一、ChatGPT发展
【ChatGPT——GPT3.5】
诞生于:2022 年 11 月
类型:对话场景的大语言模型
特点:更贴近人的方式与使用者互动;在理解人类意图、精准回答问题、流畅生成结果方面远超人类预期。
功能:可以回答问题、承认错误、挑战不正确的前提、拒绝不适当的请求,同时拥有惊艳的思维链推理能力和零样本下处理问题能力。
热度:据瑞银数 据,ChatGPT 产品推出 2 个月后用户数量即过亿,而上一个现象级应用 TikTok 达到 1 亿用户花费了 9 个月时间。
能力:强大的上下文连续话能力 :ChatGPT 可以实现几十轮连续对话,能够比较准确地识别省略、指代等细粒度语言现象、记录历史信息,而且似乎都可以保持对话主题的一致性和专注度。
智能的交互修正能力:无论是用户更改自己之前的说法还是指出ChatGPT的回复中存在的问题,都能够捕捉到修改意图,并准确识别出需要修改的部分,最后做出正确的修改。
【ChatGPT——GPT4.0】
诞生于:2023年 3 月
类型:对话场景的大语言模型
特点:具备多模态能力,可以同时支持文本和图像输入。
支持的文本输入数量提升至约 32000 个 tokens,对应约 2.5 万单词。
性能:
- 理解/推理/多语言能力增强。
- 理解能力显著增强,可以实现“看图说话”。
- 可靠性相比 GPT3.5 大幅提升 19%。
- 对不允许和敏感内容的错误反应显著下降。
二、ChatGPT技术基础
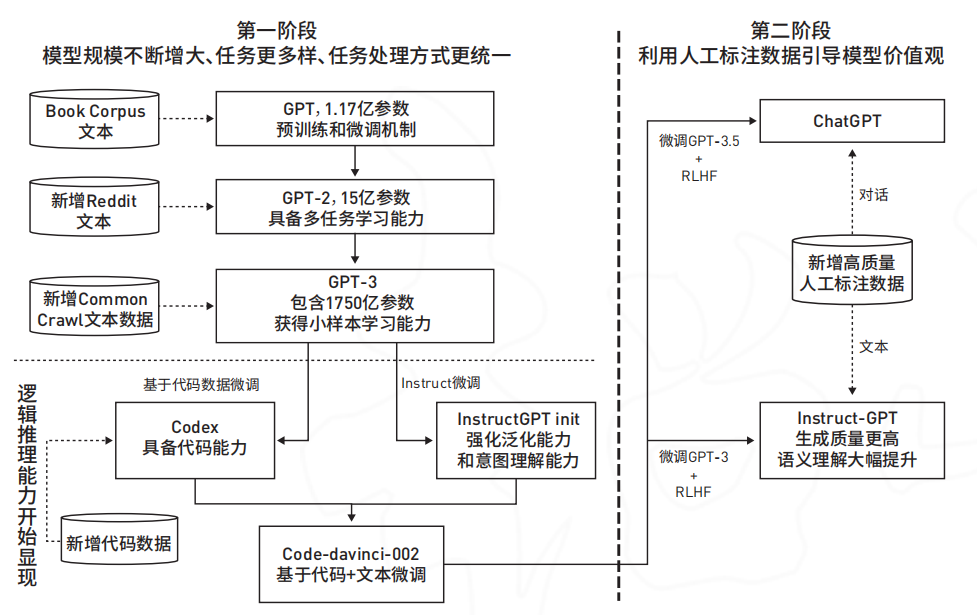
ChatGPT由生成式预训练模型(Generative Pretrained Transformer,GPT)GPT-3.5 微调而来,在GPT-3.5的基础上,引入了基于人类反馈的强化学习技术(Reinforcement Learning from Human Feedback,RLHF)对模型进行微调。
参考:ChatGPT 为代表的大模型对信息资源管理的影响
ChatGPT 的能力来源于:大规模预训练 + 指令微调 + 基于人类反馈的强化学习
1、通过大规模的预训练,通过让拥有 1750 亿参数的大模型去学习包含 3000 亿单词的语料,大模型已经具备了基础能力。
大模型基础能力:语言生成、情景学习(in-context learning,遵循给定的示例为新的测试应用生成解决方案)、世界知识(事实性知识和常识)、指令遵循(Instruct following)、思维链(Chain of thought)可逐步解决问题。
2、通过指令微调(Instruction tuning),帮助大模型“解锁”特定领域的能力如遵循指令来实现问答式的聊天机器人,或泛化到其他新的任务领域。
3、基于人类反馈的强化学习(RLHF,Reinforcement Learning with Human Feedback)则让大模型具备了和人类“对齐”的能力,即给予提问者详实、公正的回应,拒绝不当的问题,拒绝其知识范围外的问题等特性。
2.1 大规模的预训练
ChatGPT基于Transformer进行特征提取,采用Decoder-Only方式,由两阶段到一阶段:单向语言模型预训练+zero shot/ few shot prompt/ Instruct。
解释一下GPT的含义:生成式预训练(Generative Pre-Train,GPT)。
- Decoder-Only(仅解码器)——GPT
- Encoder-Only(仅编码器)——谷歌的Bert、Deberta
- Encoder-Decoder(编码器-解码器)——Meta的Bart、T5、ChatGLM
采用 Decoder-Only 的有 GPT 等,其采用“预测下一个单词”的 方式进行预训练,之后通过指令微调等实现特定领域功能的激发。
采用 Encoder-Only 的有谷歌的 Bert、微软的 Deberta 等,其采用 “完形填空”式的预训练,再根据所需的应用领域用少量标注过的数据进行 Fine-tuning(微调)。
采用Encoder-Decoder 架构的模型如谷歌的 T5、Meta 的 Bart、清华大学的 ChatGLM 等。
大模型预训练:
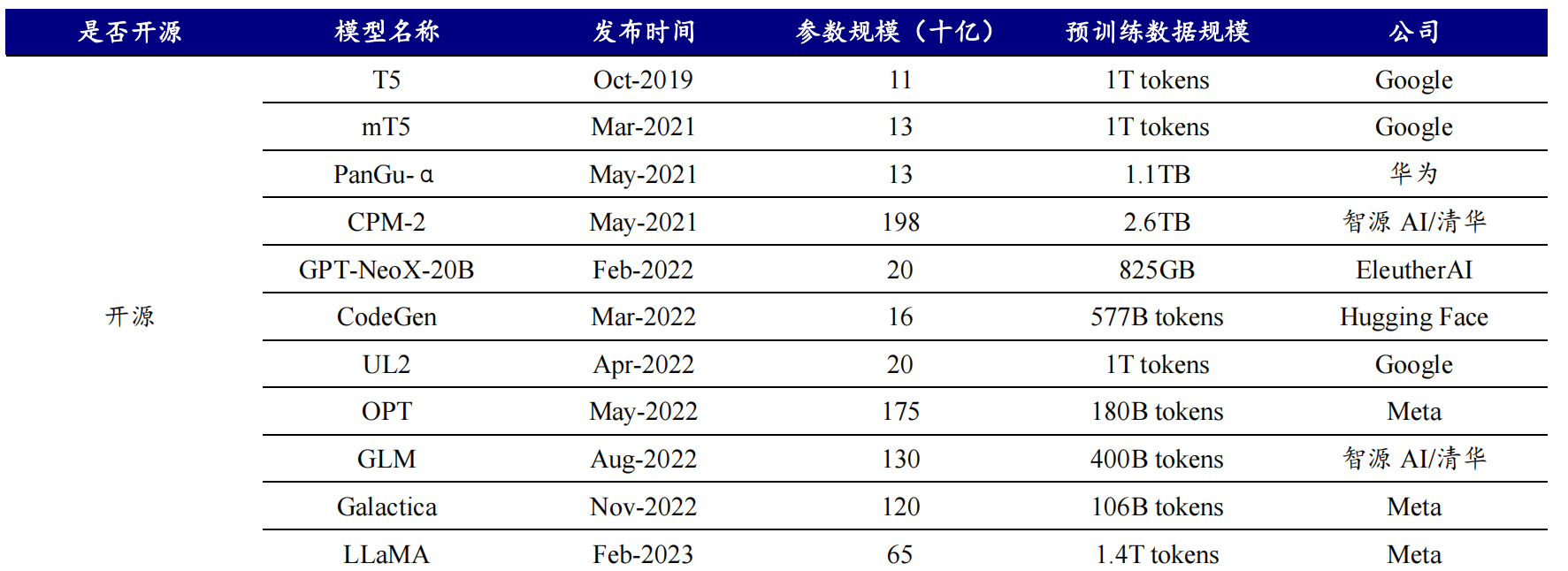

参考:《A Survey of Large Language Models》(Zhao Wayne Xin 等)、开源证券研究所
2.2 模型微调
模型微调将赋予模型在特定领域的能力,预训练好的基础模型进行微调:
- 1、采用人工标注好的数据来训练模型;
- 2、通过人类对模型答案的排序训练一个奖励模型;
- 3、使用奖励模型通过强化学习的方式训练 ChatGPT。其中后两个步骤称为 RLHF(基于人类反馈的强化学习)。
在 GPT4 的训练过程中,OpenAI还进一步加入了基于规则的奖励模型(RBRMs)来帮助模型进一步生成正确的回答,
拒绝有害内容。可以看出模型微调对模型最终的效果实现至关重要,玩家独特的训练和微调方法会让自己的模型形成独特的性能。
2.3 基于人类反馈的强化学习
三、ChatGPT对科研思路的影响
1、资源富集的实验室会开始进一步投入大模型竞争,短期内将会以探索 RLHF 的不同方向和规模为主。
2、部分子任务的快速消失和被整合。大量之前存在的子任务/小任务会并入大任务,构造有监督数据集并微调不再是小任务的第一选择。大模型无法取得好结果的小任务将成为研究热点。
3、跨模态知识的挖掘和自监督学习将成为新的热点研究方向。大量基于RLHF的跨模态知识的生成方法将被快速提出并实践,相关成果将在短期内大量发表。主流热点将主要聚焦在知识的数量、质量以及运用知识的方法。
参考文献:
[1] 赵朝阳,朱贵波,王金桥.ChatGPT给语言大模型带来的启示和多模态大模型新的发展思路[J].中国科学院自动化研究所.2023
[2] 《A Survey of Large Language Models》(Zhao Wayne Xin 等)
[3] ChatGPT 为代表的大模型对信息资源管理的影响
本文只供大家参考与学习,谢谢~