基本概念
Motion Blur,动态模糊或者运动模糊的介绍可以参考一下这段, 摘抄自这里Motion Blur | Post Processing | 3.2.2
The Motion Blur effect blurs the image in the direction of the Camera’s movement. This simulates the blur effect a real-world camera creates when it moves with the lens aperture open, or when it captures an object moving faster than the camera’s exposure time.
首先需要了解一下相机曝光的概念,曝光时间取决于快门速度,在一段曝光时间内,相机的像素值是累积的。这里提到了动态模糊对应现实相机中的两种情况,一种是相机移动同时保持光圈打开(长时间曝光),第二种是物体移动速度过快超过快门速度,在本质上都是代表在曝光时间内成像发生了比较明显的变化,导致拍摄的结果模糊。不过这未必是坏事,因为人眼也以同样的方式运作,只需要30帧就可以得到流畅的结果,超过这个频率发生的变化同样也会表现为动态模糊。
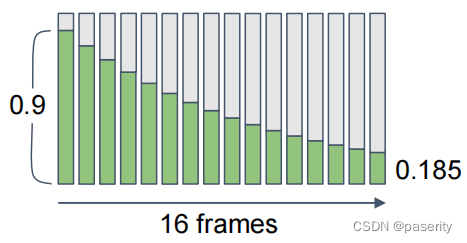
按照这个理论,下图展示了实际长曝光发生的情况。假设相机从右往左移动,顶部是世界空间物体标尺,下面每条横线展示了每个时刻相机显示的范围,假设曝光时间是t一共4秒,每秒移动一个单位长度。

理论上这4秒有无数个相机时刻,相机像素值需要积分的。但为了方便计算时我们只能使用离散积分处理这里t=0,1,2,3四个时刻,得到最终相机最左侧0点的数值:
同理CameraColor1~3也是一样,值等于当前像素和之前若干像素的平均。
这告诉我们要如何做动态模糊,需要将当前点和之前若干像素取平均值。这有个隐含参数是需要平均的像素点的个数N,这取决于曝光时间,时间越长,t越大需要平均的像素点越多。
动态模糊-历史缓存Blend
首先是比较简单的实现方式,从原理分析出发,那么可以保存这N帧的图像然后对相邻N帧取平均。但直接创建N个缓存贴图成本太高,可以只使用一个缓存用Blend代替:假设当前屏幕输出是x(t),当前屏幕经过动态模糊处理后的输出是S(t),那么Blend公式如下:
当a接近于0时,根据这里[1]的推导,最终结果趋向于所有帧的平均。a值越大,历史帧的权重下降得越快,在表现结果上就是残影消失越快。当a=0.1时,结果如下:

实际上指数混合权重下降是很快的,只有a接近0才会分布比较平均,其他时候都是快速下降,这实际上提供了调整N的方法,a越小,N就越大,像素就会和更多的历史帧求平均,模糊效果就越明显。
实现上比较简单,就是需要创建一个常驻的RenderTexture,每帧场景绘制结果后,将结果跟这个中间缓存做Blend,再每次将这个结果写回中间缓存。
贴一下SRP中的实现,需要特别注意的是最后要重新将RenderTarget重置。
if (!accumulationRT || accumulationRT.width != bufferSize.x || accumulationRT.height != bufferSize.y)
{
accumulationRT = new RenderTexture(bufferSize.x, bufferSize.y, 0, useHDR ? RenderTextureFormat.DefaultHDR : RenderTextureFormat.Default);
} else
{
buffer.GetTemporaryRT(
accumulateBlendResultId, bufferSize.x, bufferSize.y, 0, FilterMode.Bilinear, useHDR ? RenderTextureFormat.DefaultHDR : RenderTextureFormat.Default
);
buffer.SetGlobalFloat(accumulateBlendId, settings.motionBlurSettings.blend);
buffer.SetGlobalTexture(accumulateBlendHistoryId, accumulationRT);
Draw(intermediateResult, accumulateBlendResultId, Pass.AccumulatBlend);
Draw(accumulateBlendResultId, accumulationRT, Pass.Copy);
intermediateResult = accumulateBlendResultId;
}
// recover to old render target
buffer.SetRenderTarget(intermediateResult, RenderBufferLoadAction.DontCare, RenderBufferStoreAction.Store);动态模糊-速度映射
另外一种方法不需要使用中间缓存,而是作为一种后处理效果直接在屏幕空间实现,需要计算速度向量,根据重投影来计算像素速度。但因为我们现在没有中间缓存,那么如何找到历史帧对应的屏幕像素点就成了问题,解决方法是重投影。
重投影
重投影(Reprojection)依赖于重建世界空间坐标,具体可以参考我之前的文章Unity SRP世界空间重建_paserity的博客-CSDN博客,思路是:首先根据当前点的像素和深度逆向求出其世界空间位置,再根据前一帧的VP矩阵得到这个空间位置在上一帧渲染的像素位置,这样可以直接在当前渲染贴图内部做查找而不依赖缓存。
分析一下为什么这样可行,首先如果过程中VP矩阵没有变化(只有相机位移变化的情况),那么参考下图,其中P1是当前像素点,重投影得到上一帧的P3像素点。设P4是上一帧中的和P1具有相同的UV的点(对应相机的同一个像素点),并且可以由P2重投影得到。
我们想要的实际上是上一帧的P4渲染的像素,即这一帧中P2的像素,所以需要的速度值是P2-P1,而我们求得的是速度值是P4-P3,很显然这里有P1P2=P3P4。
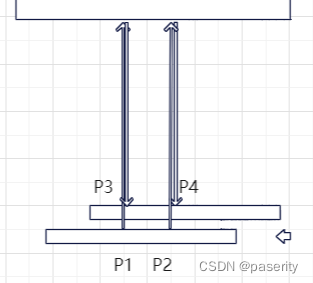
但还有VP矩阵发生变化的情况,按下图所示,假设物体不动,相机绕着物体旋转了a角,其中P1~P4含义和之前相同。
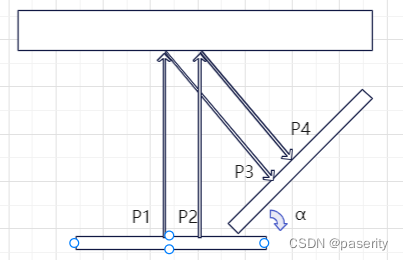
根据比例关系可以得到:
一般情况下a会很小,因为a代表相机在相邻两帧的旋转角度,这时退化成线性的情况。但是如果a较大,那求出来的速度会偏小很多,这种情况下用重投影会有可观的误差,一般加一个根据相机旋转速度配置的参数来模拟这个cos(a),因为精确计算成本也很高。
速度映射
根据前面的分析,重投影计算的速度向量可以让我们找到上一帧中的历史像素,理论上可以保存前N帧的VP矩阵依次计算对应的像素位置,但这个开销太大了,所以一般只存了前一帧的VP矩阵,并且假定后面N-1帧的像素速度是一样的。
需要注意的是,重投影不一定保证能找到对应像素,举个最简单的例子,相机旋转看到了物体的背面,但是之前的N帧都没有这个新位置的信息。通过上面的重投影方法也能得到一个像素位置,但是我们要的那个点没通过深度测试,现在记录的是正面的信息不是我们需要的,从而产生问题,这种走样称为Ghosting。
很容易想到可以将上一帧的深度缓存也记录下来,和逆向求出点的深度做比较,只有当逆向深度小于等于上一帧的深度缓存才做平均。但这又要引入新的深度缓存,成本太高了。目前一般使用Neighborhood Clamping来解决问题,后面有空再介绍。
这种方法实现的结果如下:

感觉这种实现的结果不如Blend方式的精细,变化不够光滑,不过也能看。
贴一下实现的代码:
VaryingsNew BlitPassVertex(Attributes input, uint vid : SV_VertexID)
{
VaryingsNew output;
// todo: use direct position result to replace
//output.positionCS = mul(UNITY_MATRIX_VP, mul(UNITY_MATRIX_M, float4(input.positionOS, 1.0)));
output.positionCS = TransformObjectToHClip(input.positionOS);
output.screenUV = input.baseUV;
output.camera2DepthVector = _CameraDepthPosVector[vid];
return output;
}
float4 VelocityMotionBlurFragment(VaryingsNew input) : SV_TARGET
{
float2 screenUV = input.screenUV;
float bufferDepth = SAMPLE_DEPTH_TEXTURE_LOD(_CameraDepthTexture, sampler_point_clamp, screenUV, 0);
float bufferLinear01Depth = Linear01Depth(bufferDepth, _ZBufferParams);
float3 camera2Depth = input.camera2DepthVector * bufferLinear01Depth;
float3 worldPos = _WorldSpaceCameraPos + camera2Depth;
float4 previousClipPos = mul(_PreviousViewProjectionMatrix, float4(worldPos, 1.0));
float2 previousUV = (previousClipPos / previousClipPos.w).xy * 0.5 + 0.5;
float2 velocity = (screenUV - previousUV) * _VelocityMotionBlurConfig.x;
float4 color = GetSource(screenUV);
int sampleCount = _VelocityMotionBlurConfig.y;
for (int i = 0; i < sampleCount; ++i)
{
screenUV += velocity;
color += GetSource(screenUV);
}
color /= (sampleCount + 1);
return float4(color.rgb, 1.0);
}动态物体
上面的方法,只能解决静态场景,动态相机的问题,因为我们重投影时只考虑了VP矩阵,这很高效,因为VP矩阵是帧共用的。但这也导致如果物体发生了移动,通过上面的方法重投影得到的像素位置不变。而要支持动态物体,必须知道物体本身M矩阵的数据,因为只有M矩阵记录了物体的位移。而M矩阵是物体级别的,没法在后处理统一计算,只能单独用一个Pass渲染。需要将渲染的结果保存到一张速度贴图(velocity texture)中。
我们需要添加这样的一个Pass:每次渲染完成时,获取当前像素点的模型空间位置,从UnityPerDraw的CBuffer中获取当前像素上一帧的M矩阵,根据上一帧的MVP计算得到上一帧的像素空间位置,然后做差值就得到速度向量,将向量写入到速度缓存中。
参考资料:
[1]High Quality Temporal Supersampling