主要就是对下图中17个方法一个个敲一遍,自己练习
通用BaseMapper一共 1个插入方法 2个更新方法 4个删除方法 10个查询方法
这里只演示通用的BaseMapper中的17个方法
具体注解解释:https://tiantian.blog.csdn.net/article/details/129434767?spm=1001.2014.3001.5502

新建个项目
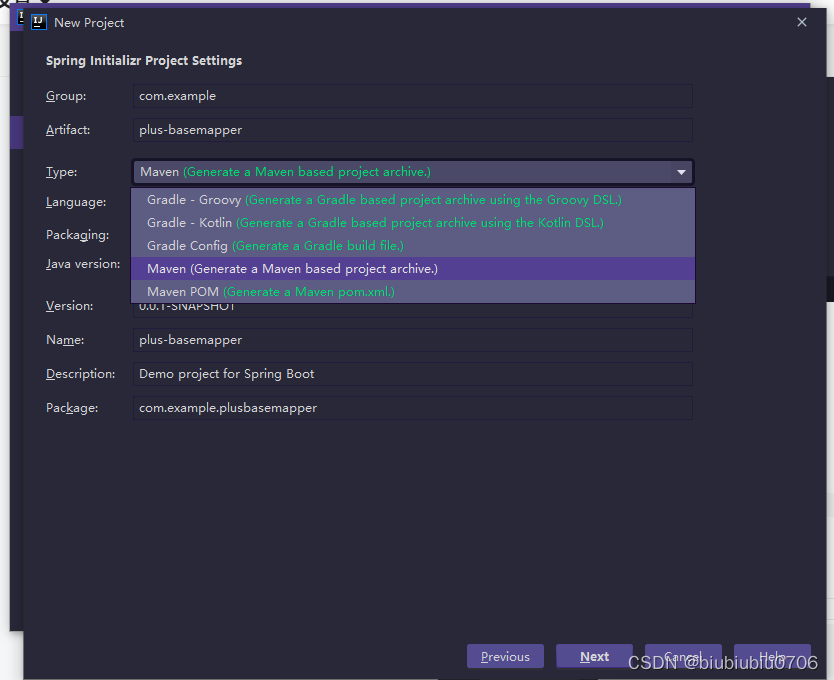
引入Spring WEB(单纯用单元测试可以不引入) devtools热部署 lombok
mysql 驱动 mybatis 到时候可以去掉缓存plus 如果想自动检查数据源配置,引入Spring data JDBC
我这也引入了


SpringBoot版本换成2.7.2 不为什么

注释掉Mybatis换成plus

mysql驱动依赖 改成下面的 默认引入的阿里云maven仓库可能还没收录

application.properties
#热部署生效
spring.devtools.restart.enabled=true
#设置重启目录
spring.devtools.restart.additional-paths=src/main/java
#排除目录
spring.devtools.restart.exclude=static/**
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/mydbabc?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
spring.datasource.username=root
spring.datasource.password=123456
#Mybatis-plus配置
#指定实体包名 单用BaseMapper里方法,不配也行
mybatis-plus.type-aliases-package=com.example.plusbasemapper.pojo
#指定.xml路径
mybatis-plus.mapper-locations=classpath:/mapper/*.xml
#开启驼峰命名 可以不配 具体看版本
mybatis-plus.configuration.map-underscore-to-camel-case=true
#mybatis配置
#mybatis.mapper-locations=classpath:/mapper/*.xml
##配置模型路径
#mybatis.type-aliases-package=com.example.plusbasemapper.pojo
##开启驼峰命名
#mybatis.configuration.map-underscore-to-camel-case=true
#Spring 框架自带的日志框架(Spring Framework Logging)
#logging.level.com.example.mybatisplus=debug
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
#http://localhost:8080/actuator/health
management.endpoint.health.show-details=always创建数据库与表

建表
CREATE TABLE `t_employee` (
`e_id` bigint(20) NOT NULL AUTO_INCREMENT,
`e_name` varchar(255) DEFAULT NULL,
`password` varchar(255) DEFAULT NULL,
`email` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`admin` bit(1) DEFAULT NULL,
`dept_id` bigint(20) DEFAULT NULL,
PRIMARY KEY (`e_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
插入数据
INSERT INTO `t_employee` VALUES (1, 'admin', '1', '[email protected]', 40, b'1', 6);
INSERT INTO `t_employee` VALUES (2, '赵总', '1', '[email protected]', 35, b'0', 1);
INSERT INTO `t_employee` VALUES (3, '赵一明', '1', '[email protected]', 25, b'0', 1);
INSERT INTO `t_employee` VALUES (4, '钱总', '1', '[email protected]', 31, b'0', 2);
INSERT INTO `t_employee` VALUES (5, '钱二明', '1', '[email protected]', 25, b'0', 2);
INSERT INTO `t_employee` VALUES (6, '孙总', '1', '[email protected]', 35, b'0', 3);
INSERT INTO `t_employee` VALUES (7, '孙三明', '1', '[email protected]', 25, b'0', 3);
INSERT INTO `t_employee` VALUES (8, '李总', '1', '[email protected]', 35, b'0', 4);
INSERT INTO `t_employee` VALUES (9, '李四明', '1', '[email protected]', 25, b'0', 4);
INSERT INTO `t_employee` VALUES (10, '周总', '1', '[email protected]', 19, b'0', 5);
INSERT INTO `t_employee` VALUES (11, '周五明', '1', '[email protected]', 25, b'0', 5);
INSERT INTO `t_employee` VALUES (12, '吴总', '1', '[email protected]', 41, b'0', 5);
INSERT INTO `t_employee` VALUES (13, '吴六明', '1', '[email protected]', 33, b'0', 5);
INSERT INTO `t_employee` VALUES (14, '郑总', '1', '[email protected]', 35, b'0', 3);
INSERT INTO `t_employee` VALUES (15, '郑七明', '1', '[email protected]', 25, b'0', 2);
表数据

启动类 添加Mapper扫描
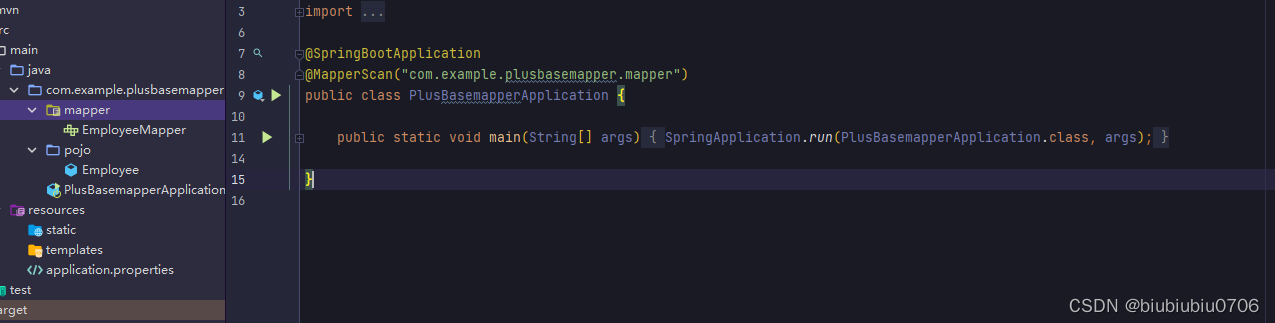
来个Mapper接口
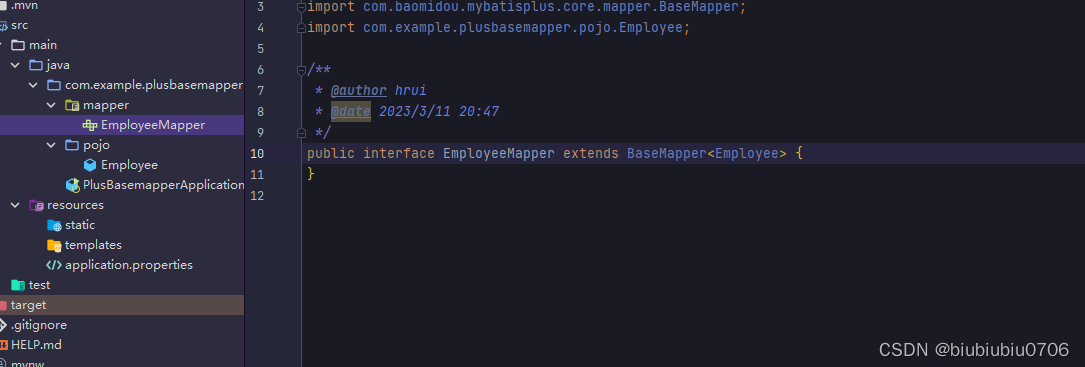
注意数据表中的dept_id 不管你配置不配置转驼峰 都要写成deptId 如果写成deptid反而会报错
除非用@TableField指明 不用怀疑 实验多次 除非是某些版本问题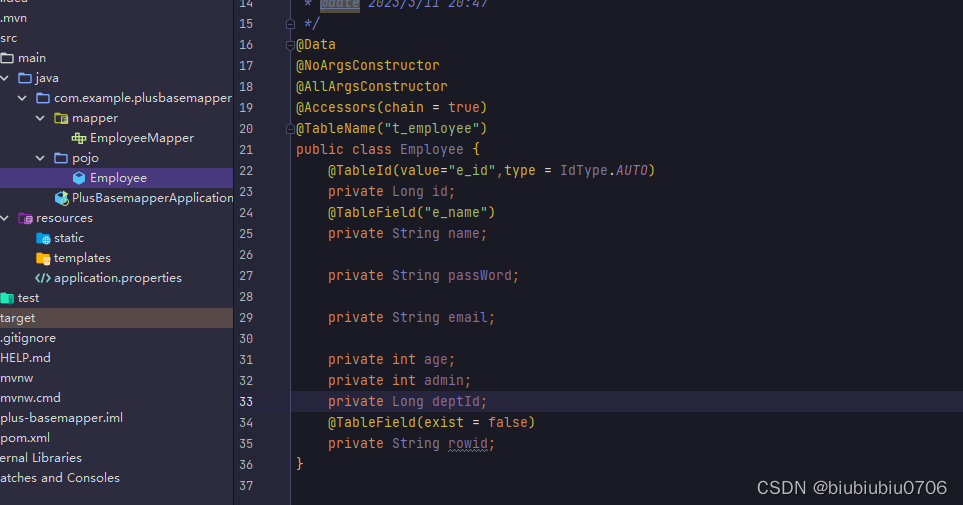

BaseMapper方法集
insert:1个 update:2个 delete:4个 select:10个

insert(XXX)方法

如果我将后面的idType去掉
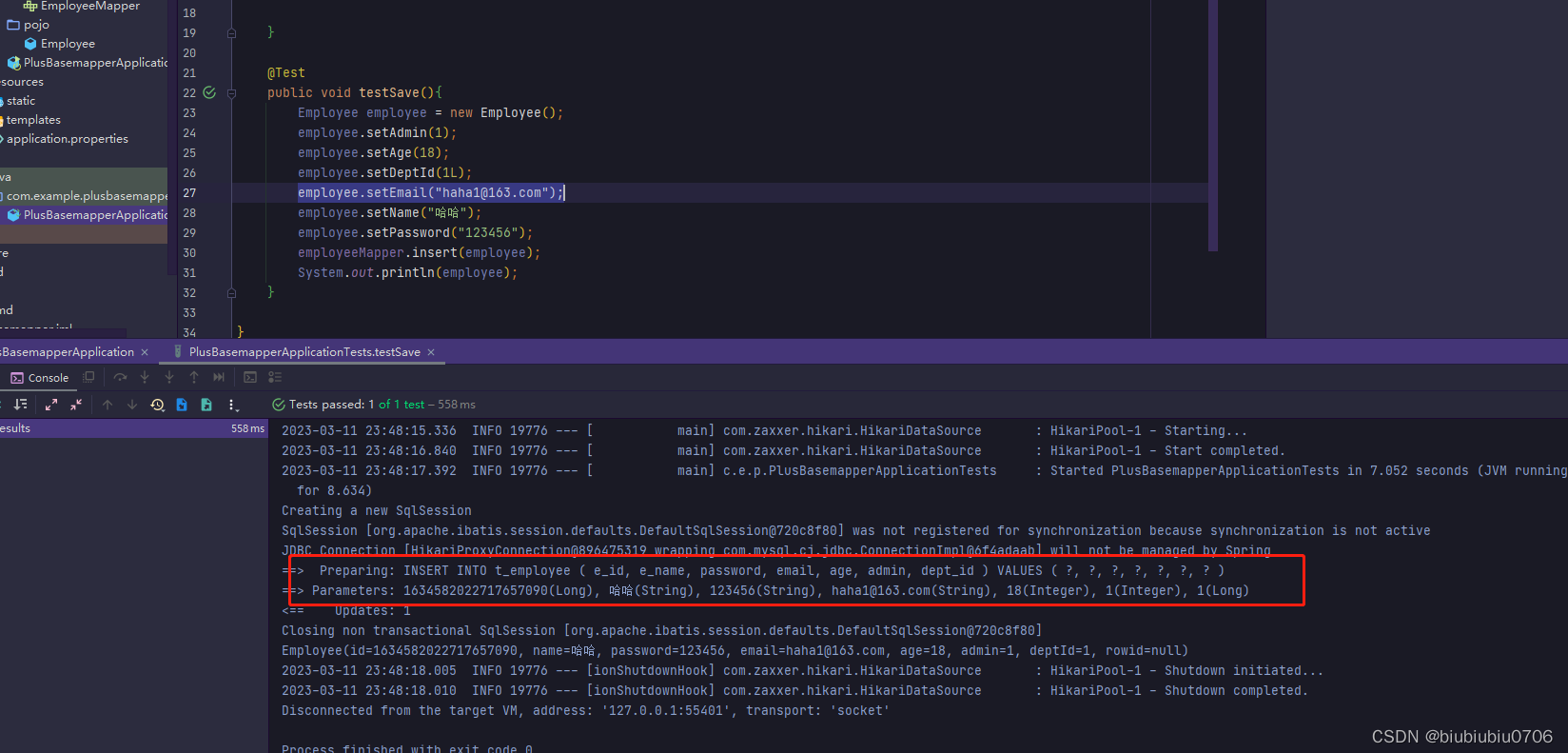
看出来区别了吗,如果没有用idType指定,默认用的雪花算法,而雪花算法是先把id计算出来,再插入的,如果指定idType是返回主键
Mybatis-plus的更新方法有两个
第一个 updateById

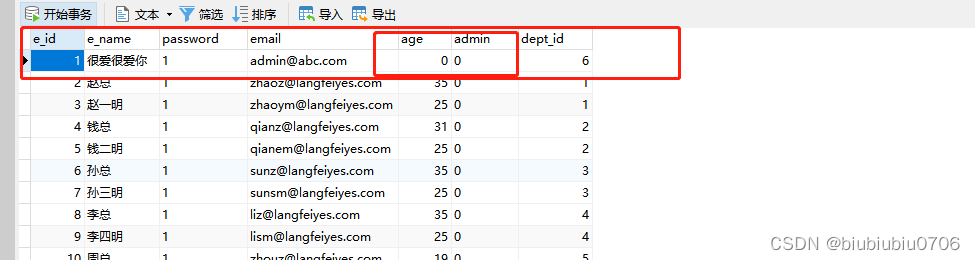

这其实也是实体类字段建议用包装类的原因
第二个更新方法
update
注意构造器传入的是数据表列名
QueryWrapper没有set方法



如果传入的不是null,用实体类对象会怎么样

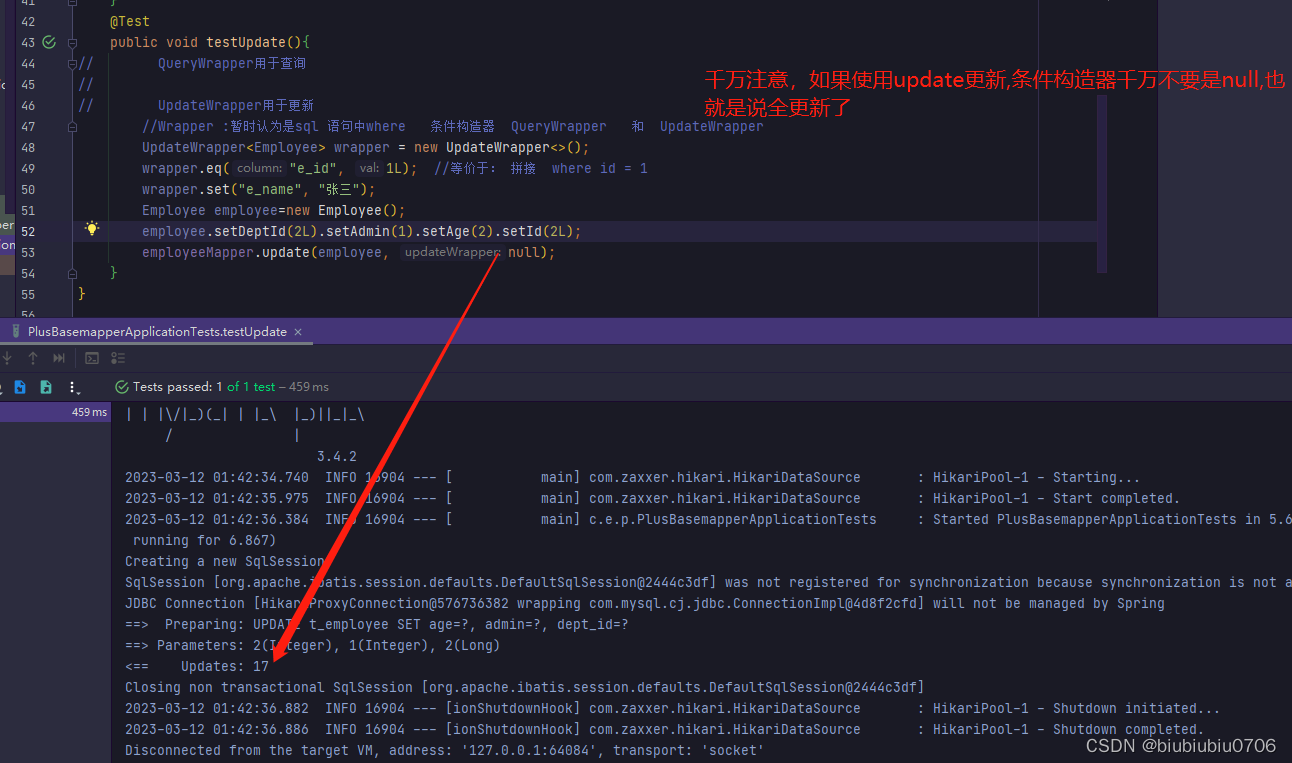
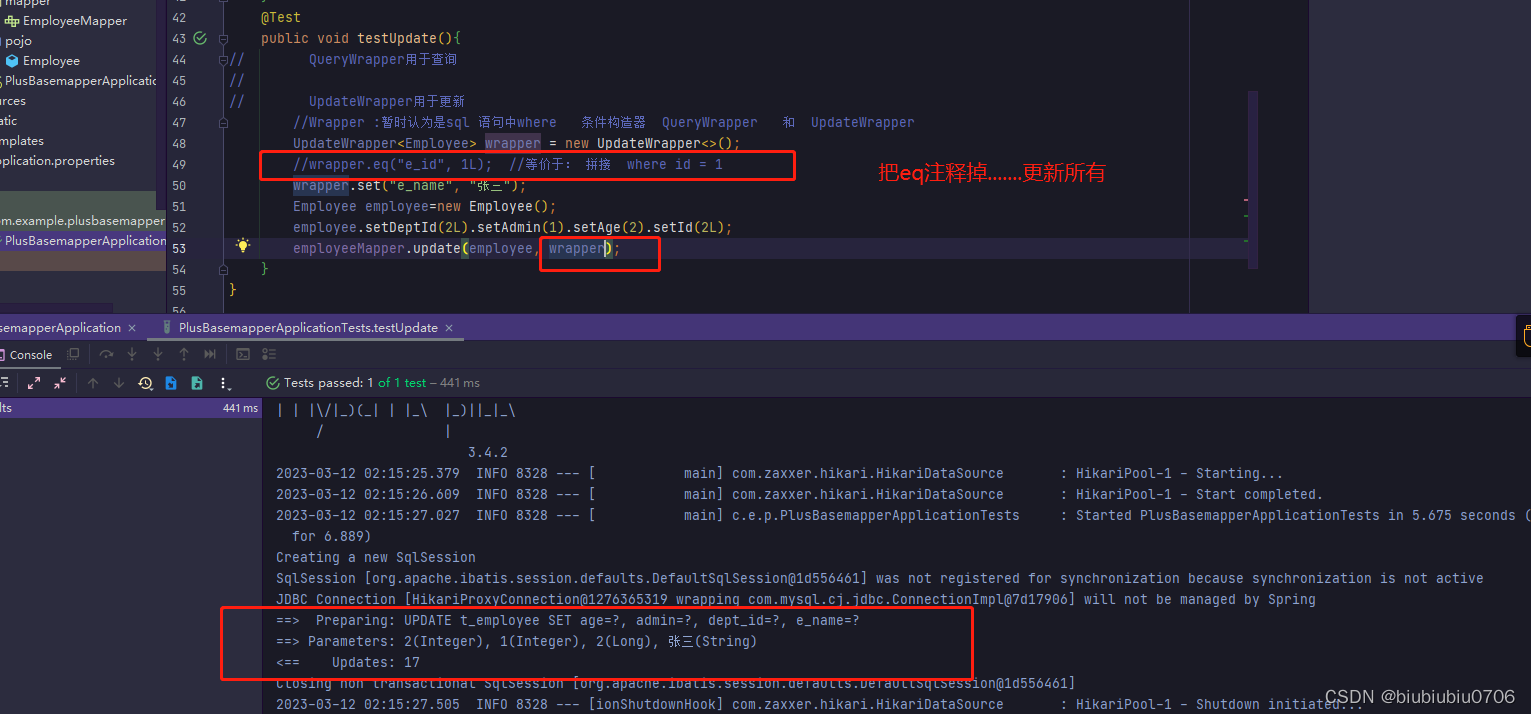

两个更新写完了,接下来 4个delete 还是先恢复下数据 清空表 重新导入下
/**
* 根据 ID 删除
*
* @param id 主键ID
*/
int deleteById(Serializable id);
/**
* 根据 columnMap 条件,删除记录
*
* @param columnMap 表字段 map 对象
*/
int deleteByMap(Map<String, Object> columnMap);
/**
* 根据 entity 条件,删除记录
*
* @param wrapper 实体对象封装操作类(可以为 null)
*/
int delete(Wrapper<T> wrapper);
/**
* 删除(根据ID 批量删除)
*
* @param idList 主键ID列表(不能为 null 以及 empty)
*/
int deleteBatchIds(Collection<? extends Serializable> idList);
第一个 int deleteById(Serializable id);

第二个
int deleteByMap(Map<String, Object> columnMap);
注意map的key是数据表的列名

第三个
deleteBatchIds
用法:批量删除指定多个id对象信息

第四个
delete
用法:按条件删除,具体条件通过条件构造器拼接
