AIGC:ColossalChat(基于LLM和RLHF技术的类似ChatGPT的聊天机器人)的简介、安装、使用方法之详细攻略
目录
ColossalChat的简介
ColossalChat于2023年3月28日发布(目前GitHub已获得29.2k个star,仍在持续更新),它是一个使用LLM和RLHF技术实现的聊天机器人项目,由Colossal-AI项目提供支持。Coati代表ColossalAI Talking Intelligence,是实现该项目的模块的名称,也是由ColossalChat项目开发的大型语言模型的名称。
ColossalChat是一款基于人工智能技术的聊天机器人,它可以与用户进行自然语言交互。Coati软件包提供了一个统一的大型语言模型框架,实现了以下功能:
>>支持ColossalAI的全面大型模型训练加速能力,无需了解复杂的分布式训练算法;
>> 监督式数据集收集;
>> 监督指令微调;
>> 训练奖励模型;
>> 带人类反馈的强化学习;
>> 量化推理;
>> 快速模型部署;
>> 与Hugging Face生态系统完美集成,具有高度的模型定制性;

由于Colossal-AI正在进行一些重大更新,因此该项目将得到积极维护,以与Colossal-AI项目保持一致。
[2023/03] ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline
[2023/02] Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory
GitHub官网:ColossalAI/applications/Chat at main · hpcaitech/ColossalAI · GitHub
1、局限性
LLaMA-finetuned 模型的限制
Alpaca 和 ColossalChat 都基于 LLaMA,因此很难弥补预训练阶段中缺失的知识。
缺乏计数能力:不能计算列表中的项目数量。
缺乏逻辑推理和计算能力。
倾向于重复最后一句话(无法生成结束标记)。
多语言结果较差:LLaMA 主要是在英语数据集上训练的(生成优于问答)。
数据集的限制
缺乏摘要能力:在 fine-tune 数据集中没有这样的指令。
缺乏多轮对话:在 fine-tune 数据集中没有这样的指令。
缺乏自我认知能力:在 fine-tune 数据集中没有这样的指令。
缺乏安全性:
当输入包含虚假事实时,模型会捏造错误的事实和解释。
2、在线演示

在此页面上体验Coati7B的性能。由于资源限制,我们将只在2023年3月29日至2023年4月5日期间提供此服务。但是,我们已经在推理文件夹中提供了推理代码。web也将很快开放源代码。
警告:由于模型和数据集大小的限制,Coati只是一个婴儿模型,Coati7B可能会输出不正确的信息,缺乏多回合对话的能力。还有很大的改进空间。
3、Coati7B examples
Generation
E-mail
coding
regex
Tex
writing
Table
Open QA
Game
Travel
Physical
Chemical
Economy
ColossalChat的安装
第一步,安装环境
conda create -n coati
conda activate coati
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI/applications/Chat
pip install .第二步,安装Transformers
由于Hugging Face尚未正式支持LLaMA模型,因此我们分叉了一个Transformers分支,使其与我们的代码兼容。
git clone https://github.com/hpcaitech/transformers
cd transformers
pip install .ColossalChat的使用方法
1、基础用法
监督式数据集收集
我们收集了10.4万条中英文双语数据集,并且您可以在这个InstructionWild存储库中找到这些数据集。以下是我们如何收集数据的过程:

RLHF训练阶段1 - 监督指令微调
阶段1是监督指令微调阶段,使用前面提到的数据集对模型进行微调。您可以运行examples/train_sft.sh来开始监督指令微调。
RLHF训练阶段2 - 训练奖励模型
阶段2训练奖励模型,通过手动对相同提示的不同输出进行排名,获取相应的分数,并监督奖励模型的训练。您可以运行examples/train_rm.sh来开始奖励模型的训练。
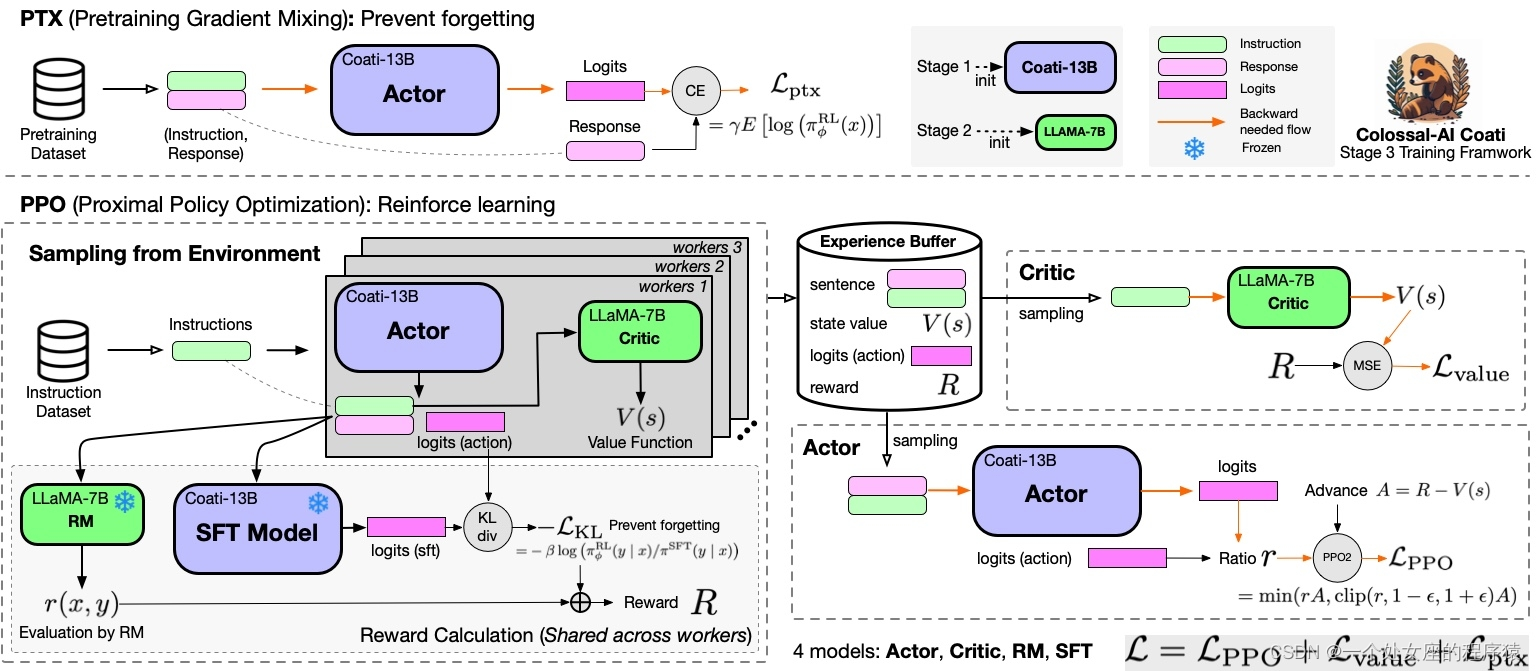
RLHF训练阶段3 - 使用人类反馈进行强化学习训练模型
阶段3使用强化学习算法,这是训练过程中最复杂的部分:您可以运行examples/train_prompts.sh来开始使用人类反馈进行PPO训练。有关更多详细信息,请参见examples/。
推理量化和服务 - 训练后
我们提供在线推理服务器和基准测试。我们的目标是在单个GPU上运行推理,因此使用大型模型时量化至关重要。
我们支持8位量化(RTN)、4位量化(GPTQ)和FP16推理。您可以使用在线推理服务器脚本来帮助部署自己的服务。
有关更多详细信息,请参见inference/。