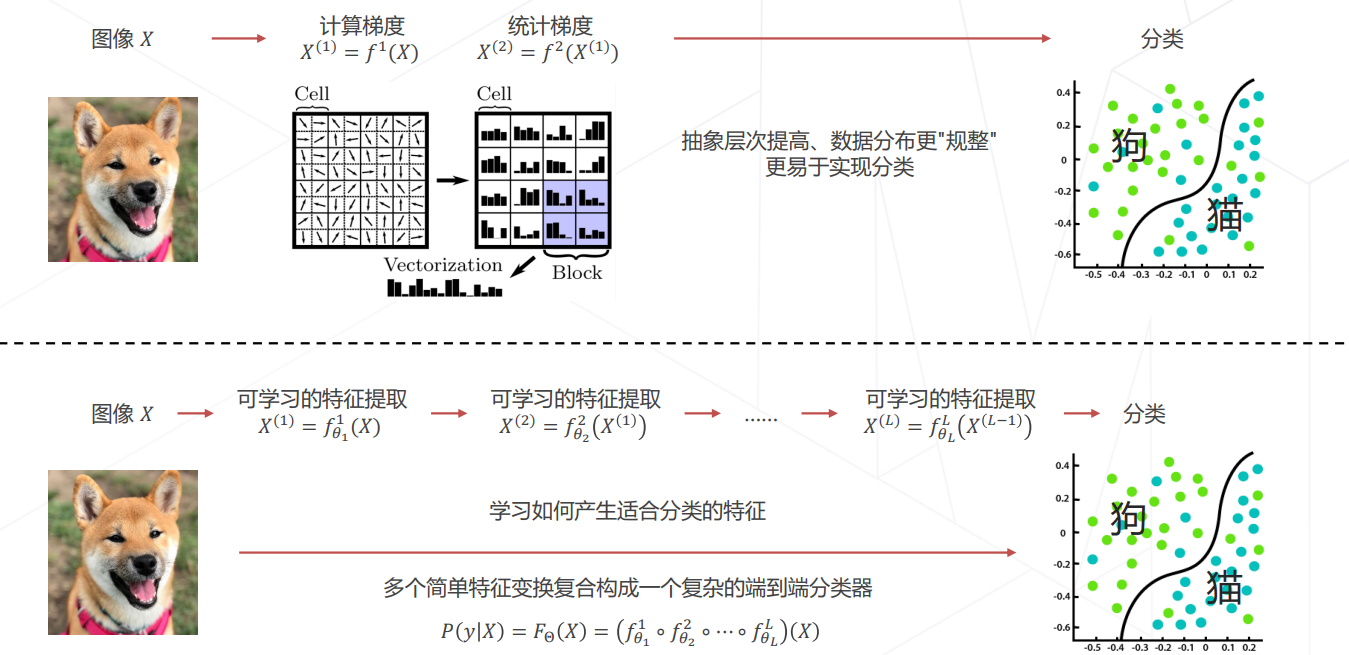
图像分类
-
【问题定义】 图像分类任务:给定一张图片,识别图像中的物体是什么 X ∈ R H ∗ W ∗ 3 → { 1 , 2.. , K } X\in R^{H*W*3} \rightarrow \{1,2..,K\} X∈RH∗W∗3→{ 1,2..,K};
-
如何教计算机认识图片中的某个物体?这种问题跟用计算机精确求解一个数学问题不一样,对于某个 object,很难像数学公式那样可以简洁的表达在计算机中,因为用数学的方式形式化关于“狗”的定义较为困难,因此要设计“识别狗”的精确算法也就无从下手。既然准确的求解方式无从下手,是否能转为以可接受的误差率进行近似的识别。
(补充:用数学语言形式化自然语言也很困难,NLP中采用的是也是概率统计方法将自然语言变成可计算的数学对象,如,矩阵和向量) -
一个朴素但实用的想法是:在图像数据( X ∈ R H ∗ W ∗ 3 X\in R^{H*W*3} X∈RH∗W∗3)上抽象出某些能形式化的特征(Feature),用计算机去检查这些特征是否存在。比如:准备一些图片数据模板(如关于“狗”的图片),用前文特征对图片进行特征提取,并将特征模板库保存下来,当面临新的输入数据时,用相同方法去提取特征,然后将提取出的特征与“狗”的特征模板库进行匹配,以判断该图片中的 object 是否是“狗”。
-
更进一步的想法:甚至略去特征模板库匹配这一过程,直接可以根据设计好的特征加权得出结论(机器学习)。
-
目前所采用的想法:用算法去学习如何进行特征提取,取代人工设计特征实现端到端的学习(深度学习)。
-
这个想法代表了“从数据中学习”的一种思考模式,通过优化数据或者优化特征(即训练学习算法的参数),可以不断提高算法的准确率。
-
关于训练集、测试集、验证集的概念请读者自行参考其他文章,本文不再赘述机器学习/深度学习基础知识。
对转化后的问题形式化如下:
- 收集数据:获得关于要识别的“object”的数据(图片即为X,图片是什么object的附加信息即为Y,也就是图片的标签label)
- 定义模型: y = F θ ( X ) y=F_{\theta}(X) y=Fθ(X)
- 训练模型(模型开发阶段):寻找最佳参数 θ ∗ \theta^* θ∗使得 y = F θ ∗ ( X ) y=F_{\theta^*}(X) y=Fθ∗(X)在训练集上达到最高的正确率
- 预测(模型应用阶段):对于新图像 X ^ \hat{X} X^,用训练好的模型预测其类别 y ^ = F θ ∗ ( X ) \hat{y}=F_{\theta^*}(X) y^=Fθ∗(X)
发展历程
- 方向梯度直方图(Histogram of Oriented Gradients)
- 特征工程 => 机器学习 => 深度学习


- 目前(2020年~)最前沿的探索是基于多头注意力机制/Transformer方法在CV方向的应用。
- 目前解决图像分类任务主要是两个部分:模型的设计(一般是深度学习模型)、模型的学习

卷积神经网络的发展
CNN 输入图片的尺寸是否需要固定?
答:取决于网络结构是否有全连接层,早期的CNN一般都有全连接层,因此对输入图片的尺寸有要求,但后期的CNN用global average pooling,没有采用全连接层,因此对输入图片的尺寸无要求。
- AlexNet(2012) - 深度学习时代的开启;首次基于 GPU 训练神经网络;8层,60M参数;

- More Deeper
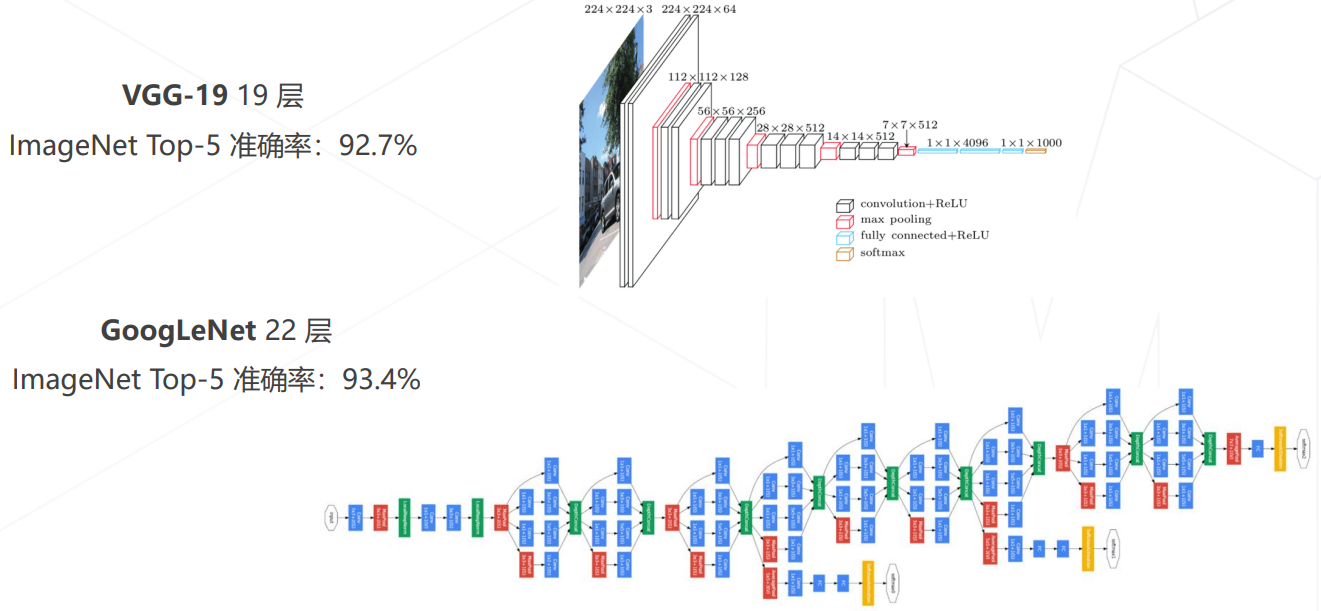
VGG, 2014
- VGG(2014):将大尺寸卷积拆解为多层 3x3 卷积;相同的感受野、更少的参数量、更多的层数、更强的表达能力;(1层 5x5 的卷积与2层 3x3 的卷积有同样的感受野,参数计算:前者5*5=25,后者2*3*3=18)
- VGG分别有11、13、16、19层版本,VGG-19代表19层的VGG,其参数量约 138M;

- 如果对 3x3 卷积进行1像素的边界padding,上图实际上空间分辨率不会缩小,即保持图像的尺寸。
- 不降低空间分辨率的卷积操作的用途的个人猜想:最开始提取图像特征时,前几层 CNN 不一定能充分提取图像的特征,过早降低图像的空间分辨率容易导致后续的深层网络缺少信息。因此先用不降低空间分辨率的卷积操作对图像进行预处理(类似滤波器的作用)。
- 倍增通道数、减半分辨率的用途的个人猜想:经过前几层CNN预处理后相邻元素的特征信息有一定冗余,减半分辨率有助于去掉冗余,并减少计算量。增加通道数是为了关注不同的特征:比如边缘信息,几何信息,颜色信息等。那为什么一般在 pooling 的同时倍增 channel 呢?猜测是为了减少信息的丢失,其他时候倍增应该也行,但会增加计算开销,分辨率减半的时候计算量减少1/4,这个时候倍增计算量增加2倍,整体来说计算量还是减半了~另外为什么不同的channel最终能关注到不同的特征?猜想是因为梯度下降的时候初始参数不一样,因为初始种子的不一样,导致后续的优化方向会有一些偏好,容易聚焦到不同的特征上(这或许也是为什么要随机初始化神经网络的参数的原因吧)。

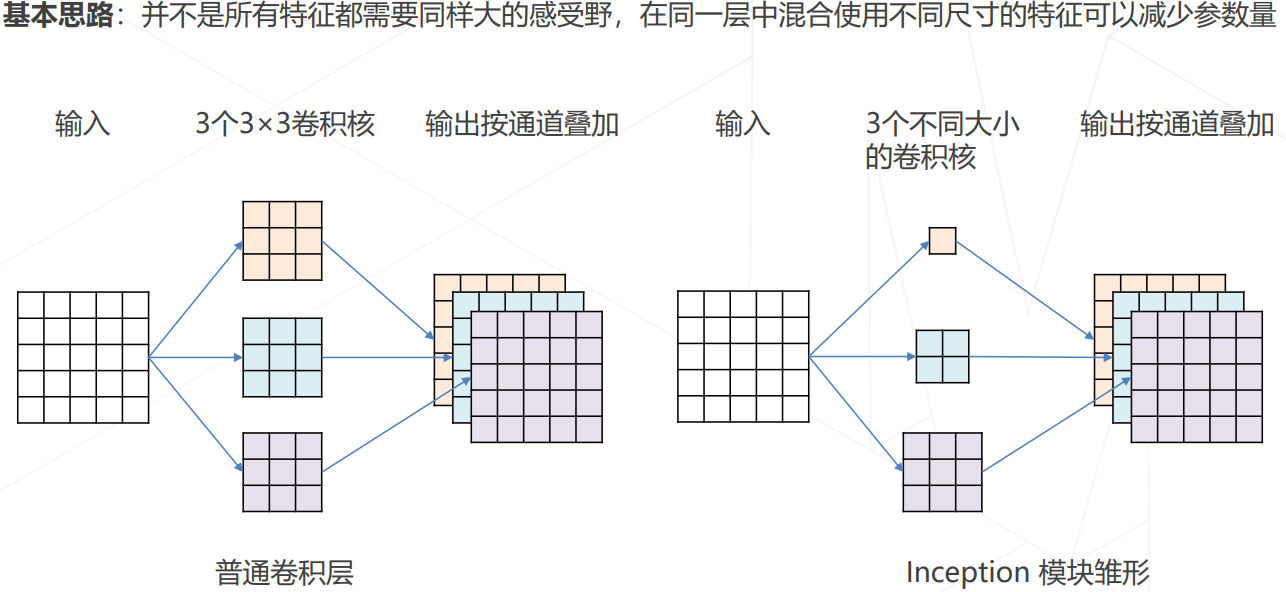
GoogLeNet Inception v1, 2014
- 2014 年 ImageNet 竞赛冠军方案;22层;7M参数(反而更少);

- 因此发现:模型层数增加到一定程度后,分类正确率不增反降

ResNet, 2015, CVPR 2016 BestPaper, CV领域引用数十万
-
Inception v1 的结果说明一味增加深度不一定更好。理论分析:当卷积运算退化为恒等映射时,深层网络与浅层网络相同(前提:padding使得空间分辨率不变,奇数宽度的卷积中心元素为1其余全0),因此:深层网络应具备不弱于浅层网络的分类精度。但实际上并不能保证这一点。
-
猜想:虽然深层网络有更强的表示能力,但优化算法难以优化。新增加一个卷积层用于拟合一个近似恒等映射,可以更好地找到这个更优的模型。=> 残差学习

-
ResNet(2015)



- 图中的概率是:ImageNet Top-5 精度,Top-1 精度;彩色数字代表对应颜色的结构的层数加深;
-
ResNet 中的两种残差模块
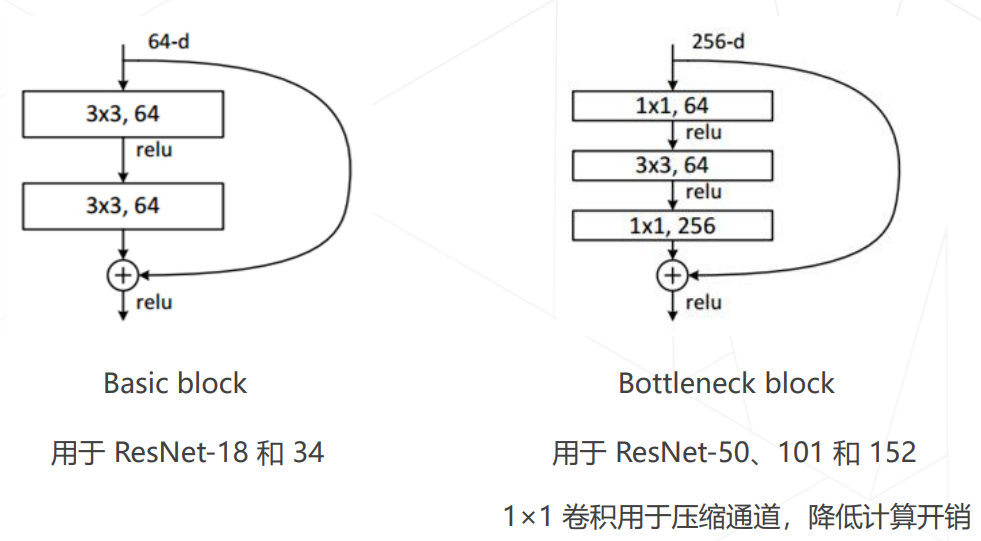
为什么残差连接 Work?- 等同于多模型集成:每个残差结构相当于有2个隐式的路径来连接输入和输出,每添加一个残差结构会让路径翻倍,最终有O(2^n)个路径。

- 残差链接让损失曲面更平滑:

- 等同于多模型集成:每个残差结构相当于有2个隐式的路径来连接输入和输出,每添加一个残差结构会让路径翻倍,最终有O(2^n)个路径。
-
ResNet 后续改进(2017~2019):

更强的图像分类模型

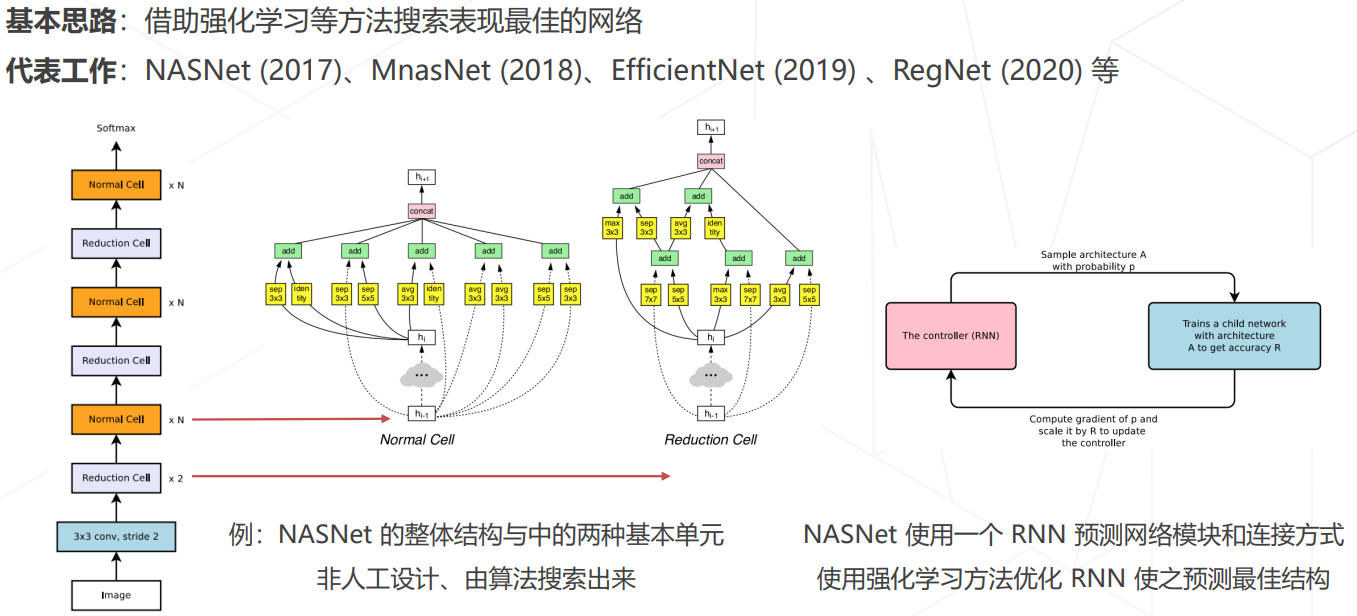
神经结构搜索 Neural Architecture Search (2016+)
Vision Transformers (2020+)
ConvNeXt (2022)

轻量化卷积神经网络
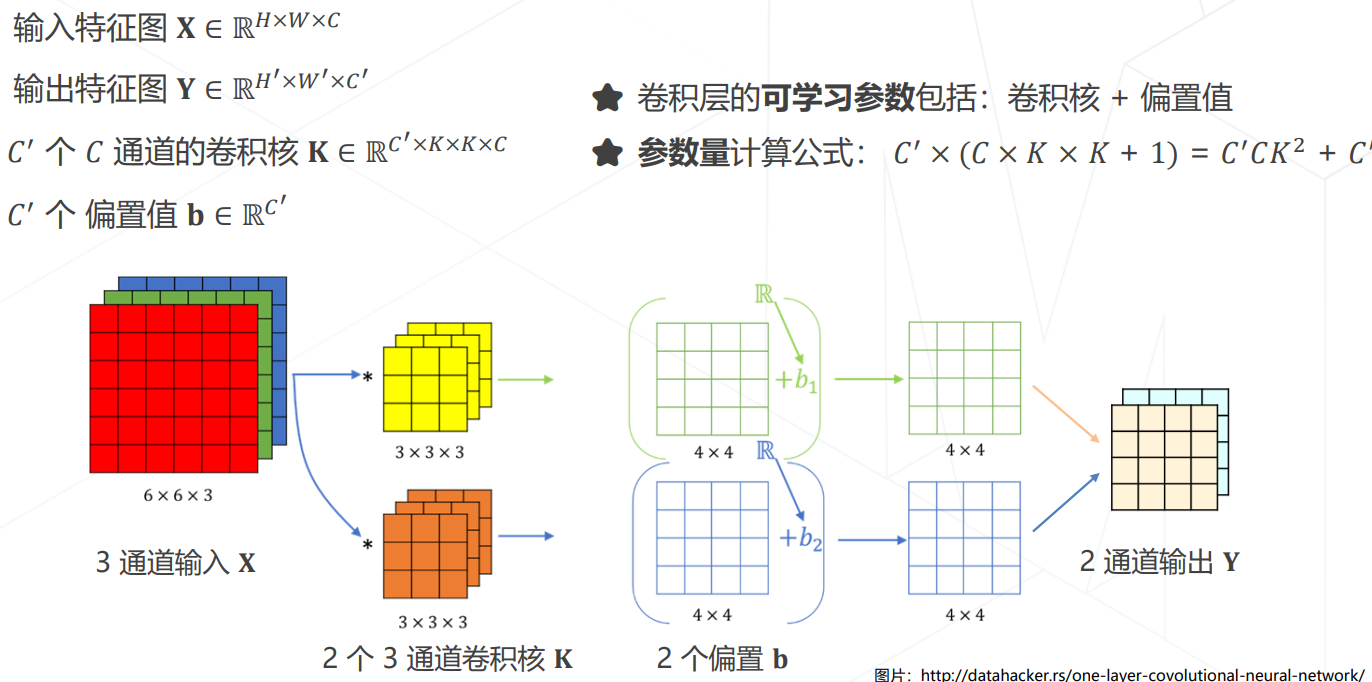
CNN 参数和计算量的计算
- 多维卷积核理解为对被卷积的多维空间的点乘求和,并对最终结果有一个偏移量。

降低模型参数量和计算量的方法

使用不同大小的卷积核:GoogLeNet
1x1 卷积压缩通道数:ResNet
- ResNet 使用1×1卷积压缩通道数:
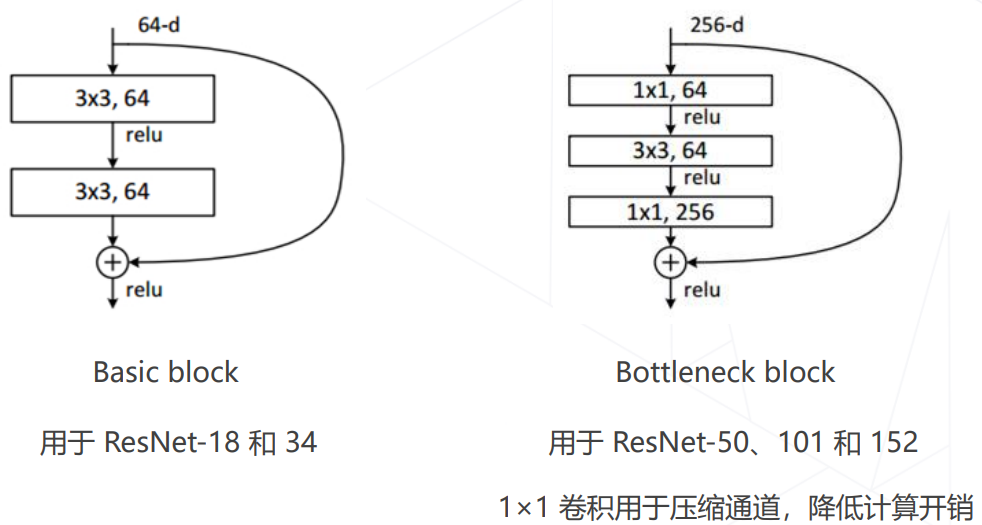
- 这种表示隐含的输入数据的通道数是上一层输出的通道数
- 1x1,64 应该是指 64x1x1x256(堆叠数量x宽x高x通道数)
- 1x1,256 应该是指 256x1x1x64(堆叠数量x宽x高x通道数)
前者参数量:73856;后者参数量:70016;(但后者保留了256维信息)
前者乘加次数:73728hw;后者乘加次数:69632hw;
可分离卷积:MobileNet V1/V2/V3 (2017~2019)
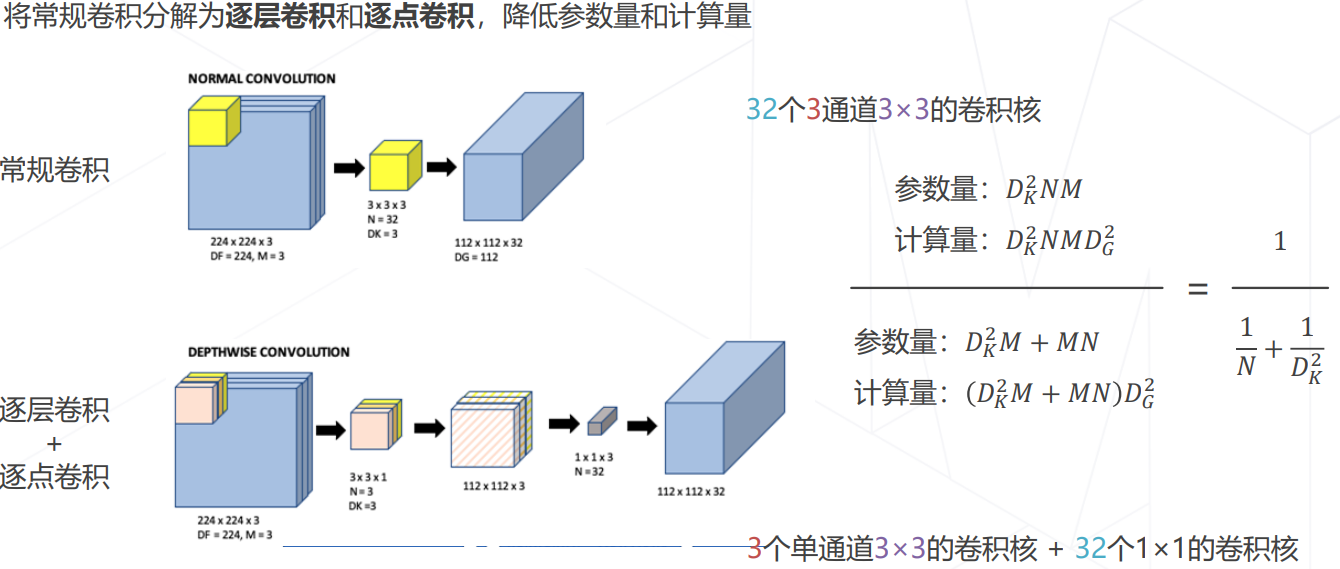

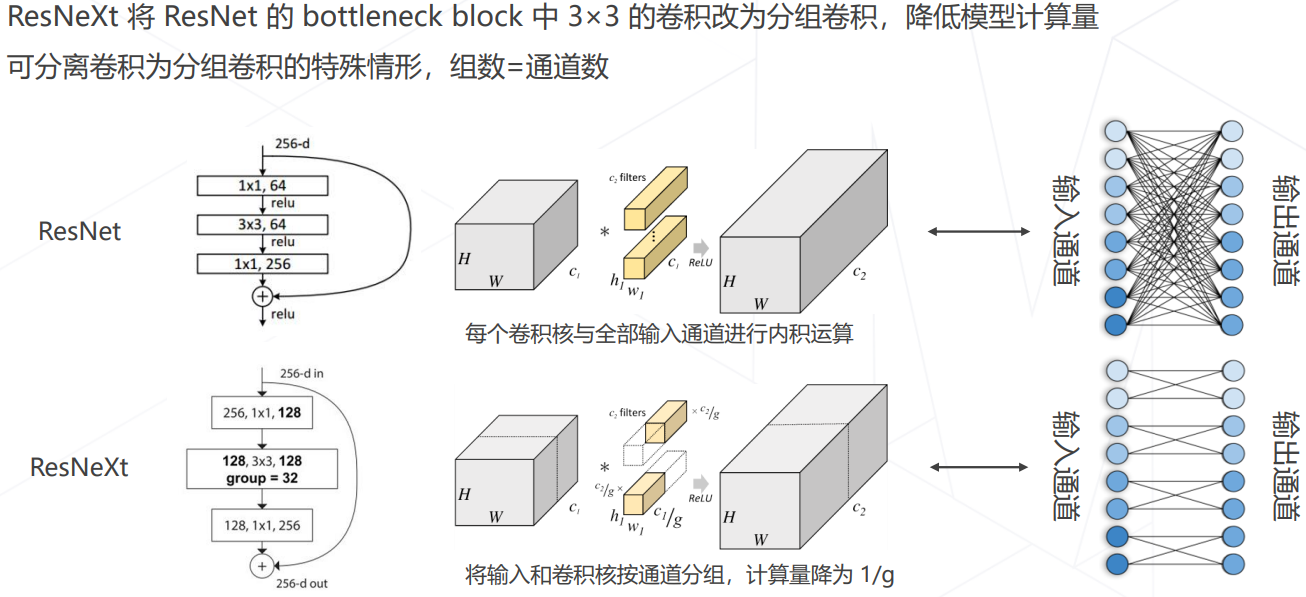
分组卷积:ResNeXt
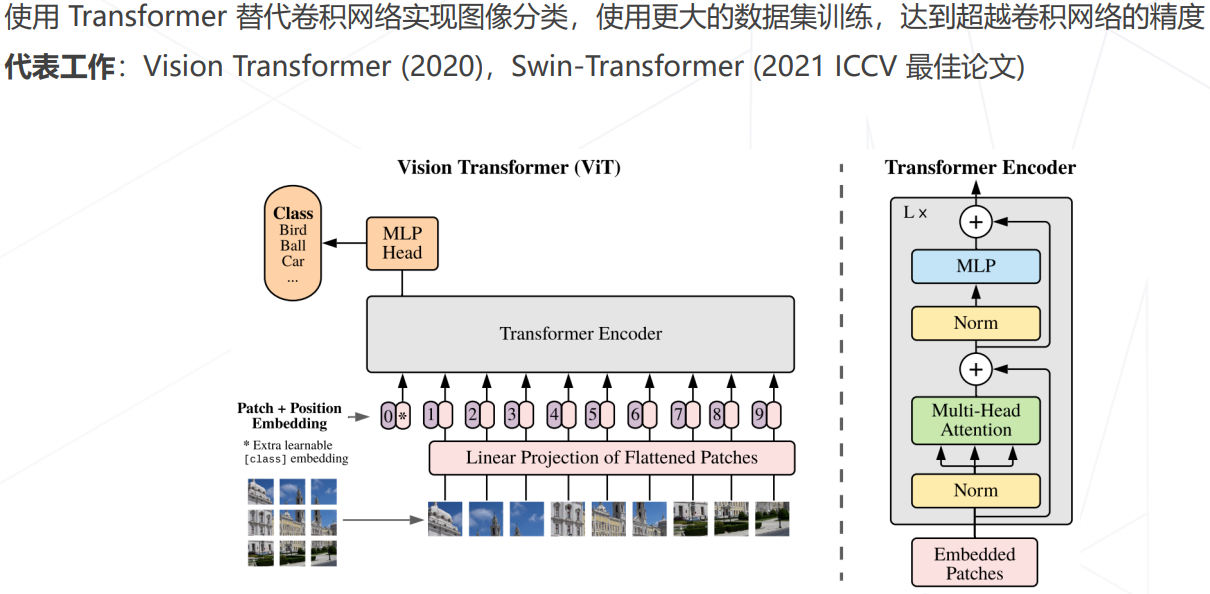
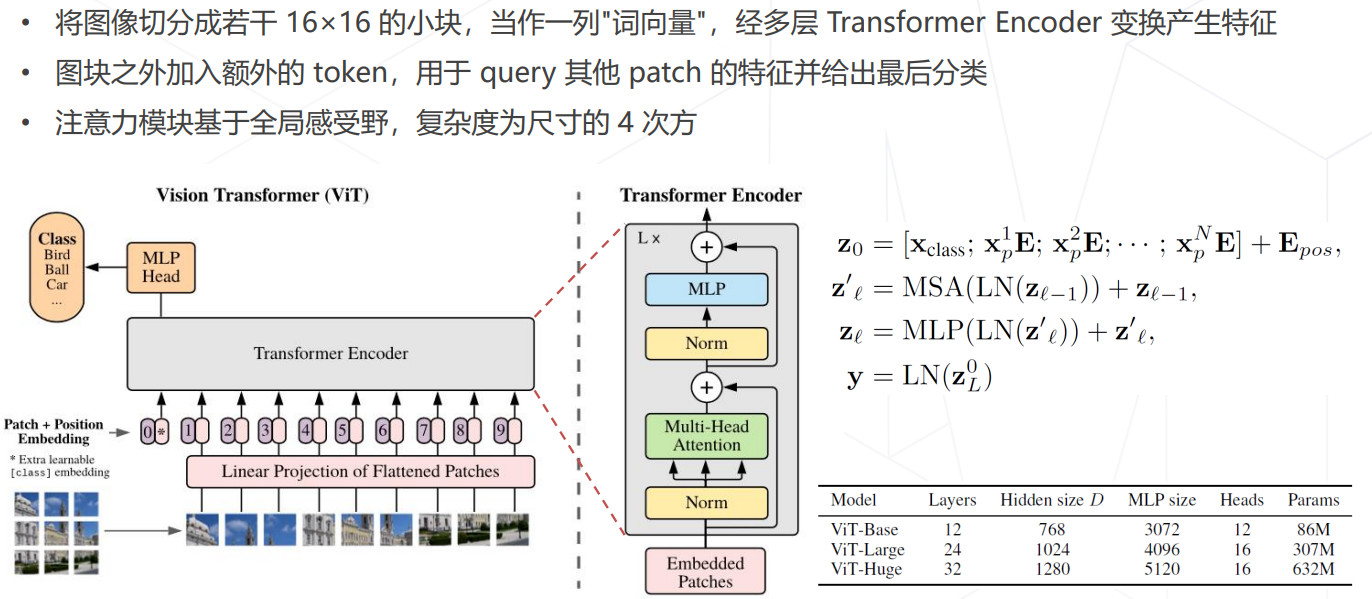
新方向:Vision Transformer (2020+)
原始的 1D 数据上的注意力机制 Attention Mechanism:

迁移到图像上后:

- 之前的卷积,特征提取的方式与输入无关,固化在卷积核参数中,以固定的方式去提取特征。但注意力机制不一样,提取特征的方式与输入有关。

- 多头注意力 Multi-head (Self-)Attention

ViT (2020)
- Vision Transformer (2020):计算复杂度过高是导致其无法应用的主要缺陷
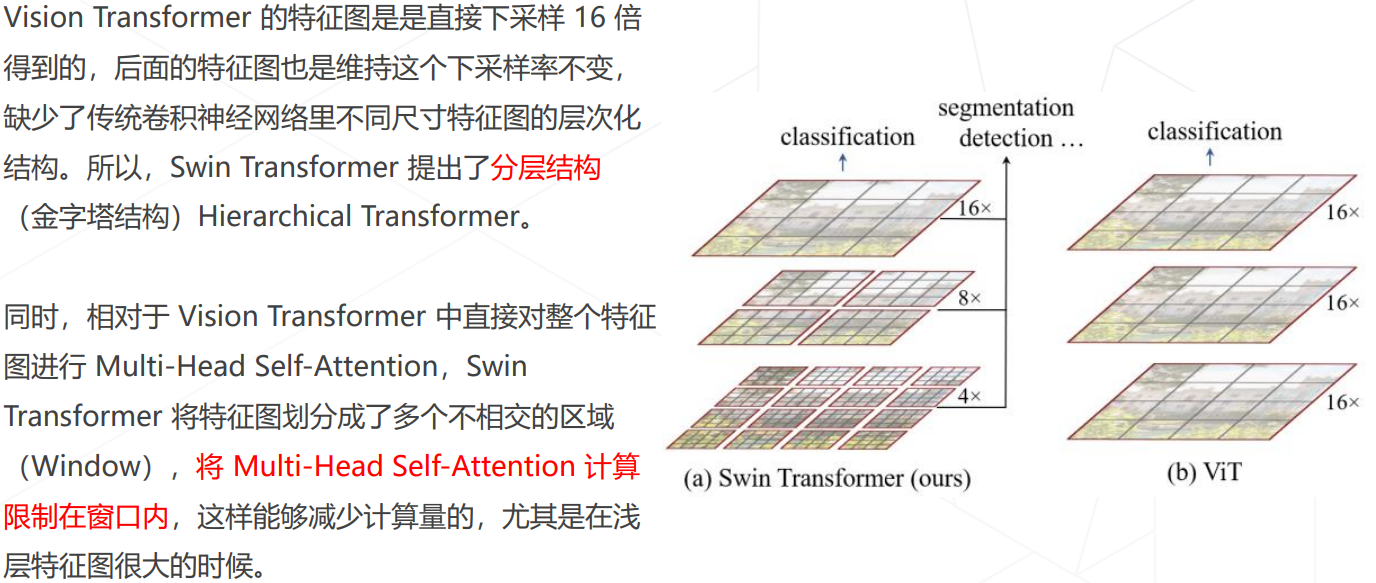
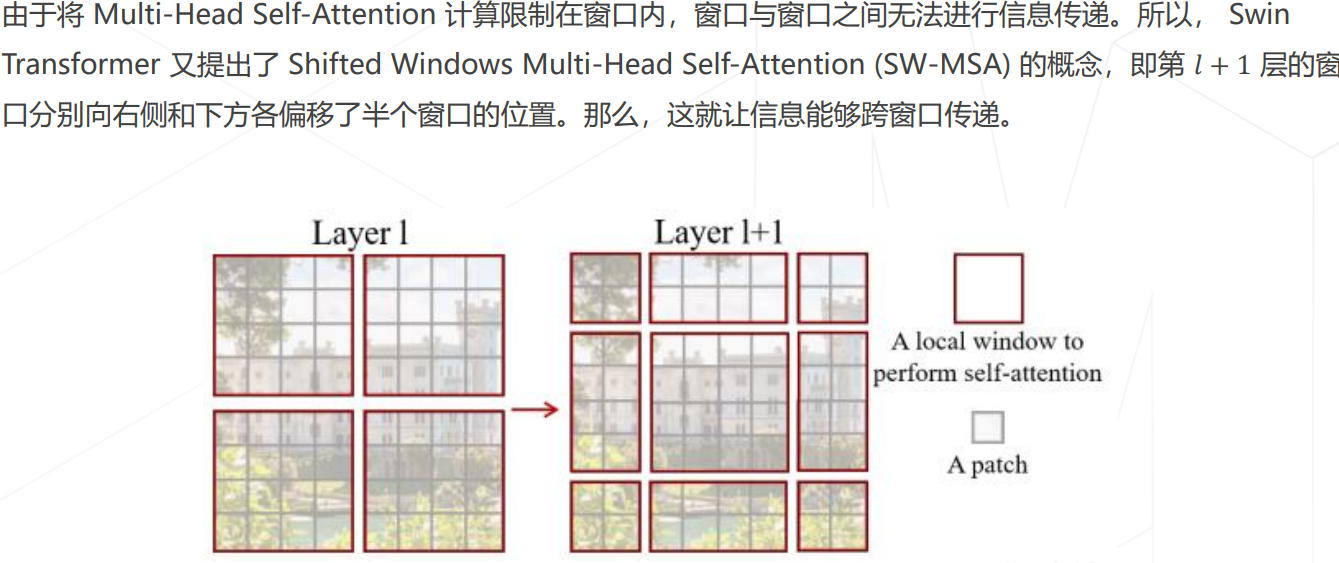
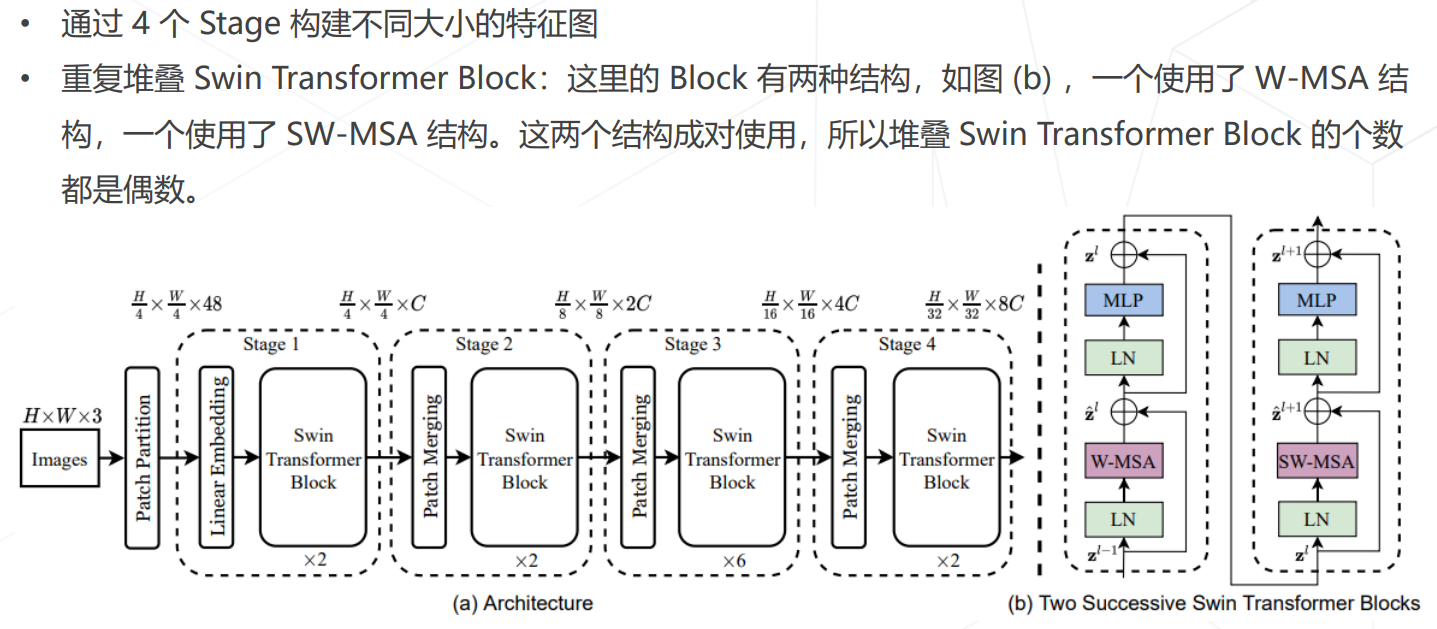
Swin Transformer (ICCV 2021 best paper)
模型学习
这里略去基础知识,只保留与CV相关的部分。

学习率与优化器策略
权重初始化

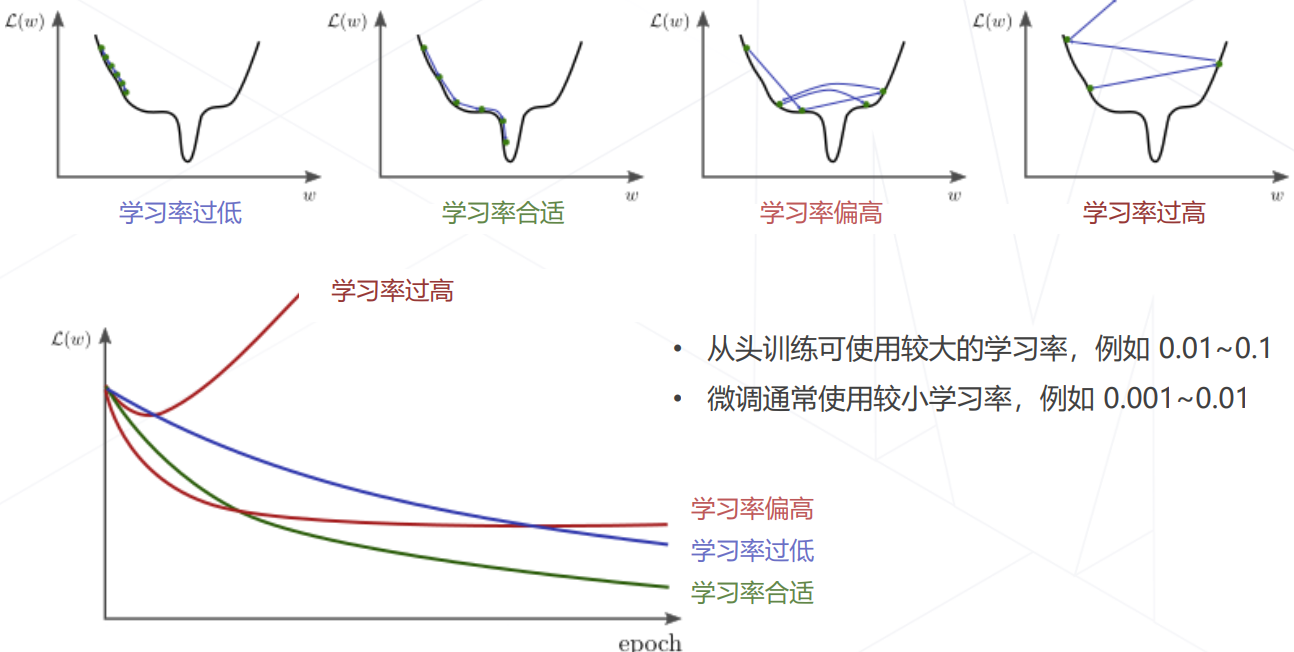
学习率
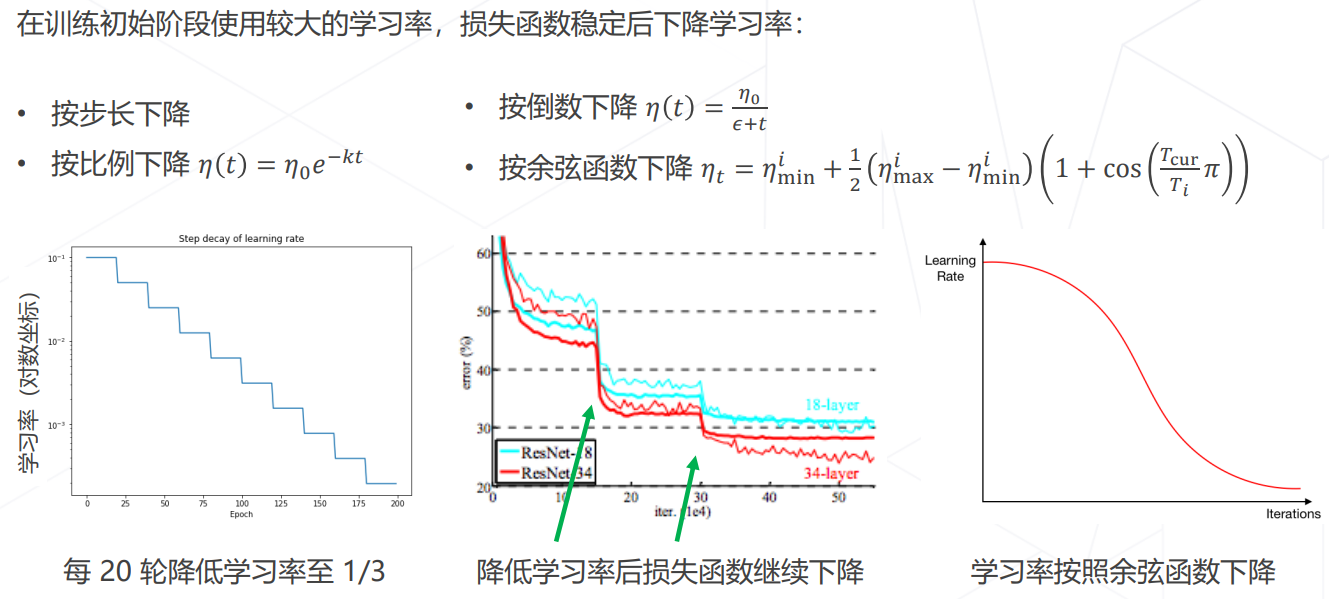
学习率退火 Annealing
学习率升温 Warmup
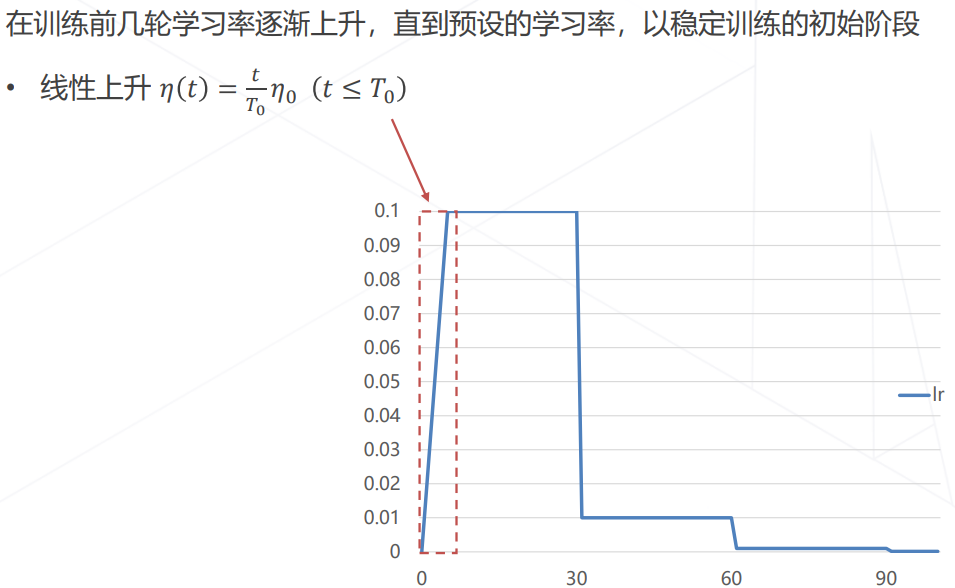
线性扩展原则 Linear Scaling Rule

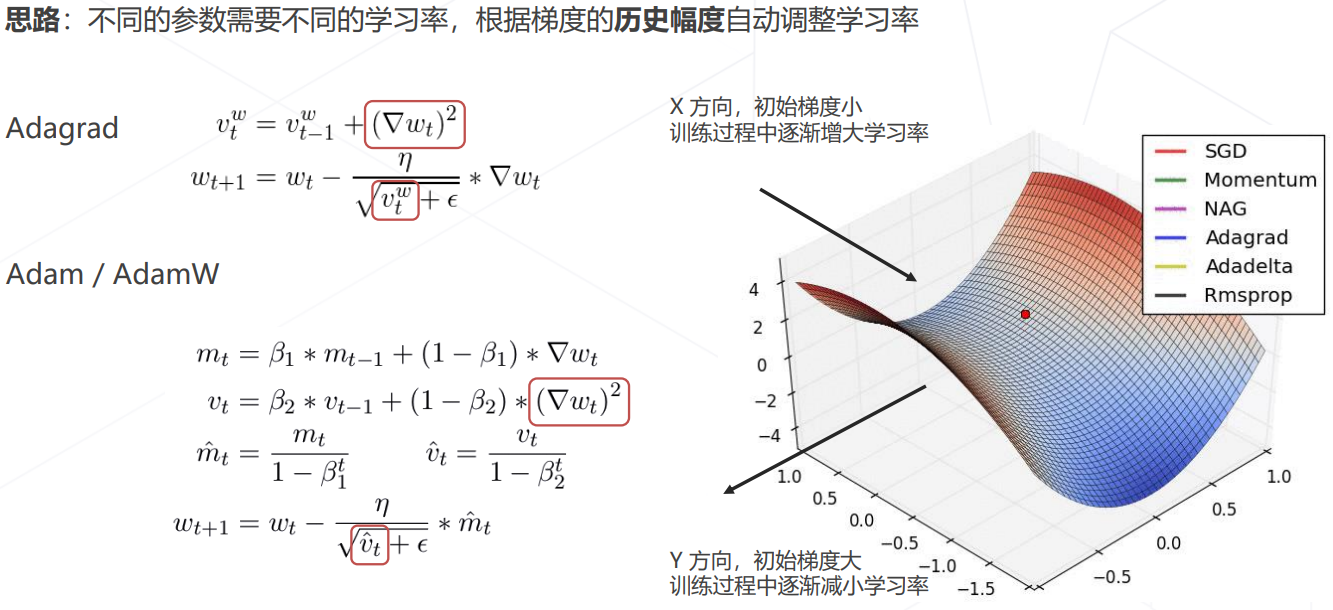
自适应梯度算法
正则化与权重衰减 Weight Decay

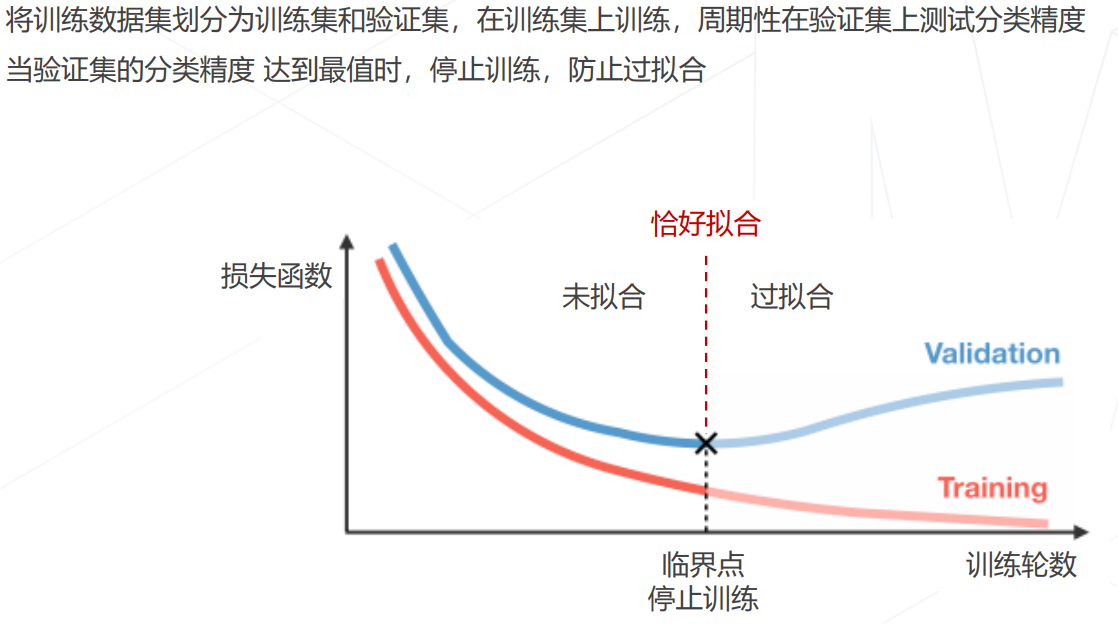
早停 Early Stopping
模型权重平均 EMA
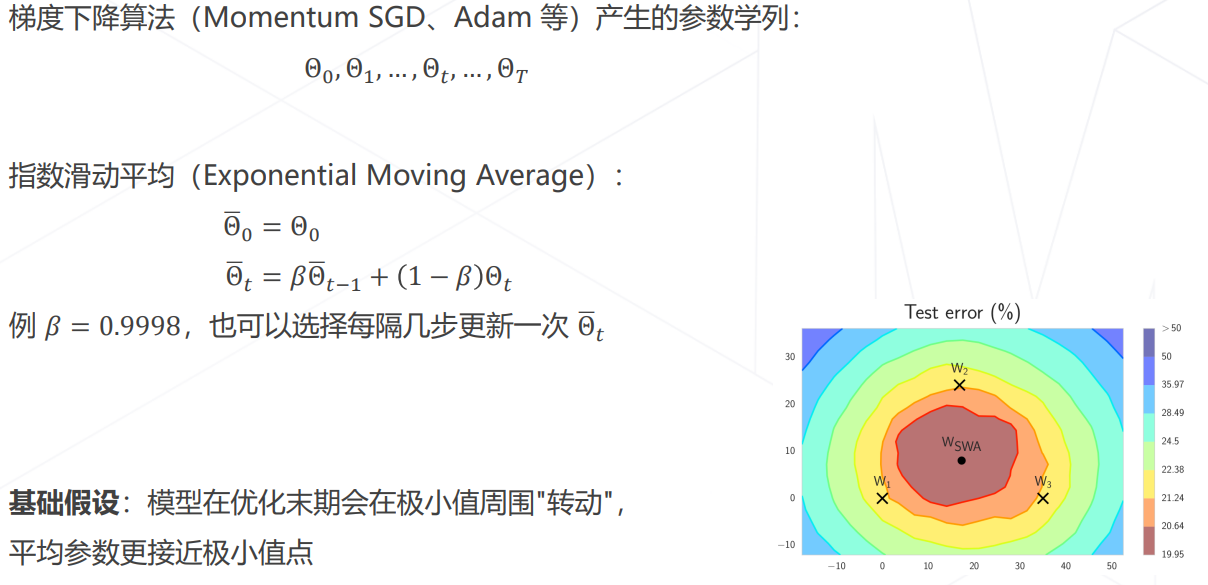
- Stochastic Weight Averaging:

数据增强

- 组合数据增强 AutoAugment & RandAugment

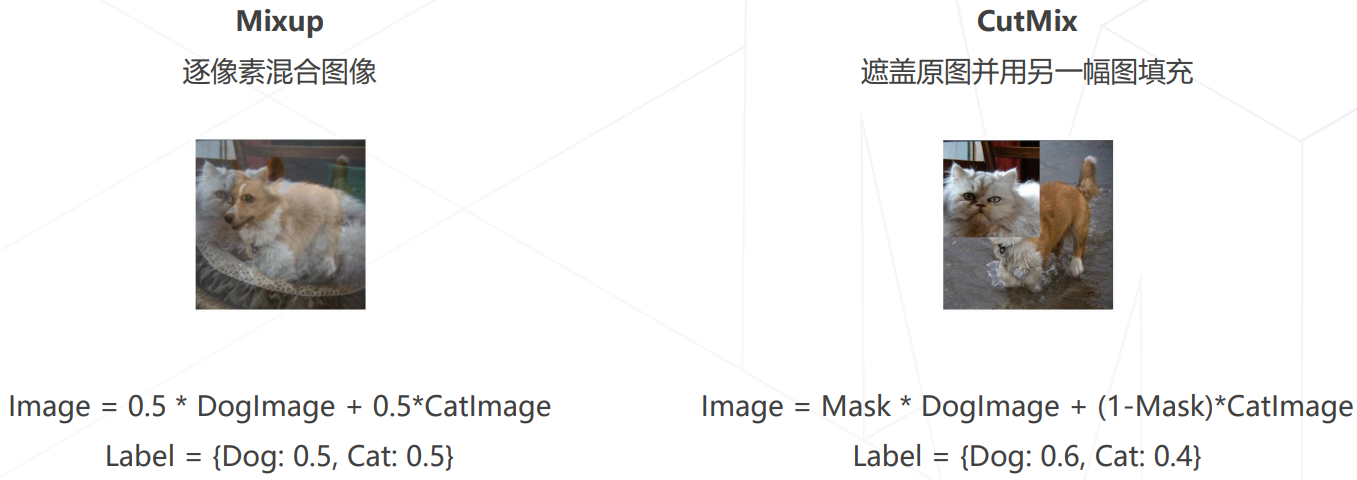
- 组合图像 Mixup & CutMix
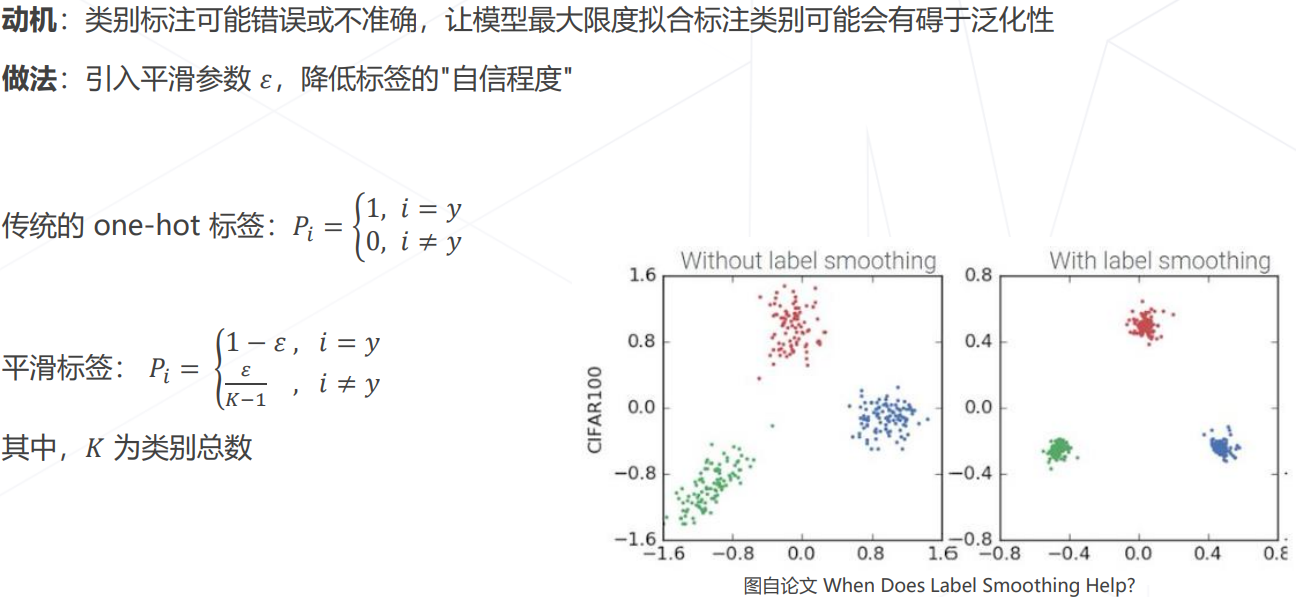
- 标签平滑 Label Smoothing:
模型相关策略
丢弃层 Dropout

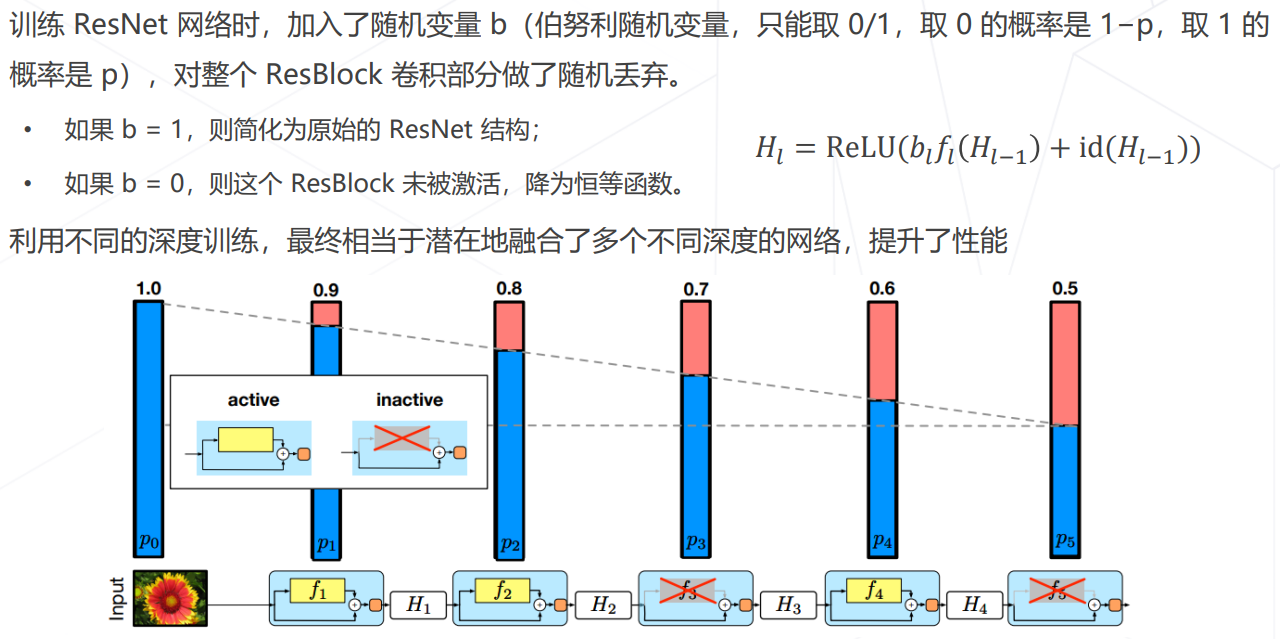
随机深度 Stochastic Depth
自监督学习

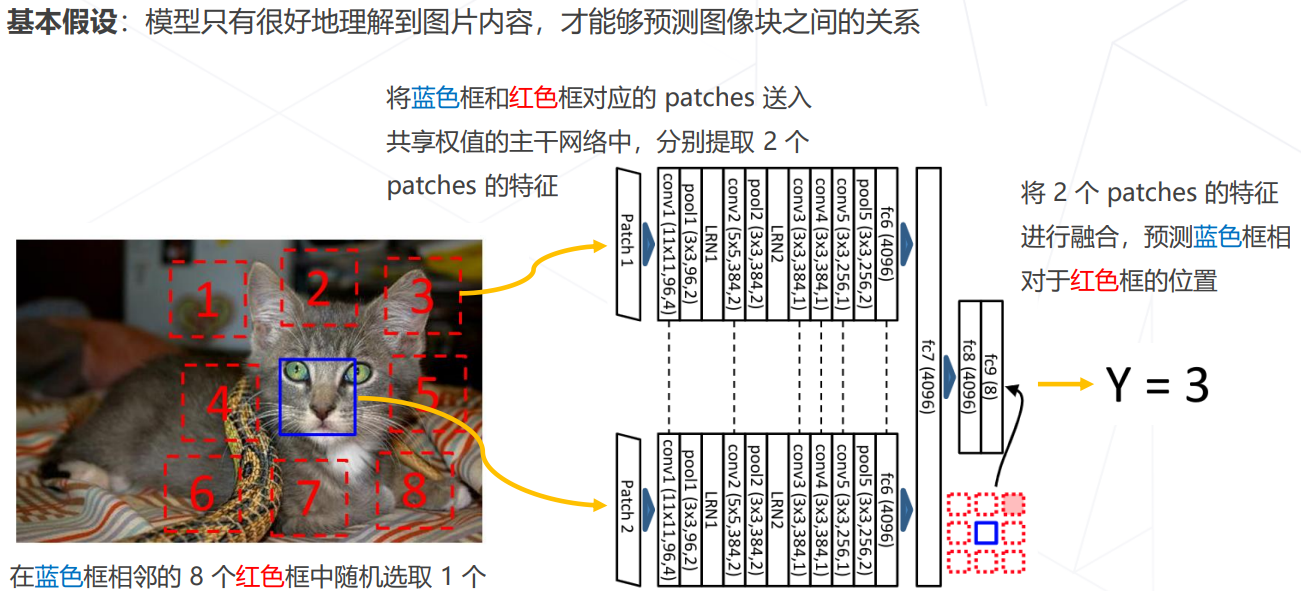
Relative Location (ICCV 2015)
SimCLR (ICML 2020)

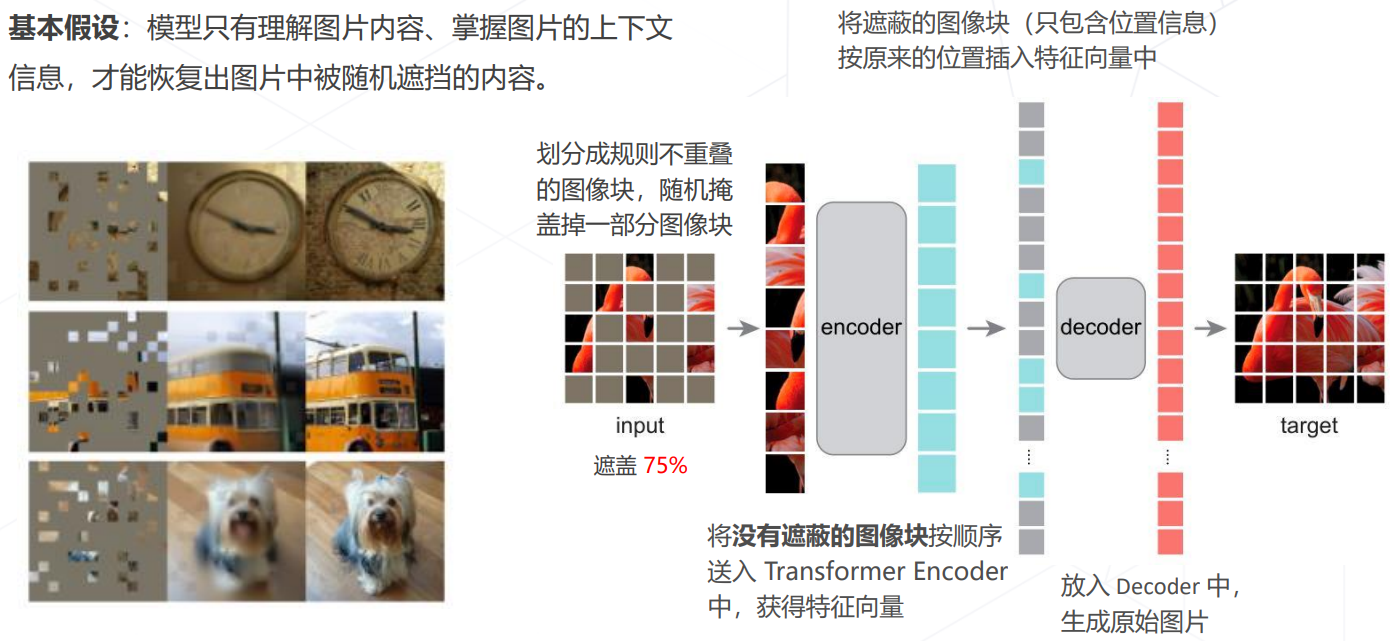
Masked autoencoders (MAE, CVPR 2022)
MMClassification 介绍

后面笔记的具体内容放到 day3 的代码实现部分更好一点,因此笔记到这里就结束啦。