作为当下最先进的深度学习架构之一,Transformer被广泛应用于自然语言处理领域,它不但替代了以前流行的循环神经网络RNN和长短期记忆网络LSTM,并且以它为基础衍生出了诸如BERT、GPT-3、T5等著名架构,下面对它的原理进行讲解
Transformer简介
循环神经网络和长短期记忆网络已经广泛应用于时序任务,比如文本预测,机器翻译,文章生成等等,然而它们面临的一大问题就是如何记录长期依赖
为了解决这个问题,一个名为Transformer的新架构应运而生,从那以后,Transformer被应用到多个自然语言处理方向,到目前位置还未有新的架构能够将其替代,可以说它的出现是自然语言处理领域的突破,并为新的革命性架构打下了理论基础
Transformer完全依赖于注意力机制,并摒弃了循环,它使用的是一种特殊的注意力机制,称为自注意力
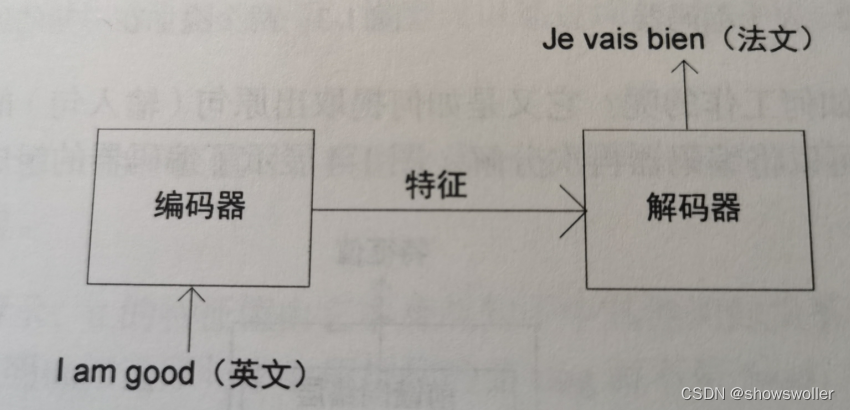
让我们通过一个文本翻译实例来了解Transformer是如何工作的,Transformer由编码器和解码器两部分组成,首先向编码器输入一句话,让其学习这句话的特征(特征可以有多种表示形式,它既可以为单一数值,也可以为向量或者矩阵)再将特征作为输入传输给解码器,最后此特出会通过解码器生成输出句子
假设我们需要将一个句子从英文翻译为法文,如下图所示,首先我们需要将这个英文句子输入进去编码器,编码器将提取英文句子的特征并提供给解码器,最后解码器通过特征完成法文句子的翻译
创作不易 觉得有帮助请点赞关注收藏~~~