PyTorch 2.0 中发布了大量足以改变 PyTorch 使用方式的新功能,它提供了相同的 eager mode 和用户体验,同时通过 torch.compile 增加了一个编译模式,在训练和推理过程中可以对模型进行加速,从而提供更佳的性能和对 Dynamic Shapes 及 Distributed 的支持。
-
PyTorch 2.0 在保留原有优势的同时,大举支持编译
-
torch.compile 为可选功能,只需一行代码即可运行编译
-
4 项重要技术:TorchDynamo、AOTAutograd、PrimTorch 以及 TorchInductor
-
PyTorch 1.x 代码无需向 2.0 迁移
1.PyTorch 2.0
- 5 年前就尝试过编译,效果一直不理想
官方正式发布了 torch.compile,它使得 PyTorch 的性能进一步提升,并开始将 PyTorch 的部分内容从 C++ 中回到 Python.
1.1 Torch Dynamo
它可以借助 Python Frame Evaluation Hooks,安全地获取 PyTorch 程序,这项重大创新是 PyTorch 过去 5 年来在安全图结构捕获 (safe graph capture) 方面的研发成果汇总.
TorchDynamo 是一个 Python 级 JIT 编译器,旨在使未经修改的 PyTorch 程序更快。 TorchDynamo 连接到 CPython (PEP 523) 中的框架评估 API,以便在执行之前动态修改 Python 字节码。
TorchDynamo:可靠快速地获取图结构
它重写 Python 字节码,以便将 PyTorch 操作序列提取到 FX 图表中,然后使用可定制的后端进行即时编译。
它通过字节码分析创建此 FX 图表,旨在将 Python 执行与编译后端混合在一起,以获得两全其美 - 可用性和性能。
TorchDynamo 可以轻松地尝试不同的编译器后端,从而使用单行装饰器 torch._dynamo.optimize() 加快 PyTorch 代码的速度,为方便起见,该装饰器由 torch.compile() 包装起来

1.2 AOTAutograd
重载 PyTorch autograd engine,作为一个 tracing autodiff,用于生成超前的 backward trace。
1.3 PrimTorch
将 2000+ PyTorch 算子归纳为约 250 个 primitive operator 闭集 (closed set),开发者可以针对这些算子构建一个完整的 PyTorch 后端。PrimTorch 大大简化了编写 PyTorch 功能或后端的流程。
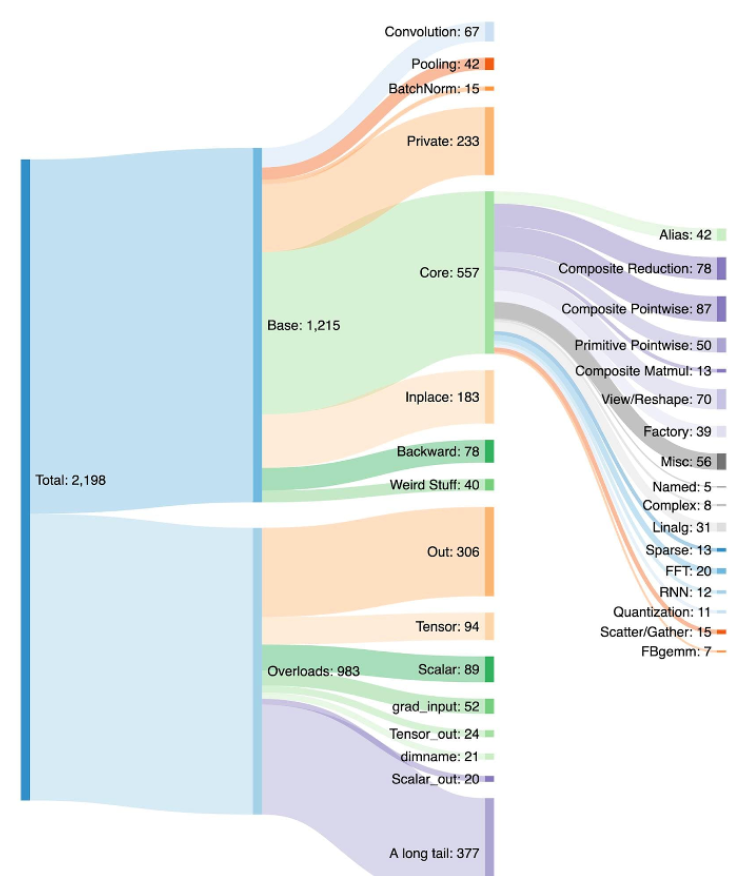
为 PyTorch 写一个后端并不容易,PyTorch 有 1200+ 算子,如果考虑到每个算子的各种重载 (overload),数量高达 2000+。
因此,编写后端或交叉功能 (cross-cutting feature) 成为一项耗费精力的工作。PrimTorch 致力于定义更小更稳定的算子集。PyTorch 程序可以持续降级 (lower) 到这些算子集。官方的目标是定义两个算子集:
-
Prim ops 包含约 250 个相对底层的算子,因为足够底层,所以这些算子更适用于编译器,开发者需要将这些算子进行融合,才能获得良好的性能。
-
ATen ops 包含约 750 个典型算子 (canonical operator),适合于直接输出。这些算子适用于已经在 ATen 级别上集成的后端,或者没有经过编译的后端,才能从底层算子集(如 Prim ops) 恢复性能。
1.4 TorchInductor
一个深度学习编译器,可以为多个加速器和后端生成 fast code。对于 NVIDIA GPU,它使用 OpenAI Triton 作为关键构建模块。
TorchInductor:用 define-by-run IR 进行更迅速的 codegen
越来越多的开发者在编写高性能自定义内核时,会使用 Triton 语言。此外,对于 PyTorch 2.0 全新的编译器后端,官方还希望能够使用与 PyTorch eager 类似的抽象,并且具有足够的通用性能支持 PyTorch 中广泛的功能。
TorchInductor 使用 Pythonic define-by-run loop level IR,自动将 PyTorch 模型映射到 GPU 上生成的 Triton 代码以及 CPU 上的 C++/OpenMP。
TorchInductor 的 core loop level IR 只包含大约 50 个算子,而且是用 Python 实现的,这使得它具有很强的 hackability 和扩展性。
TorchInductor 是 TorchDynamo Graph 支持用于 GPU 的 Triton 或用于 CPU 的 C++/OpenMP 的后端之一。
我们有一个训练性能仪表板,可以提供不同训练后端的性能比较。您可以在 PyTorch 开发讨论上的 TorchInductor 帖子中阅读更多内容。
2. 功能特点
PyTorch 的开发理念自始至终都是 flexibility 和 hackability 第一,性能则是第二,致力于:
2.1 使用灵活性
- 高性能的 eager execution
- 不断 Python 化内部结构
- Distributed, Autodiff, Data loading, Accelerators 等的良好抽象
PyTorch自2017年面世以来,硬件加速器(如GPU)的计算速度提高了约 15倍,内存访问速度提高了约 2 倍。
2.2 图结构与编译器
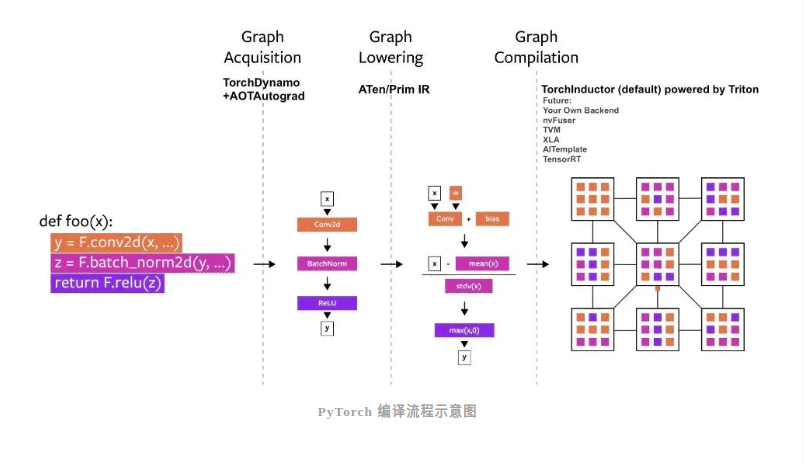
自面世以来,PyTorch 中建立过好几个编译器项目,这些编译器可以分为 3 类:
- 图结构的获取 (graph acquisition)
- 图结构的降低 (graph lowering)
- 图结构的编译 (graph compilation)
其中,图结构的获取面临的挑战最多。
过去5年中,
官方尝试了 torch.jit.trace、TorchScript、FX tracing 以及 Lazy Tensors,但它们有些够灵活但不够快,有些够快但不灵活,有些既不快也不灵活,有些用户体验不好。
虽然 TorchScript 很有前途,但它需要大量修改代码和依赖,可行性并不高。
TorchDynamo 使用了 PEP-0523 中引入的CPython 功能,称为框架评估 API (Frame Evaluation API)。官方采取了一种数据驱动的方法来验证其在 Graph Capture 上的有效性,使用 7000 多个用 PyTorch 编写的 Github 项目作为验证集。
实验表明,TorchDynamo 在 99% 的时间里都能正确、安全地获取图结构,而且开销可以忽略不计,因为它无需对原始代码做任何修改。
为了保持高性能的 eager execution,PyTorch 内部的大部分内容不得不转移到 C++ 中,这使得 PyTorch hackability 下降,也增加了开发者参与代码贡献的门槛。
从第一天起,PyTorch 官方就意识到了 eager execution 的性能局限。2017 年 7 月,官方开始致力于为 PyTorch 开发一个编译器。该编译器需要在不牺牲 PyTorch 体验的前提下,加速 PyTorch 程序的运行,其关键标准是保持某种程度上的灵活性 (flexibility):支持开发者广泛使用的 dynamic shapes 以及 dynamic programs。
3. 使用方式
TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor 是用 Python 编写的,并且支持 dynamic shape(无需重新编译就能发送不同大小的向量),这使得它们灵活且易学,降低了开发者和供应商的准入门槛。
为了验证这些技术,PyTorch 官方使用了机器学习领域的 163 个开源模型,包括图像分类、目标检测、图像生成等任务,以及各种 NLP 任务,如语言建模、问答、序列分类、推荐系统和强化学习。
3.1 Benchmark
这些 Benchmark 分为三类:
- 来自 HuggingFace Transformers 的 46 个模型
- 来自 TIMM 的 61 个模型:由 Ross Wightman 收集的 SoTA PyTorch 图像模型
- 来自 TorchBench 的 56 个模型:GitHub 上收集的一组流行代码库。
对于开源模型,PyTorch 官方没有进行修改,只是增加了一个 torch.compile 调用来进行封装。
编译模式 (compiled mode) 的性能和可扩展性在未来会不断进行丰富和提升。
3.2 混精度训练
接下来 PyTorch 工程师在这些模型中测量速度并验证精度,由于提速可能取决于数据类型,因此官方在 float32 和自动混合精度 (AMP) 上都测量了提速。由于 AMP 在实践中更常见,测试比例设定为:0.75 * AMP + 0.25 * float32 的。
在这 163 个开源模型中,torch.compile 可以在 93% 模型上正常运行,运行过后,模型在 NVIDIA A100 GPU 上的运行速度达到了 43% 的提升。在 Float32 精度下,运行速度平均提升 21%;在 AMP 精度下,运行速度平均提升 51%。
》注意:在桌面级 GPU(如 NVIDIA 3090)上,测得的速度比在服务器级 GPU(如 A100)上要低。截至目前,PyTorch 2.0 默认后端 TorchInductor 已经支持 CPU 和 NVIDIA Volta 和 Ampere GPU,暂不支持其他 GPU、xPU 或更老的 NVIDIA GPU。
3.3 兼容性
- PyTorch 2.0 的代码是否向下兼容 1.x?
是的,2.0 不要求修改 PyTorch workflow,只需一行代码 model = torch.compile(model) 即可优化模型使用 2.0 stack,并与 PyTorch 其他代码顺利运行。该选项不强制,开发者仍可使用先前的版本。
- PyTorch 2.0 是否默认启用?
不是,必须在 PyTorch 代码中明确启用 2.0,方法是通过一个单一函数调用 (single function call) 来优化模型。
- 如何将 PT1.X 代码迁移到 PT2.0?
先前的代码不需要任何迁移,如果想使用 2.0 中引入的全新的 compiled mode 功能,可以先用一行代码来优化模型:model = torch.compile(model)。
速度提升主要体现在训练过程中,如果模型运行速度快于 eager mode,则表示可以用于推理。