作者:极市平台公众号
编辑:3D视觉开发者社区
极市导读
可视化对于Transformer的模型调试、验证等过程都非常重要,FAIR的研究者开源了一种Transformer可视化新方法,能针对不同类呈现不同且准确的效果。
加入极市CV技术交流群,走在计算机视觉的最前沿
近两年,“Transformer”的热潮从自然语言处理领域席卷至计算机视觉领域。Transformer及其衍生方法不仅是几乎所有NLP基准测试中最先进的方法,还成为了传统计算机视觉任务中的领先工具。在结果公布不久的CVPR2021中,与Transformer相关的工作数量也十分可观。

来自FAIR和以色列特拉维夫大学的学者在CVPR2021中发表了一篇名为“Transformer Interpretability Beyond Attention Visualization”的论文。在这篇论文中,作者提出了一种计算Transformer网络结构相关性的新颖方法,首次实现Transformer的可视化能针对不同类呈现不同且准确的效果。
该方法基于深度泰勒分解原理分配局部相关性,而后将相关性传播到各层。与以往方法相比不同的是,它的传播涉及注意层和残差连接。与此同时,作者在最新的视觉Transformer网络以及文本分类任务上进行了基准测试,证明了该方法相对于现有可解释性方法的明显优势。
目前,作者已经公布了该工作的开源代码:
代码地址:https://github.com/hila-chefer/Transformer-Explainability
论文链接:https://arxiv.org/abs/2012.09838
论文简介
可视化对于Transformer的模型调试、验证等过程都非常重要,而目前现有工作对于Transformer可视化的探索并不是很多。
过去可视化Transformer模型常见的做法是,针对单个注意力层,将注意力视为相关性得分;另一种则是组合多个注意力层,简单地平均获得每个标记的注意力。但由于更深的层更具有语义,而每次应用自注意力时,每个标记都会积累额外的上下文,这会导致信号模糊,各层的不同作用被忽视,并使得不相关的标记被凸显。
Transformer严重依赖于残差连接和注意力运算符,这两者都涉及两个激活图的混合。此外,Transformer使用ReLU以外的其他非线性因素,这会同时带来正向和负向的特征。由于存在非正值,如若处理不当,则残差连接会导致数值的不稳定。
针对上述问题,本文作者引入适用于正面和负面归因的相对传播规则,并提出了针对非参数层的归一化项,如矩阵乘法。同时,整合注意力与相关性得分,并将结果整合到多个注意力模块中。
在实践中,计算机视觉使用的许多可解释性方法并不是特定于类的,即无论尝试可视化的类是什么,即便对于包含多个对象的图像,也会返回相同的可视化效果。因而特定于类的信号通常会因为图像的显著区域而变得模糊。本文的方法则设计提供了基于类的分离,这也是目前唯一能够呈现此属性的Transformer可视化方法。
方法介绍
本文采用基于LRP[1]的相关性来计算Transformer每一层中每个注意力层的得分,通过合并相关性和梯度信息,通过迭代消除负面影响,然后将它们整合到注意力图中,得到自注意力模型特定于类的可视化。
相关性和梯度
令为分类头的类数, t ∈ 1... ∣ C ∣ t \in 1...|C| t∈1...∣C∣为要可视化的类,并传播关于的相关性和梯度。将 x ( n ) x^{(n)} x(n)表示为层 L ( n ) L^{(n)} L(n)的输入,其中 n ∈ [ 1... N ] n \in [1...N] n∈[1...N]是由层组成网络中的层索引, x ( N ) x^{(N)} x(N)是输入, x ( 1 ) x^{(1)} x(1)是输出。通过链式规则,将梯度传播到分类器的输出y:
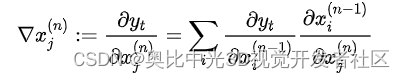
用 L i n ( X , Y ) L_i^{n}{(X,Y)} Lin(X,Y)表示该层在两个张量X和Y上的操作。通常,这两个张量是输入特征图和第n层的权重。相关性传播遵循通用的深度泰勒分解公式:
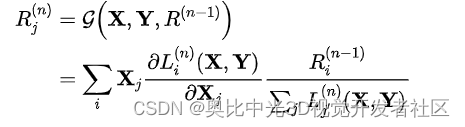
非参数相关传播
Transformer模型中有两个运算符涉及两个特征图张量的混合(与具有学习张量的特征图相反):残差连接和矩阵乘法。这两个运算符需要通过两个输入张量传播相关性。给定两个张量u和v,我们计算这些二进制运算符的相关性传播如下:
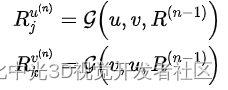
证明得到:
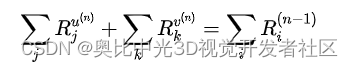
相关性和梯度扩散
令M为一个由模块组成的Transformer模型,其中每一个模块由自注意力,残差连接以及附加的线性层和归一化层组成。该模型将维数为,长度为的标记序列作为输入,为类别输出作特殊标记,输出由分类标记向量计算出的长度为的分类概率向量。自注意模块在输入维度为的小空间上运行,为head数量。自注意模块的定义如下:
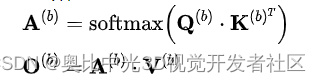
实验与结果
对于语言分类任务,作者使用基于BERT的模型作为分类器,假设最多512个标记,并使用分类标记作为分类头的输入。对于视觉分类任务,作者采用基于ViT的预训练模型。输入图像尺寸为的所有不重叠色块的序列,线性化图层以生成向量序列。
下图给出了本文的方法与各种基线方法之间的直观比较。可以看出,本文方法获得了更加清晰一致的可视化。
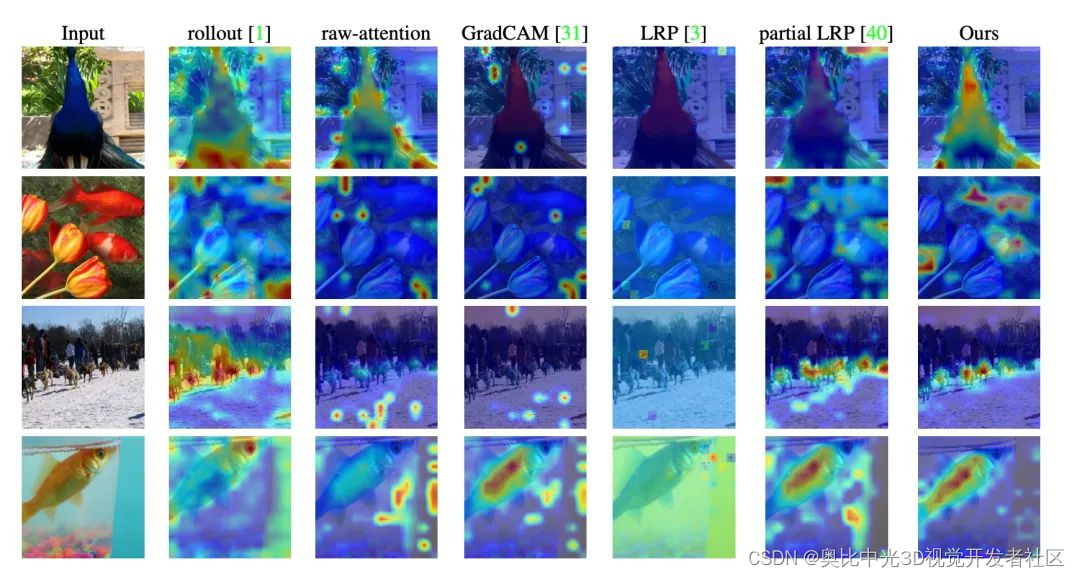
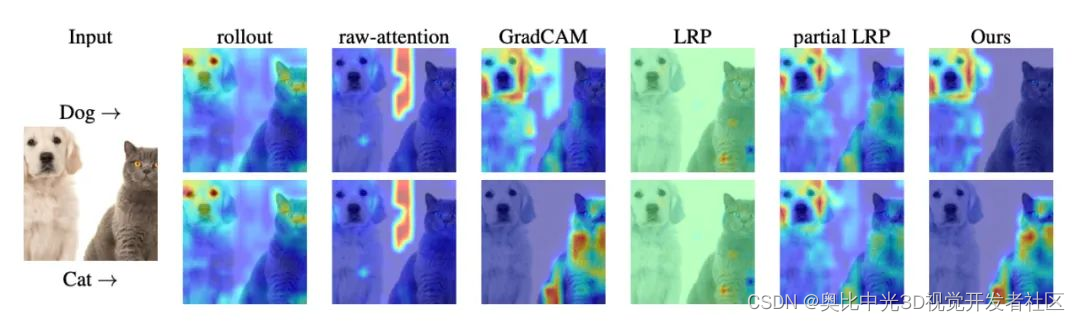
下图显示了带有两个对象的图像,每个对象来自不同的类。可以看出,除GradCAM之外,所有方法对不同类都产生了相似的可视化效果,而本文方法则取得了两个不同且准确的可视化效果,因而证明该方法是特定于类的。

下表为在ImageNet验证集上,预测类别和目标类别的正负扰动AUC结果。

ImageNet分割数据集上的分割性能:

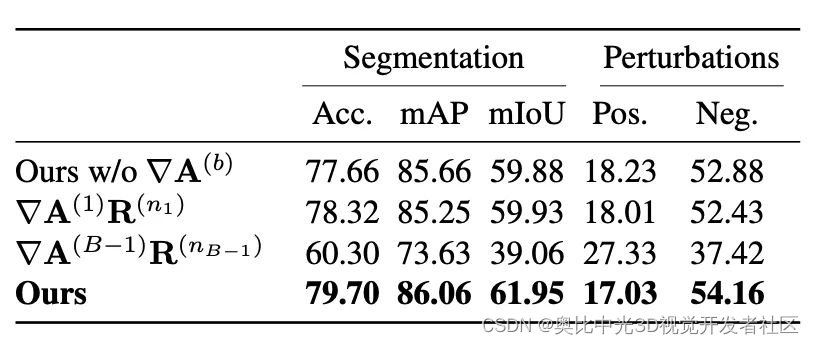
本文方法不同消融方案性能:
参考文献:
[1] Alexander Binder, Gre ́goire Montavon, Sebastian La- puschkin, Klaus-Robert Mu ̈ller, and Wojciech Samek. Layer-wise relevance propagation for neural networks with local renormalization layers. In International Conference on Artificial Neural Networks, pages 63–71. Springer, 2016. 1, 7, 8
版权声明:本文为奥比中光3D视觉开发者社区特约作者授权原创发布,未经授权不得转载,本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。
加入【3D视觉开发者社区】学习行业前沿知识,赋能开发者技能提升!
加入【3D视觉AI开放平台】体验AI算法能力,助力开发者视觉算法落地!
往期推荐:
1、 速来!2023第三届3D视觉创新应用竞赛决赛即将开启!
2、开发者社区「运营官」招募启动啦!_奥比中光3D视觉开发者社区的博客-CSDN博客
3、为什么你的手机后置摄像头越来越丑?ECCV2022这篇论文告诉你_奥比中光3D视觉开发者社区的博客-CSDN博客