在PyTorch Conference 2022上,研发团队介绍了 PyTorch 2.0,并宣布稳定版本将在今年 3 月正式发布,现在 PyTorch 2.0 正式版如期而至。
GitHub地址:https://github.com/pytorch/pytorch/releases
技术交流
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
本文来自技术群粉丝分享整理,文章源码、数据、技术交流,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:pythoner666,备注:来自CSDN +备注来意
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
PyTorch 2.0 延续了之前的 eager 模式,同时从根本上改进了 PyTorch 在编译器级别的运行方式。PyTorch 2.0 能为「Dynamic Shapes」和分布式运行提供更快的性能和更好的支持。
PyTorch 2.0 的稳定功能包括 Accelerated Transformers(以前称为 Better Transformers)。Beta 功能包括:
-
使用 torch.compile 作为 PyTorch 2.0 的主要 API;
-
scaled_dot_product_attention 函数作为 torch.nn.functional 的一部分;
-
MPS 后端;
-
torch.func 模块中的 functorch API。
另外,PyTorch 2.0 还提供了一些关于 GPU 和 CPU 上推理、性能和训练的 Beta/Prototype 改进。
除了 2.0,研发团队这次还发布了 PyTorch 域库的一系列 beta 更新,包括 in-tree 的库和 TorchAudio、TorchVision、TorchText 等独立库。此外,TorchX 转向社区支持模式。
具体来说,PyTorch 2.0 的功能包括:
-
torch.compile 是 PyTorch 2.0 的主要 API,它能包装并返回编译后的模型。这个是一个完全附加(和可选)的功能,PyTorch 2.0 根据定义是 100% 向后兼容的。
-
作为 torch.compile 的基础技术,带有 Nvidia 和 AMD GPU 的 TorchInductor 将依赖 OpenAI Triton 深度学习编译器来生成高性能代码并隐藏低级硬件细节。OpenAI Triton 生成内核实现了与手写内核和 cublas 等专用 cuda 库相当的性能。
-
Accelerated Transformers 引入了对训练和推理的高性能支持,使用自定义内核架构实现缩放点积注意力 (SPDA)。API 与 torch.compile () 集成,模型开发人员也可以通过调用新的 scaled_dot_product_attention () 运算符直接使用缩放点积注意力内核。
-
Metal Performance Shaders (MPS) 后端能在 Mac 平台上提供 GPU 加速的 PyTorch 训练,并增加了对前 60 个最常用运算符的支持,覆盖 300 多个运算符。
-
Amazon AWS 优化了 AWS Graviton3 上的 PyTorch CPU 推理。与之前的版本相比,PyTorch 2.0 提高了 Graviton 的推理性能,包括针对 ResNet-50 和 BERT 的改进。
-
其他一些跨 TensorParallel、DTensor、2D parallel、TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor 的新 prototype 功能和方法。

稳定功能
PyTorch 2.0 版本包括 PyTorch Transformer API 新的高性能实现,以前称为「Better Transformer API」,现在更名为 「Accelerated PyTorch 2 Transformers」。研发团队表示他们希望整个行业都能负担得起训练和部署 SOTA Transformer 模型的成本。新版本引入了对训练和推理的高性能支持,使用自定义内核架构实现缩放点积注意力 (SPDA)。
与「快速路径(fastpath)」架构类似,自定义内核完全集成到 PyTorch Transformer API 中 —— 因此,使用 Transformer 和 MultiHeadAttention API 将使用户能够:
-
显著提升模型速度;
-
支持更多用例,包括使用交叉注意力模型、Transformer 解码器,并且可以用于训练模型;
-
继续对固定和可变的序列长度 Transformer 编码器和自注意力用例使用 fastpath 推理。
为了充分利用不同的硬件模型和 Transformer 用例,PyTorch 2.0 支持多个 SDPA 自定义内核,自定义内核选择逻辑是为给定模型和硬件类型选择最高性能的内核。除了现有的 Transformer API 之外,模型开发人员还可以通过调用新的 scaled_dot_product_attention () 运算来直接使用缩放点积注意力内核。
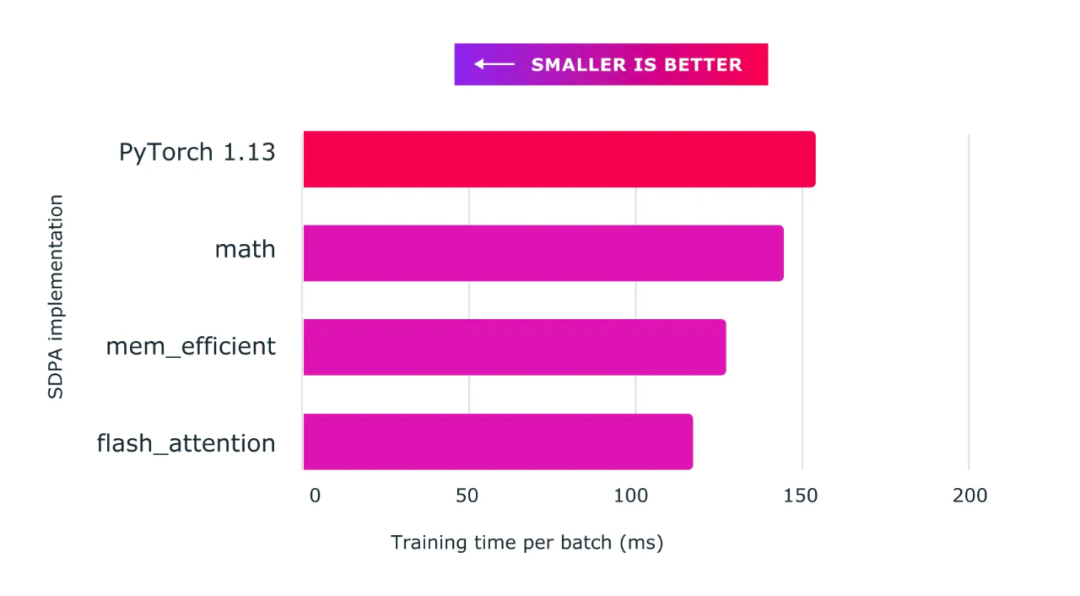
将缩放点积注意力与自定义内核和 torch.compile 结合使用可为训练大型语言模型(上图以 nanoGPT 为例)提供显著加速。
Beta 功能
torch.compile
torch.compile 是 PyTorch 2.0 的主要 API,它包装并返回编译后的模型。torch.compile 的背后是 PyTorch 团队研发的新技术 ——TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor。
借助这些新技术,torch.compile 能够在 165 个开源模型上运行,并且在 float32 精度下平均运行速度提高 20%,在 AMP 精度下平均运行速度提高 36%。
PyTorch MPS 后端
MPS 后端在 Mac 平台上提供 GPU 加速的 PyTorch 训练。PyTorch 2.0 在正确性、稳定性和运算符覆盖率方面比之前的版本有所改进。
缩放点积注意力 2.0
PyTorch 2.0 引入了一个强大的缩放点积注意力函数。该函数包括多种实现,可以根据使用的输入和硬件无缝应用。
functorch → torch.func
functorch API 现在可以在 torch.func 模块中使用。其中,函数转换 API 与以前相同,但与 NN 模块交互的方式有所改变。
此外,PyTorch 2.0 还添加了对 torch.autograd.Function 的支持:现在可以在 torch.autograd.Function 上应用函数转换。
Dispatchable Collectives
Dispatchable Collectives 是对之前 init_process_group () API 的改进,其中将后端更改为可选参数。对于用户来说,这个特性的主要优势在于,它将允许用户编写可以在 GPU 和 CPU 机器上运行的代码,而无需更改后端规范。
PyTorch 2.0 还将 torch.set_default_device 和 torch.device 作为语境管理器(context manager),将「X86」作为 x86 CPU 的新默认量化后端。
新的 X86 量化后端利用 FBGEMM 和 oneDNN 内核库,提供比原始 FBGEMM 后端更高的 INT8 推理性能。新后端在功能上与原始 FBGEMM 后端兼容。

此外,PyTorch 2.0 还包括多项关键优化,以提高 CPU 上 GNN 推理和训练的性能,并利用 oneDNN Graph 加速推理。
最后,PyTorch 2.0 还包含一些 Prototype 功能,包括:
-
[Prototype] DTensor
-
[Prototype] TensorParallel
-
[Prototype] 2D Parallel
-
[Prototype] torch.compile (dynamic=True)